
 访问官网
访问官网 Github
GithubPodracer
新闻:我们人手不足,请给我们加星并告知更新这个项目是紧急的。感谢您的反馈。
本项目可以被视为FinRL 2.0:面向全栈开发者和专业人士的中级框架。它基于ElegantRL和FinRL构建。
我们维护着一个**优雅(轻量、高效、稳定)**的FinRL库,帮助研究人员和量化交易员轻松开发算法策略。
-
轻量:核心代码不到800行,基于PyTorch和NumPy。
-
高效:其性能可与Ray RLlib媲美。
-
稳定:稳定性与Stable Baseline 3相当。
设计原则
-
遵循Python风格:量化交易员、数据科学家和机器学习工程师熟悉开源Python生态系统:其编程模型和工具,如NumPy。
-
以研究人员和算法交易员为先:基于PyTorch,我们支持研究人员手动控制代码执行,使他们能够提高自动化库的性能。
-
算法策略的精简开发:拥有一个优雅(可能略有不完整)的解决方案比全面但复杂且难以理解的设计更好,例如Ray RLlib 链接。这允许快速的代码迭代。
DRL算法
目前支持大多数无模型深度强化学习(DRL)算法:
- DDPG, TD3, SAC, A2C, PPO, PPO(GAE) 用于连续动作
- DQN, DoubleDQN, D3QN 用于离散动作
- MILP(使用自然进化策略学习切割) 用于投资组合优化
关于DRL算法,请查看教育网页OpenAI Spinning Up。
文件结构

agent.py中的代理使用net.py中的网络,并在run.py中通过与env.py中的环境交互进行训练。
- net.py # 神经网络
- Q-Net,
- Actor Network,
- Critic Network,
- agent.py # RL算法
- AgentBase
- AgentDQN
- AgentDDPG
- AgentTD3
- AgentSAC
- AgentPPO
- env.py # 股票交易环境
- run.py # 股票交易应用
- 参数初始化,
- 训练循环,
- 评估器
- StockTrading_Demo.ipynb # 使用PPO算法的单只股票交易演示
股票交易问题的formulation
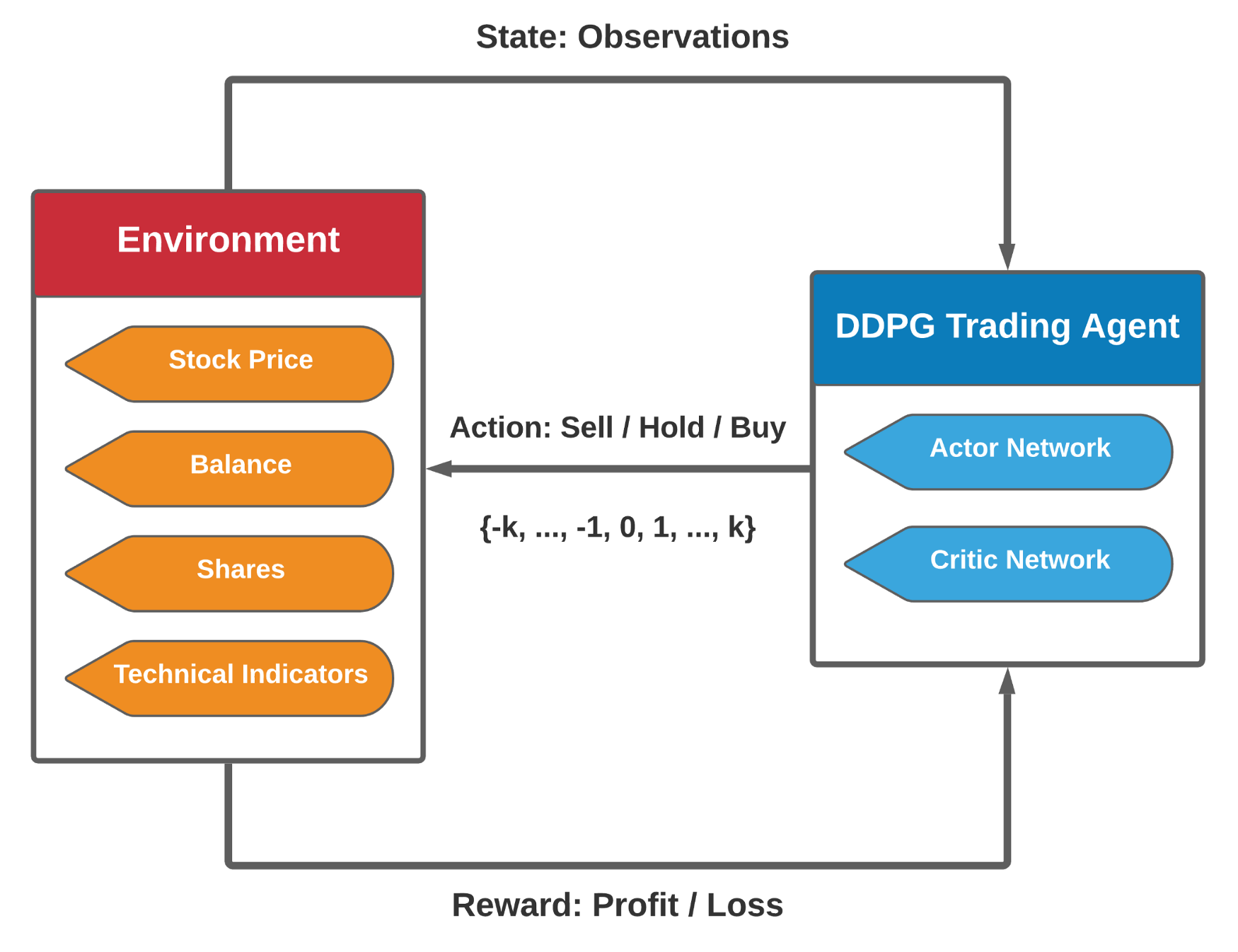
从形式上讲,我们将股票交易建模为马尔可夫决策过程(MDP),并将交易目标formulate为最大化预期回报:
- 状态 s = [b, p, h]:包括剩余余额b、股票价格p和股票份额h的向量。p和h是D维向量,其中D表示股票数量。
