
RETRO-pytorch简介
RETRO(Retrieval-Enhanced Transformer)是DeepMind在2021年提出的一种基于检索的注意力网络模型。它通过在生成过程中检索和利用相关的文本片段,显著提高了模型的性能,同时减少了所需的参数数量。RETRO-pytorch是该模型在PyTorch深度学习框架中的开源实现。
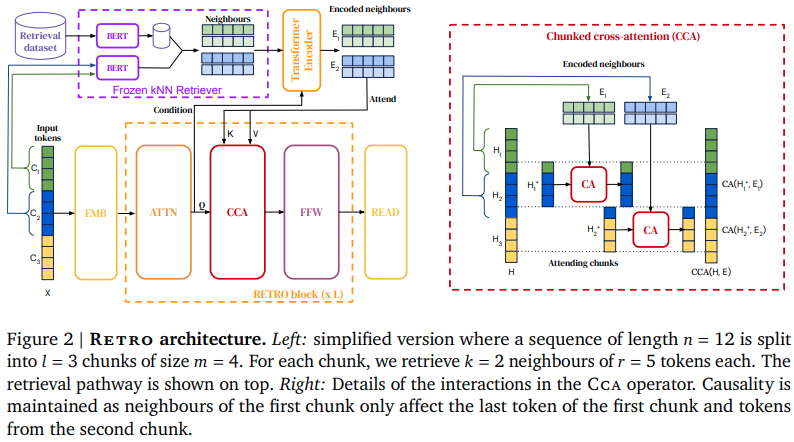
RETRO-pytorch的主要特点包括:
- 使用检索机制增强变压器模型的生成能力
- 相比GPT-3,可以用10倍少的参数达到相似的性能
- 使用旋转位置编码代替相对位置编码
- 采用Faiss库进行最近邻检索,而非原论文中的Scann
- 支持扩展到1000层的深度网络结构
RETRO-pytorch的工作原理
RETRO-pytorch的核心思想是在生成过程中引入检索机制。具体来说:
- 将输入文本分割成固定大小的块(chunk)
- 对每个块进行编码,并在预先建立的大规模文本数据库中检索最相似的k个邻近块
- 将检索到的相关块作为额外的上下文信息,输入到decoder中
- decoder在生成每个token时,不仅关注输入序列,还会通过cross-attention机制关注检索到的相关块
- 这种方式使模型能够利用检索到的信息来增强生成能力
RETRO-pytorch使用BERT的tokenizer对文本进行分词,并用BERT提取文本块的表示。检索过程则是通过Faiss库高效实现的。
安装和基本使用
RETRO-pytorch可以通过pip轻松安装:
pip install retro-pytorch
以下是一个基本的使用示例:
import torch
from retro_pytorch import RETRO
retro = RETRO(
chunk_size = 64,
max_seq_len = 2048,
enc_dim = 896,
enc_depth = 2,
dec_dim = 796,
dec_depth = 12,
dec_cross_attn_layers = (3, 6, 9, 12),
heads = 8,
dim_head = 64,
dec_attn_dropout = 0.25,
dec_ff_dropout = 0.25,
use_deepnet = True
)
seq = torch.randint(0, 20000, (2, 2048 + 1))
retrieved = torch.randint(0, 20000, (2, 32, 2, 128))
loss = retro(seq, retrieved, return_loss = True)
loss.backward()
在这个例子中,我们初始化了一个RETRO模型,并用随机生成的序列和检索结果进行了一次前向传播和反向传播。
训练和数据处理
RETRO-pytorch提供了TrainingWrapper类来简化训练过程。它可以处理文本文件夹,生成必要的内存映射数组,并准备训练数据。以下是使用TrainingWrapper的示例:
from retro_pytorch import RETRO, TrainingWrapper
retro = RETRO(
max_seq_len = 2048,
enc_dim = 896,
enc_depth = 3,
dec_dim = 768,
dec_depth = 12,
dec_cross_attn_layers = (1, 3, 6, 9),
heads = 8,
dim_head = 64,
dec_attn_dropout = 0.25,
dec_ff_dropout = 0.25
).cuda()
wrapper = TrainingWrapper(
retro = retro,
knn = 2,
chunk_size = 64,
documents_path = './text_folder',
glob = '**/*.txt',
chunks_memmap_path = './train.chunks.dat',
seqs_memmap_path = './train.seq.dat',
doc_ids_memmap_path = './train.doc_ids.dat',
max_chunks = 1_000_000,
max_seqs = 100_000,
knn_extra_neighbors = 100,
max_index_memory_usage = '100m',
current_memory_available = '1G'
)
train_dl = iter(wrapper.get_dataloader(batch_size = 2, shuffle = True))
optim = wrapper.get_optimizer(lr = 3e-4, wd = 0.01)
# 训练循环
for seq, retrieved in train_dl:
seq, retrieved = map(lambda t: t.cuda(), (seq, retrieved))
loss = retro(seq, retrieved, return_loss = True)
loss.backward()
optim.step()
optim.zero_grad()
这个例子展示了如何使用TrainingWrapper来处理数据、创建数据加载器和优化器,并进行训练。
检索相关工具
RETRO-pytorch还提供了一些用于处理检索任务的工具函数:
bert_embed和tokenize函数用于文本编码text_folder_to_chunks_函数用于将文本文件夹转换为数据块chunks_to_index_and_embed函数用于创建Faiss索引chunks_to_precalculated_knn_函数用于预计算最近邻
这些工具使得构建检索系统变得更加简单。
结论
RETRO-pytorch为研究人员和开发者提供了一个强大的工具,用于探索和实现基于检索的语言模型。它不仅实现了原始RETRO论文的核心思想,还引入了一些改进,如旋转位置编码和DeepNet技术,使模型能够扩展到更深的网络结构。
通过结合检索和生成,RETRO-pytorch展示了一种有前景的方向,可能在未来的大规模语言模型中发挥重要作用。随着进一步的研究和优化,这种方法有望在各种自然语言处理任务中取得更好的性能。
对于那些对最新的语言模型技术感兴趣的研究者和工程师来说,RETRO-pytorch无疑是一个值得关注和尝试的项目。它不仅提供了模型的核心实现,还包含了完整的数据处理和训练管道,大大降低了使用门槛。
未来,我们可以期待看到更多基于RETRO思想的创新,以及它在各种实际应用中的表现。无论是在文本生成、问答系统,还是其他需要大规模知识检索的任务中,RETRO-pytorch都有可能带来显著的性能提升。









