
 访问官网
访问官网 Github
Github 论文
论文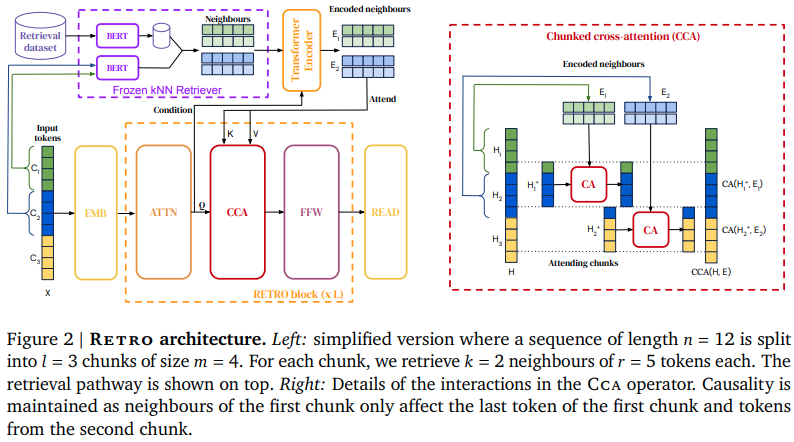
RETRO - Pytorch
在Pytorch中实现RETRO,Deepmind基于检索的注意力网络。这个实现与论文略有不同,使用旋转嵌入作为相对位置编码,并使用Faiss库而非Scann。
该库利用autofaiss构建索引并计算所有块的k近邻。
这种检索方法的亮点是以10倍少的参数达到GPT-3的性能。这个领域肯定值得更多研究。
我还包含了将检索变换器扩展到1000层所需的功能,如果DeepNet论文的说法可信的话。
更新:Reddit上有人赠送了我一个金奖。虽然不太清楚是什么,但还是非常感谢!🙏
更新:Deepnorm已在清华大学的130B模型中得到大规模验证。现在建议将use_deepnet设置为True进行训练。
安装
$ pip install retro-pytorch
使用方法
import torch
from retro_pytorch import RETRO
retro = RETRO(
chunk_size = 64, # 索引和检索的块大小(用于正确的相对位置以及因果分块交叉注意力)
max_seq_len = 2048, # 最大序列长度
enc_dim = 896, # 编码器模型维度
enc_depth = 2, # 编码器深度
dec_dim = 796, # 解码器模型维度
dec_depth = 12, # 解码器深度
dec_cross_attn_layers = (3, 6, 9, 12), # 解码器交叉注意力层(带有因果分块交叉注意力)
heads = 8, # 注意力头数
dim_head = 64, # 每个头的维度
dec_attn_dropout = 0.25, # 解码器注意力dropout
dec_ff_dropout = 0.25, # 解码器前馈dropout
use_deepnet = True # 启用DeepNet残差缩放和初始化的后归一化,用于扩展到1000层
)
seq = torch.randint(0, 20000, (2, 2048 + 1)) # 加1是因为它被分为输入和标签用于训练
retrieved = torch.randint(0, 20000, (2, 32, 2, 128)) # 检索的token - (批次, 块数, 检索到的邻居数, 检索到的块及其延续)
loss = retro(seq, retrieved, return_loss = True)
loss.backward()
# 重复上述步骤多次
RETRO训练包装器
TrainingWrapper的目标是将文本文档文件夹处理成必要的内存映射numpy数组,以开始训练RETRO。
import torch
from retro_pytorch import RETRO, TrainingWrapper
# 实例化RETRO,将其与正确的设置放入TrainingWrapper
retro = RETRO(
max_seq_len = 2048, # 最大序列长度
enc_dim = 896, # 编码器模型维度
enc_depth = 3, # 编码器深度
dec_dim = 768, # 解码器模型维度
dec_depth = 12, # 解码器深度
dec_cross_attn_layers = (1, 3, 6, 9), # 解码器交叉注意力层(带有因果分块交叉注意力)
heads = 8, # 注意力头数
dim_head = 64, # 每个头的维度
dec_attn_dropout = 0.25, # 解码器注意力dropout
dec_ff_dropout = 0.25 # 解码器前馈dropout
).cuda()
wrapper = TrainingWrapper(
retro = retro, # RETRO实例路径
knn = 2, # knn(论文中2就足够)
chunk_size = 64, # 块大小(论文中为64)
documents_path = './text_folder', # 文本文件夹路径
glob = '**/*.txt', # 文本glob
chunks_memmap_path = './train.chunks.dat', # 块的路径
seqs_memmap_path = './train.seq.dat', # 序列数据的路径
doc_ids_memmap_path = './train.doc_ids.dat', # 每个块的文档ID路径(用于过滤属于同一文档的邻居)
max_chunks = 1_000_000, # 块的最大上限
max_seqs = 100_000, # 最大序列数
knn_extra_neighbors = 100, # 额外获取的邻居数
max_index_memory_usage = '100m',
current_memory_available = '1G'
)
# 获取数据加载器和优化器(AdamW,带有所有正确的设置)
train_dl = iter(wrapper.get_dataloader(batch_size = 2, shuffle = True))
optim = wrapper.get_optimizer(lr = 3e-4, wd = 0.01)
# 现在开始训练
# 例如,一个梯度步骤
seq, retrieved = map(lambda t: t.cuda(), next(train_dl))
# seq - (2, 2049) - 由于通过seq[:, :-1], seq[:, 1:]分割,多出1个额外token
# retrieved - (2, 32, 2, 128) - 128是因为chunk + continuation,每个64个token
loss = retro(
seq,
retrieved,
return_loss = True
)
# 一次梯度步骤
loss.backward()
optim.step()
optim.zero_grad()
