
PARSeq:革新场景文本识别的新范式
场景文本识别(Scene Text Recognition, STR)是计算机视觉领域的一个重要任务,旨在从自然场景图像中准确识别文本内容。近年来,随着深度学习技术的发展,STR模型的性能得到了显著提升。然而,如何在提高识别准确率的同时保持较高的计算效率仍是一个挑战。最近,来自菲律宾大学的研究人员提出了一种新的STR模型——PARSeq(Permuted Autoregressive Sequence),通过巧妙的设计实现了高效和高性能的统一。
PARSeq的核心思想
PARSeq的核心思想是将现有STR解码方法统一到一个框架中。传统的STR模型通常采用以下三种解码方式之一:
- 上下文无关的非自回归(NAR)解码
- 上下文感知的自回归(AR)解码
- 双向(完形填空)细化
PARSeq的洞见在于,通过一个自回归模型的集成,可以统一这三种解码方法:

如图所示,PARSeq采用单一的Transformer架构,通过简单地改变注意力掩码,就可以实现不同的解码模式。通过正确的解码器参数化,PARSeq可以使用排列语言建模(Permutation Language Modeling)进行训练,从而使模型能够在推理时对任意输入上下文的任意输出位置进行预测。
这种"任意解码"的特性使PARSeq成为一个统一的STR模型,能够同时支持上下文无关和上下文感知的推理,以及利用双向上下文进行迭代预测细化,而无需单独的语言模型。从本质上讲,PARSeq可以被视为一个具有共享架构和权重的AR模型集成:
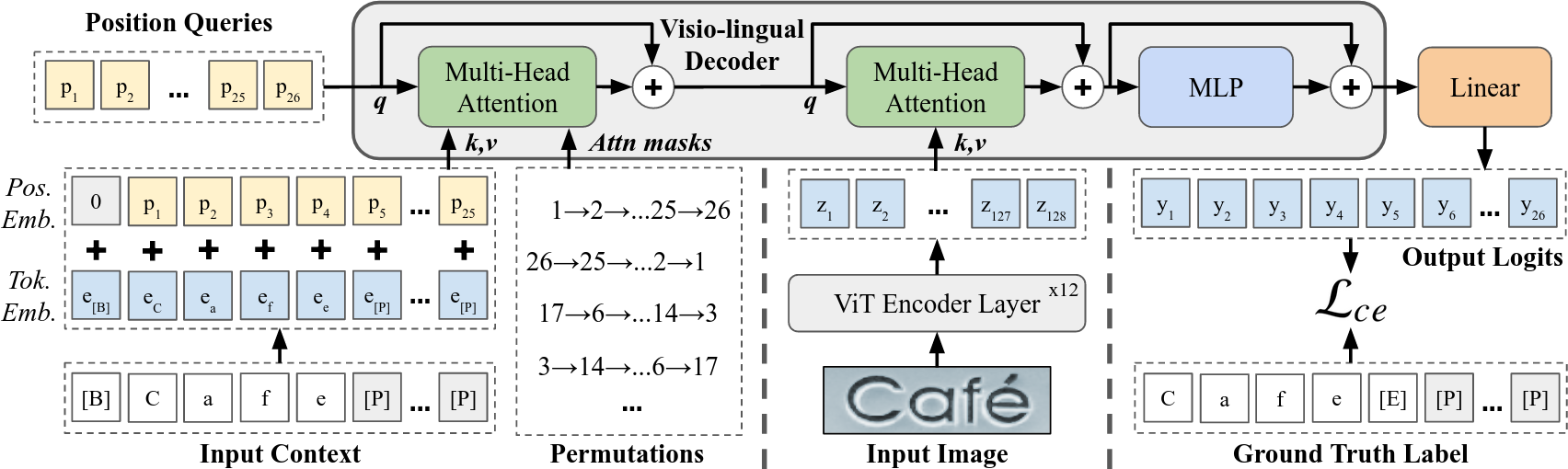
PARSeq的技术细节
PARSeq的核心组件包括:
- 编码器: 使用Vision Transformer(ViT)作为图像特征提取器。
- 解码器: 采用Transformer解码器,通过排列语言建模实现灵活的解码。
- 位置编码: 使用可学习的位置嵌入来表示序列中的位置信息。
- 注意力掩码: 根据给定的排列生成注意力掩码,用于控制上下文-位置注意力。
- 损失函数: 使用交叉熵损失进行训练。
PARSeq的训练过程采用了排列语言建模的思想。具体来说,在每次训练迭代中,模型会随机生成一个输出序列的排列,并使用这个排列来生成注意力掩码。这使得模型能够学习在任意给定的上下文条件下预测任意位置的输出。
PARSeq的性能评估
研究者在多个标准STR基准数据集上评估了PARSeq的性能,包括IIIT5k、SVT、IC13、IC15、SVTP和CUTE80等。实验结果表明,PARSeq在多个数据集上达到了最先进的性能:
| 数据集 | 样本数 | 准确率 | 1 - NED | 置信度 | 标签长度 |
|---|---|---|---|---|---|
| IIIT5k | 3000 | 99.00 | 99.79 | 97.09 | 5.09 |
| SVT | 647 | 97.84 | 99.54 | 95.87 | 5.86 |
| IC13 | 1015 | 98.13 | 99.43 | 97.19 | 5.31 |
| IC15 | 2077 | 89.22 | 96.43 | 91.91 | 5.33 |
| SVTP | 645 | 96.90 | 99.36 | 94.37 | 5.86 |
