
VisualRWKV: 视觉与语言的创新融合
在人工智能领域,视觉语言模型(Visual Language Models, VLMs)的发展日新月异。然而,将高效的线性循环神经网络(RNNs)架构融入VLMs的尝试却相对较少。本文将为您详细介绍VisualRWKV,这是一个基于RWKV语言模型的创新视觉语言模型,它成功地将线性RNN模型应用于多模态学习任务。
VisualRWKV的诞生与发展
VisualRWKV是由研究人员Haowen Hou、Peigen Zeng、Fei Ma和Fei Richard Yu共同开发的项目。该项目的目标是将RWKV(Receptance Weighted Key Value)语言模型的强大能力扩展到视觉领域,使其能够处理各种视觉任务。

自项目启动以来,VisualRWKV经历了多个版本的迭代:
- 2024年3月25日: VisualRWKV-5.0正式发布
- 2024年5月11日: VisualRWKV-6.0代码发布
- 2024年6月25日: VisualRWKV-6.0检查点权重发布
这些更新体现了研究团队对模型持续优化和改进的努力,使VisualRWKV在性能和功能上不断进步。
VisualRWKV的创新架构
VisualRWKV的架构设计体现了视觉和语言模型的巧妙融合。以下是VisualRWKV的架构图:
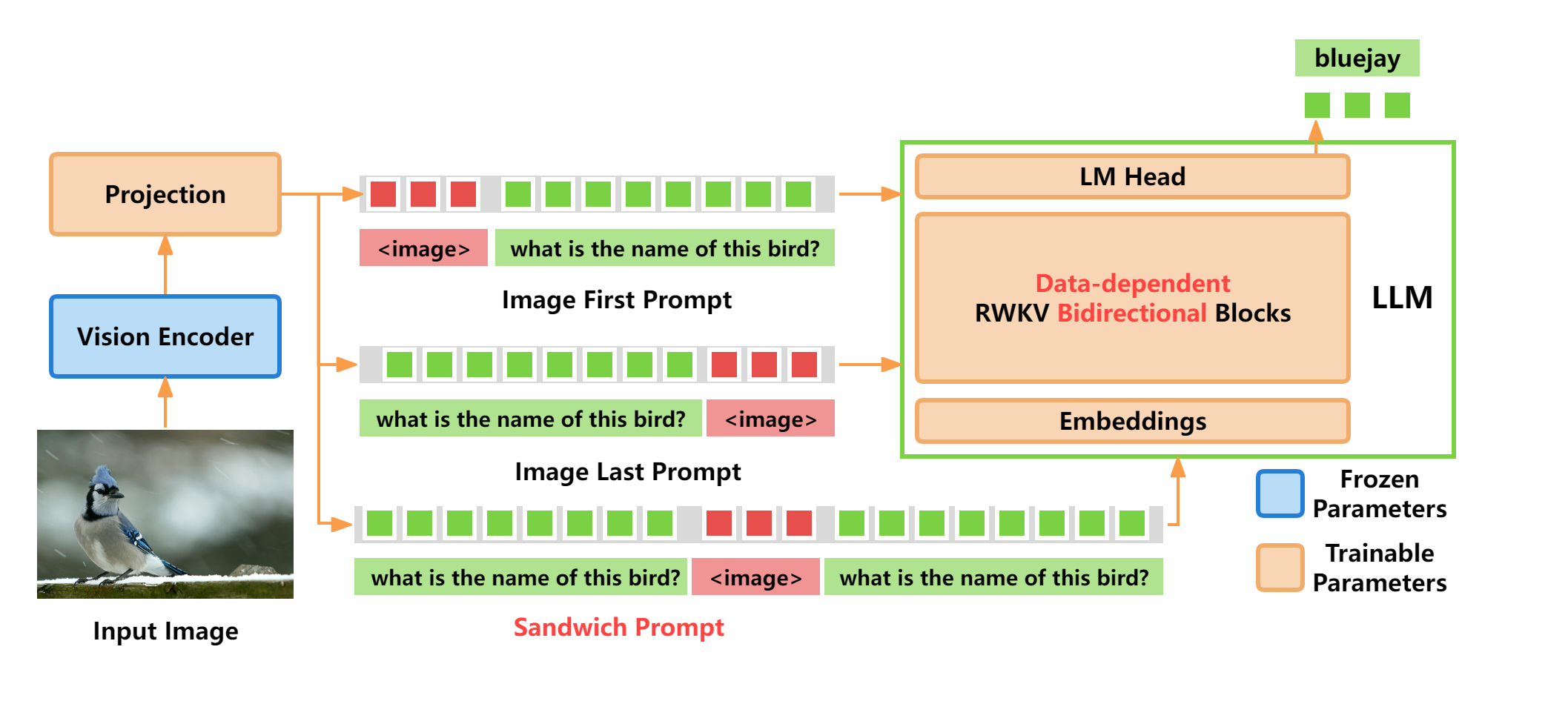
从架构图中我们可以看到,VisualRWKV主要由以下几个关键组件构成:
- 视觉编码器: 使用预训练的视觉模型(如CLIP)来提取图像特征。
- 投影层: 将视觉特征映射到RWKV模型的输入空间。
- RWKV主干网络: 处理融合后的视觉-语言信息。
- 输出层: 生成最终的多模态表示或任务特定输出。
这种设计允许模型有效地处理视觉和语言信息,实现了真正的多模态学习。
VisualRWKV的训练过程
VisualRWKV的训练分为两个主要阶段:预训练和微调。这种分阶段训练策略有助于模型充分学习视觉-语言之间的关联,并适应特定的下游任务。
预训练阶段
在预训练阶段,VisualRWKV主要学习如何将视觉信息与语言模型关联起来。具体步骤如下:
- 使用预训练数据集(如LLaVA-Pretrain)来训练投影层。
- 冻结预训练的视觉编码器和RWKV模型,只更新投影层参数。
- 训练目标是让投影后的视觉特征能够与RWKV模型的语言表示相匹配。
预训练命令示例:
export CUDA_VISIBLE_DEVICES=0,1,2,3
python train.py --load_model /path/to/rwkv/checkpoint \
--wandb "" --proj_dir path/to/output/ \
--data_file /path/to/LLaVA-Pretrain/blip_laion_cc_sbu_558k.json \
--data_type "json" --vocab_size 65536 \
--ctx_len 1024 --epoch_steps 1000 --epoch_count 9 --epoch_begin 0 --epoch_save 0 \
--micro_bsz 16 --accumulate_grad_batches 2 --n_layer 24 --n_embd 2048 --pre_ffn 0 \
--lr_init 1e-3 --lr_final 1e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
--accelerator gpu --devices 4 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 0 \
--image_folder /path/to/LLaVA-Pretrain/images/ \
--vision_tower_name /path/to/openai/clip-vit-large-patch14-336 \
--freeze_rwkv 24 --detail low --grid_size -1 --image_position first \
--enable_progress_bar True
微调阶段
微调阶段旨在使模型能够执行特定的视觉-语言任务。主要步骤包括:
- 使用视觉指令数据(如LLaVA数据集)进行微调。
- 解冻RWKV模型的部分或全部参数,允许模型进行更全面的学习。
- 训练目标是让模型能够理解并执行视觉相关的指令。
微调命令示例:
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python train.py --model_path path/to/pretrained-visualrwkv \