# 重复上述步骤多次,然后...
# 在chunk边界进行retrieval的topk采样
sampled = wrapper.generate(filter_thres = 0.9, temperature = 1.0) # (1, <2049) 如果全是<eos>则提前终止
# 或者你可以使用提示进行生成,初始chunks的knn检索会自动处理
prompt = torch.randint(0, 1000, (1, 128)) # 从两个chunks长度的序列开始
sampled = wrapper.generate(prompt, filter_thres = 0.9, temperature = 1.0) # (1, <2049) 如果全是<eos>则提前终止
如果你希望强制重新处理训练数据,只需使用REPROCESS=1环境标志运行你的脚本,如下所示
$ REPROCESS=1 python train.py
RETRO 数据集
RETRODataset类接受多个内存映射numpy数组的路径,这些数组包含chunks、要训练的序列中第一个chunk的索引(在RETRO解码器中),以及每个chunk预先计算的k个最近邻的索引。
如果你不想使用上面的TrainingWrapper,你可以用这个方法轻松组装RETRO训练所需的数据。
此外,创建必要的内存映射数据所需的所有函数都在接下来的部分中。
import torch
from torch.utils.data import DataLoader
from retro_pytorch import RETRO, RETRODataset
# 模拟数据常量
import numpy as np
NUM_CHUNKS = 1000
CHUNK_SIZE = 64
NUM_SEQS = 100
NUM_NEIGHBORS = 2
def save_memmap(path, tensor):
f = np.memmap(path, dtype = tensor.dtype, mode = 'w+', shape = tensor.shape)
f[:] = tensor
del f
# 生成模拟chunk数据
save_memmap(
'./train.chunks.dat',
np.int32(np.random.randint(0, 8192, size = (NUM_CHUNKS, CHUNK_SIZE + 1)))
)
# 为每个chunk生成最近邻
save_memmap(
'./train.chunks.knn.dat',
np.int32(np.random.randint(0, 1000, size = (NUM_CHUNKS, NUM_NEIGHBORS)))
)
# 生成seq数据
save_memmap(
'./train.seq.dat',
np.int32(np.random.randint(0, 128, size = (NUM_SEQS,)))
)
# 实例化数据集类
# 该类从内存映射的chunk和邻居信息构建序列和邻居
train_ds = RETRODataset(
num_sequences = NUM_SEQS,
num_chunks = NUM_CHUNKS,
num_neighbors = NUM_NEIGHBORS,
chunk_size = CHUNK_SIZE,
seq_len = 2048,
chunk_memmap_path = './train.chunks.dat',
chunk_nn_memmap_path = './train.chunks.knn.dat',
seq_memmap_path = './train.seq.dat'
)
train_dl = iter(DataLoader(train_ds, batch_size = 2))
# 一次前向和后向传播
retro = RETRO(
max_seq_len = 2048, # 最大序列长度
enc_dim = 896, # 编码器模型维度
enc_depth = 3, # 编码器深度
dec_dim = 768, # 解码器模型维度
dec_depth = 12, # 解码器深度
dec_cross_attn_layers = (1, 3, 6, 9), # 解码器交叉注意力层(带有因果chunk交叉注意力)
heads = 8, # 注意力头数
dim_head = 64, # 每个头的维度
dec_attn_dropout = 0.25, # 解码器注意力dropout
dec_ff_dropout = 0.25 # 解码器前馈dropout
).cuda()
seq, retrieved = map(lambda t: t.cuda(), next(train_dl))
# seq - (2, 2049) - 由于通过seq[:, :-1], seq[:, 1:]分割,多出1个token
# retrieved - (2, 32, 2, 128) - 128是因为chunk + continuation,每个64个token
loss = retro(
seq,
retrieved,
return_loss = True
)
loss.backward()
检索相关工具
本仓库将使用BERT大写版本的默认分词器(sentencepiece)。嵌入将从原始BERT获取,可以是masked mean pooled表示,也可以是CLS token。
例如:masked mean pooled表示
from retro_pytorch.retrieval import bert_embed, tokenize
ids = tokenize([
'hello world',
'foo bar'
])
embeds = bert_embed(ids) # (2, 768) - 768是BERT的隐藏维度
例如:CLS token表示
from retro_pytorch.retrieval import bert_embed, tokenize
ids = tokenize([
'hello world',
'foo bar'
])
embeds = bert_embed(ids, return_cls_repr = True) # (2, 768)