| CUTE80 | 288 | 98.61 | 99.80 | 96.43 | 5.53 |
| 总体 | 7672 | 95.95 | 98.78 | 95.34 | 5.33 |
这些结果显示,PARSeq在各种场景和字符集下都表现出色,包括常规文本、弯曲文本和小型文本等challenging场景。
PARSeq的计算效率
除了高准确率,PARSeq还展现出优秀的计算效率。研究者进行了详细的计算需求分析,结果显示PARSeq在保持高性能的同时,比许多现有模型更加高效:
- 参数量: 23.833M
- 浮点运算次数(FLOPs): 3.255G
- 激活量: 8.214M
在标准硬件上,PARSeq的中位推理时间仅为14.87毫秒,这意味着它能够实现接近实时的文本识别。
PARSeq的实际应用
PARSeq不仅在学术基准上表现出色,还展示了强大的实际应用潜力。研究者提供了一个简单的demo脚本,展示了如何使用训练好的PARSeq模型来识别图像中的文本:
./read.py pretrained=parseq --images demo_images/*
Additional keyword arguments: {}
demo_images/art-01107.jpg: CHEWBACCA
demo_images/coco-1166773.jpg: Chevrol
demo_images/cute-184.jpg: SALMON
demo_images/ic13_word_256.png: Verbandsteffe
demo_images/ic15_word_26.png: Kaopa
demo_images/uber-27491.jpg: 3rdAve
这个示例展示了PARSeq在各种实际场景中的识别能力,包括艺术字体、商标、街道标志等。
PARSeq的开源与社区影响
PARSeq项目已在GitHub上开源(https://github.com/baudm/parseq),获得了广泛关注,目前已有超过500颗星。研究者提供了详细的文档,包括安装说明、训练脚本、评估方法等,方便其他研究者复现结果和进行进一步的研究。
此外,PARSeq已被集成到多个流行的OCR工具包中,如PaddleOCR和docTR,这进一步证明了其在实际应用中的价值。研究者还提供了一个在线的Gradio demo,允许用户上传图像并实时体验PARSeq的文本识别能力。
结论与未来展望
PARSeq为场景文本识别领域带来了新的范式,通过巧妙的设计实现了高效和高性能的统一。它不仅在学术基准上取得了最先进的结果,还展示了强大的实际应用潜力。未来的研究方向可能包括:
- 进一步提高模型在极具挑战性场景(如严重扭曲或模糊的文本)下的表现。
- 探索将PARSeq与端到端OCR系统结合,实现从检测到识别的一体化解决方案。
- 研究PARSeq在多语言场景下的性能,特别是对于非拉丁字符的识别能力。
- 优化模型结构和训练策略,进一步提高计算效率,使其更适合移动设备等资源受限的环境。
总的来说,PARSeq为场景文本识别领域带来了新的可能性,有望推动这一领域向更高效、更准确的方向发展。随着开源社区的持续贡献和改进,我们可以期待看到PARSeq在更多实际应用中发挥重要作用,为计算机视觉和人工智能的进步做出贡献。