--wandb "" --proj_dir out/rwkv1b5-v060_mix665k \
--data_file /path/to/LLaVA-Instruct-150K/shuffled_llava_v1_5_mix665k.json \
--data_type "json" --vocab_size 65536 \
--ctx_len 2048 --epoch_steps 1000 --epoch_count 20 --epoch_begin 0 --epoch_save 5 \
--micro_bsz 8 --accumulate_grad_batches 2 --n_layer 24 --n_embd 2048 --pre_ffn 0 \
--lr_init 2e-5 --lr_final 2e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
--accelerator gpu --devices 8 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 0 \
--image_folder /path/to/LLaVA-Instruct-150K/images/ \
--vision_tower_name /path/to/openai/clip-vit-large-patch14-336 \
--freeze_rwkv 0 --freeze_proj 0 --detail low --grid_size -1 --image_position middle \
--enable_progress_bar True
VisualRWKV的优势与创新点
VisualRWKV在视觉语言模型领域具有以下几个显著优势:
-
高效的线性复杂度: 得益于RWKV的架构,VisualRWKV在处理长序列时具有线性时间和空间复杂度,这使得它在处理高分辨率图像和长文本时更加高效。
-
灵活的模型规模: VisualRWKV提供了多种规模的模型,从1.6B到7B参数不等,可以根据不同的应用场景和硬件条件选择合适的模型大小。
-
创新的视觉处理机制: VisualRWKV引入了数据依赖的循环和三明治提示等技术,增强了模型对视觉信息的建模能力。
-
二维图像扫描: 通过引入2D图像扫描机制,VisualRWKV能够更好地捕捉图像的空间结构信息,提高了视觉理解的准确性。
-
与RWKV的兼容性: VisualRWKV可以直接利用RWKV的预训练权重,这大大简化了模型的训练过程,同时也继承了RWKV在语言建模方面的优势。
VisualRWKV的应用前景
VisualRWKV的出现为视觉-语言任务带来了新的可能性。它可以应用于多个领域,包括但不限于:
- 图像描述生成: 自动为图像生成准确、流畅的描述文本。
- 视觉问答: 回答与图像相关的问题,展现对视觉内容的深入理解。
- 图像检索: 基于文本描述搜索相关图像,或根据图像内容检索相似图片。
- 多模态对话: 在对话系统中融入图像理解能力,实现更自然的人机交互。
- 视觉推理: 执行需要图像和文本信息结合的推理任务。
未来展望
尽管VisualRWKV已经展现出了令人印象深刻的性能,但研究团队仍在不断探索进一步的改进方向:
-
模型效率优化: 进一步提高模型在处理大规模数据时的效率,特别是在移动设备等资源受限环境下的表现。
-
多语言支持: 扩展VisualRWKV的语言能力,使其能够处理更多语言的视觉-语言任务。
-
跨模态迁移学习: 探索如何更好地利用语言模型的知识来增强视觉理解,以及反之。
-
实时视觉处理: 优化模型架构,使VisualRWKV能够在实时视频流等动态视觉场景中发挥作用。
-
与其他模态的集成: 考虑将音频等其他模态信息融入模型,实现更全面的多模态理解。
结语
VisualRWKV代表了视觉语言模型研究的一个重要方向,它成功地将高效的RNN架构引入了多模态学习领域。通过创新的架构设计和训练策略,VisualRWKV在保持计算效率的同时,实现了与Transformer基础的模型相媲美的性能。
随着研究的深入和技术的不断迭代,我们可以期待VisualRWKV在未来会带来更多令人兴奋的突破。无论是在学术研究还是工业应用中,VisualRWKV都展现出了巨大的潜力,有望推动视觉-语言交互技术向更智能、更自然的方向发展。
对于有兴趣深入了解或尝试使用VisualRWKV的读者,可以访问项目的GitHub仓库获取更多详细信息、代码实现和预训练模型。让我们共同期待VisualRWKV在视觉语言模型领域带来的更多创新和突破!









