
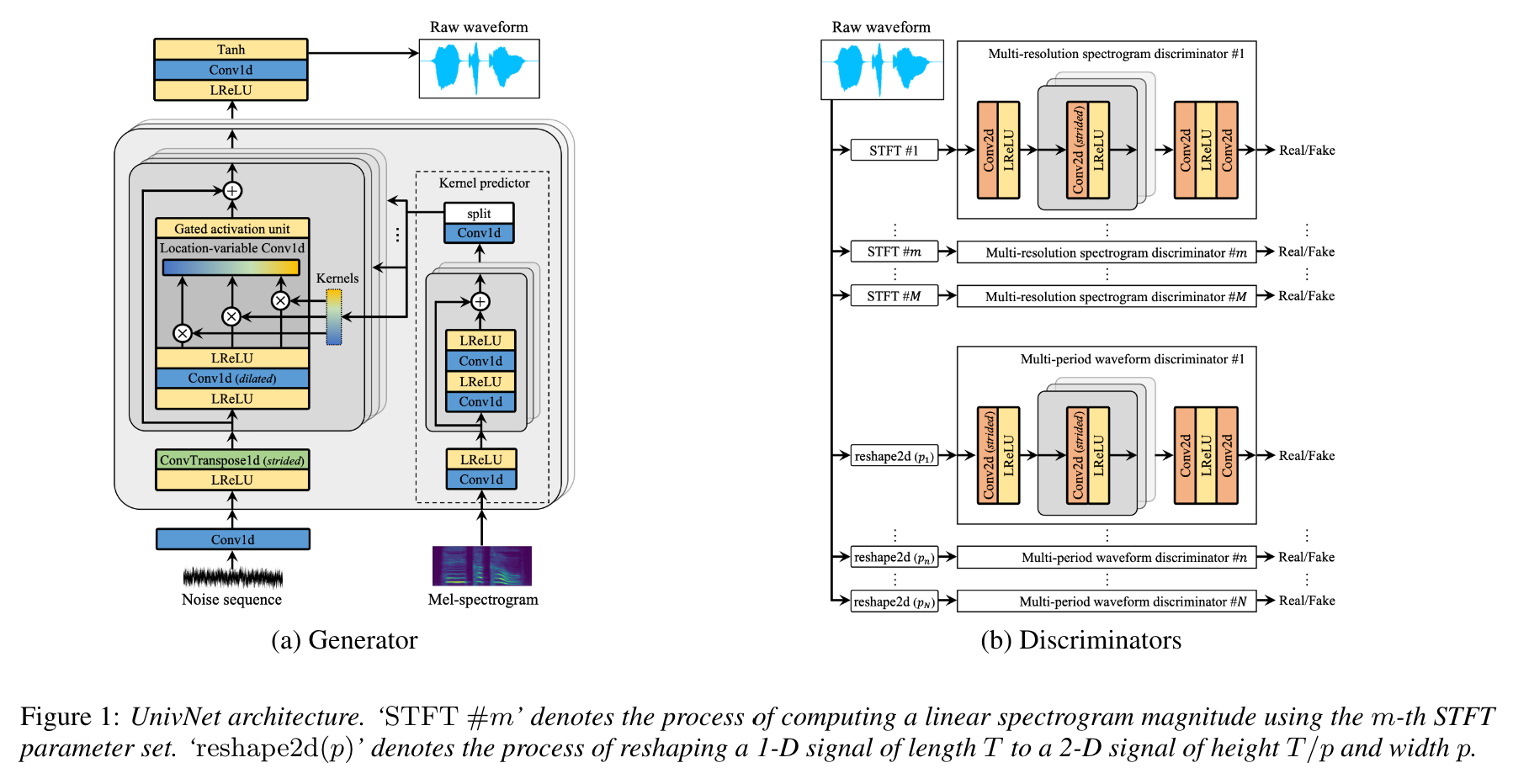
UnivNet简介
UnivNet是由Kakao公司的Jang等人提出的一种神经声码器,用于从mel频谱图生成高保真的语音波形。它的主要特点是采用了多分辨率频谱图判别器,能够生成更高质量的语音。
代码实现
目前有两个主要的UnivNet PyTorch实现:
-
maum-ai/univnet: 非官方实现,但效果与原论文相当
-
rishikksh20/UnivNet-pytorch: 另一个非官方实现
maum-ai/univnet实现特点
- 与原论文的客观指标(PESQ和RMSE)相匹配
- 提供了UnivNet-c16和c32两个版本的预训练模型
- 使用与HiFi-GAN相同的mel频谱图计算方法,与NVIDIA/tacotron2兼容
- 提供了详细的数据准备、训练和推理说明
预训练模型
maum-ai/univnet提供了在LibriTTS train-clean-360数据集上训练的预训练模型:
音频样本
可以在这个页面听取UnivNet生成的音频样本。
实验结果
在LibriTTS验证集上的评估结果:
| 模型 | PESQ(↑) | RMSE(↓) | 模型大小 |
|---|---|---|---|
| HiFi-GAN v1 | 3.54 | 0.423 | 14.01M |
| 官方 UnivNet-c16 | 3.59 | 0.337 | 4.00M |
| maum-ai UnivNet-c16 | 3.60 | 0.317 | 4.00M |
| 官方 UnivNet-c32 | 3.70 | 0.316 | 14.86M |
| maum-ai UnivNet-c32 | 3.68 | 0.304 | 14.87M |
可以看出,maum-ai的实现在客观指标上与官方结果相当甚至更好。
使用指南
环境配置
需要的主要依赖:
- Python 3.6
- PyTorch 1.6.0
- NumPy 1.17.4
- SciPy 1.5.4
安装其他依赖:
pip install -r requirements.txt
数据准备
- 下载LibriTTS train-clean-360数据集
- 解压到
datasets/LibriTTS/train-clean-360目录 - 准备元数据文件,格式为:
path_to_wav|transcript|speaker_id
训练
-
配置文件:
cp config/default_c32.yaml config/config.yaml -
修改
config.yaml中的数据路径等参数 -
运行训练:
python trainer.py -c config/config.yaml -n experiment_name
推理
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATH
参考资料
希望这个学习资料汇总能帮助大家快速入门UnivNet,有任何问题欢迎讨论交流!