- 动作 a:对D只股票的动作向量。每只股票允许的动作包括卖出、买入或持有,分别导致h中的股票份额减少、增加或不变。
- 奖励 r(s, a, s'):在状态s采取动作a并到达新状态s'时的资产价值变化。
- 策略 π(s):在状态s的交易策略,是状态s下动作的概率分布。
- Q函数 Q(s, a):在状态s采取动作a并遵循策略π的预期回报(奖励)。
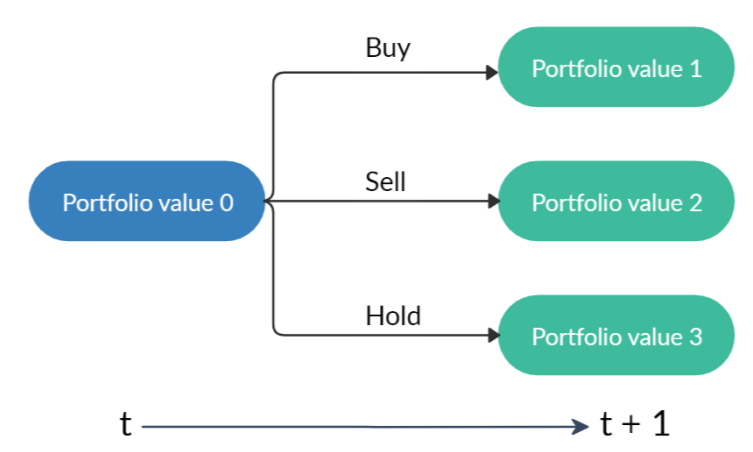
- 状态转换:采取动作a后,股票份额h被修改,如图3所示,新的投资组合是余额和股票总价值的总和。
股票交易环境
环境设计
环境设计采用OpenAI gym风格,因为它被认为是强化学习环境的标准实现。
- 初始化:预处理来自Yahoo Finance的股票数据,并初始化与股票交易问题相关的变量。在训练之前,使用初始化函数创建一个新环境以与代理交互。
- 重置:将环境的状态和变量重置为初始条件。当模拟停止并需要重新启动时使用此函数。
- 步进:状态接受代理的动作,然后返回包含三个内容的列表——下一个状态、奖励、当前episode是否结束的指示。环境计算下一个状态和奖励的方式基于之前博客中定义的状态-动作转换。当代理收集用于训练的转换时使用步进函数。
状态空间和动作空间
- 状态空间:我们使用181维向量表示多只股票交易环境的状态空间,包含七部分信息:[b, p, h, M, R, C, X],其中b是余额,p是股票价格,h是股票份额,M是移动平均收敛散度(MACD),R是相对强弱指标(RSI),C是商品通道指数(CCI),X是平均趋向指标(ADX)。
- 动作空间:回顾一下,单只股票有三种动作:卖出、买入和持有。我们使用负值表示卖出,正值表示买入,零表示持有。在这种情况下,动作空间定义为{-k, ..., -1, 0, 1, ..., k},其中k是每次交易买入或卖出的最大份额。
易于定制的特性
- Initial_capital:用户希望投资的初始资金。
- Tickers:用户希望交易的股票池。
- Initial_stocks:每只股票的初始数量,默认可以为零。
- buy_cost_pct, sell_cost_pct:每次买入或卖出交易的交易费用。
- Max_stock:用户可以定义每次交易允许交易的最大股票数量。
- tech_indicator_list:考虑的金融指标列表,用于定义状态。
- start_date, start_eval_date, end_eval_date:训练和回测的时间区间。使用三个日期(或时间戳),一旦指定训练期,剩余部分用于回测。