使用text_folder_to_chunks_创建你的chunks和chunk起始索引(用于计算自回归训练的序列范围)
from retro_pytorch.retrieval import text_folder_to_chunks_
stats = text_folder_to_chunks_(
folder = './text_folder',
glob = '**/*.txt',
chunks_memmap_path = './train.chunks.dat',
seqs_memmap_path = './train.seq.dat',
doc_ids_memmap_path = './train.doc_ids.dat', # 文档ID需要用于适当地在计算最近邻时过滤掉属于同一文档的邻居
chunk_size = 64,
seq_len = 2048,
max_chunks = 1_000_000,
max_seqs = 100_000
)
# {'chunks': <块数>, 'docs': <文档数>, 'seqs': <序列数>}
获取最近邻
你可以用一条命令将内存映射的块numpy数组转换为嵌入和faiss索引
from retro_pytorch.retrieval import chunks_to_index_and_embed
index, embeddings = chunks_to_index_and_embed(
num_chunks = 1000,
chunk_size = 64,
chunk_memmap_path = './train.chunks.dat'
)
query_vector = embeddings[:1] # 使用第一个嵌入作为查询
_, indices = index.search(query_vector, k = 2) # 获取2个邻居,第一个索引应该是自身
neighbor_embeddings = embeddings[indices] # (1, 2, 768)
你也可以直接使用chunks_to_precalculated_knn_命令计算训练所需的最近邻文件
from retro_pytorch.retrieval import chunks_to_precalculated_knn_
chunks_to_precalculated_knn_(
num_chunks = 1000,
chunk_size = 64,
chunk_memmap_path = './train.chunks.dat', # 主要块数据集的路径
doc_ids_memmap_path = './train.doc_ids.dat', # 由text_folder_to_chunks_创建的文档ID路径,用于过滤掉属于同一文档的邻居
num_nearest_neighbors = 2, # 你想使用的最近邻数量
num_extra_neighbors = 10 # 获取10个额外的邻居,以防获取的邻居经常来自同一文档(被过滤掉)
)
# 最近邻信息保存到 ./train.chunks.knn.dat
引用
@misc{borgeaud2022improving,
title = {通过从数万亿个标记中检索来改进语言模型},
author = {Sebastian Borgeaud and Arthur Mensch and Jordan Hoffmann and Trevor Cai and Eliza Rutherford and Katie Millican and George van den Driessche and Jean-Baptiste Lespiau and Bogdan Damoc and Aidan Clark and Diego de Las Casas and Aurelia Guy and Jacob Menick and Roman Ring and Tom Hennigan and Saffron Huang and Loren Maggiore and Chris Jones and Albin Cassirer and Andy Brock and Michela Paganini and Geoffrey Irving and Oriol Vinyals and Simon Osindero and Karen Simonyan and Jack W. Rae and Erich Elsen and Laurent Sifre},
year = {2022},
eprint = {2112.04426},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
@misc{su2021roformer,
title = {RoFormer:具有旋转位置嵌入的增强型Transformer},
author = {Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu},
year = {2021},
eprint = {2104.09864},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
@article{Wang2022DeepNetST,
title = {DeepNet:扩展Transformer至1,000层},
author = {Hongyu Wang and Shuming Ma and Li Dong and Shaohan Huang and Dongdong Zhang and Furu Wei},
journal = {ArXiv},
year = {2022},
volume = {abs/2203.00555}
}
@misc{zhang2021sparse,
title = {具有线性单元的稀疏注意力},
author = {Biao Zhang and Ivan Titov and Rico Sennrich},
year = {2021},
eprint = {2104.07012},
archivePrefix = {arXiv},
primaryClass = {cs.CL}
}
我始终认为成年生活是对童年的不断检索。 - 翁贝托·埃科











