
 访问官网
访问官网 Github
Github 论文
论文Video-MME:首个全面评估多模态大语言模型视频分析能力的基准测试

Video-MME适用于图像多模态大语言模型(即泛化到多张图像)和视频多模态大语言模型。🌟
🔥 最新动态
2024.06.15🌟 我们更新了评估内容:1) 替换了失效和可能失效的视频链接,并重新标注;2) GPT-4o现在以512x512分辨率采样384帧(之前从网站采样10帧),将整体准确率提升至71.9%。2024.06.03🌟 我们非常自豪地推出Video-MME,这是首个全面评估多模态大语言模型视频分析能力的基准测试!
👀 Video-MME概述
在追求人工通用智能的过程中,多模态大语言模型(MLLMs)已成为近期进展的焦点,但它们在处理序列视觉数据方面的潜力仍未得到充分探索。我们推出了Video-MME,这是首个全面评估多模态大语言模型视频分析能力的基准测试。它旨在全面评估MLLMs处理视频数据的能力,涵盖广泛的视觉领域、时间跨度和数据模态。Video-MME包含900个视频,总时长254小时,以及2,700个人工标注的问答对。我们的工作通过四个关键特征与现有基准测试区分开来:
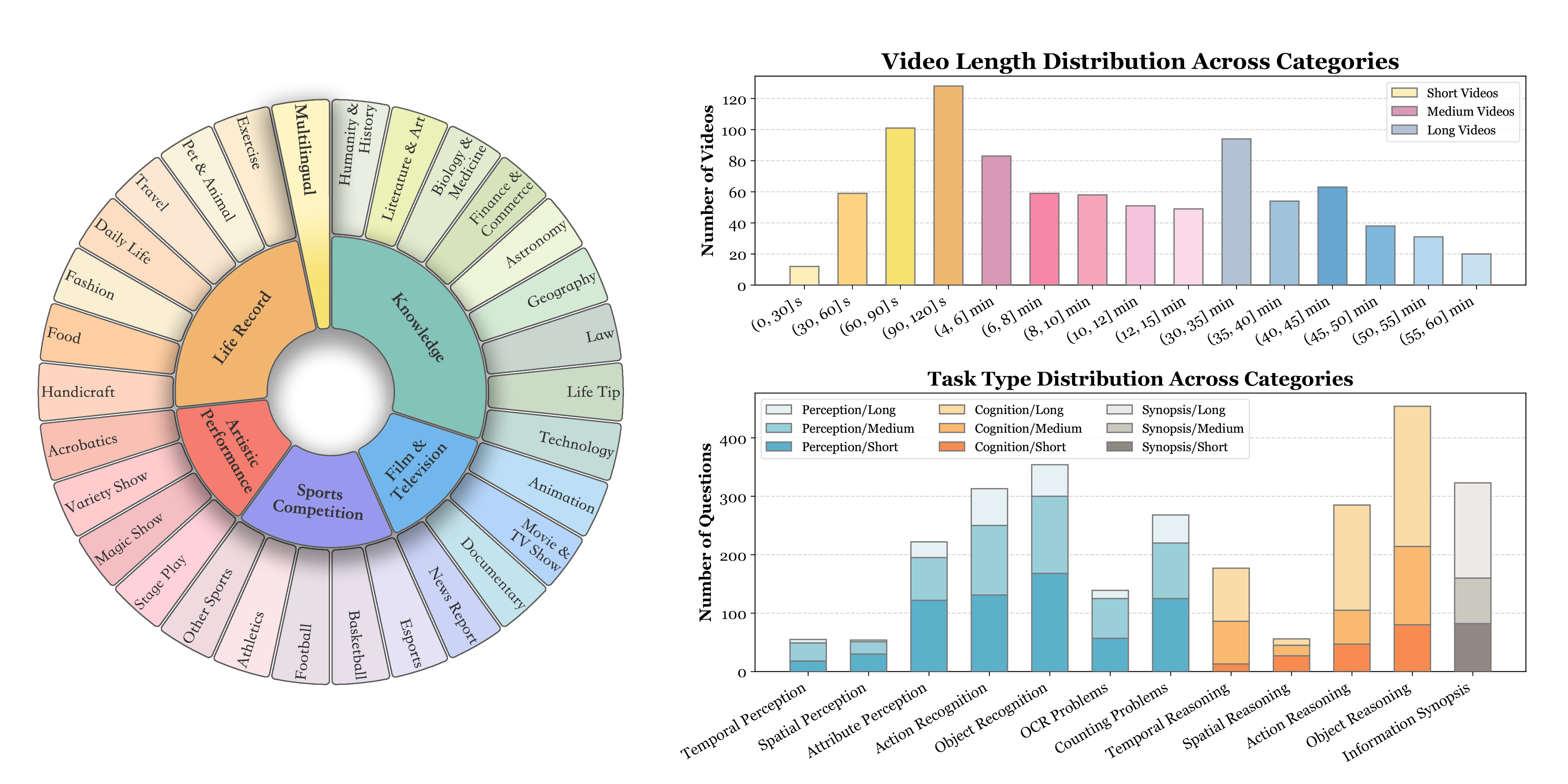
- 时间维度的持续时间。包括短期(<2分钟)、中期(4-15分钟)和长期(30-60分钟)视频,时长范围从11秒到1小时,以实现稳健的上下文动态;
- 视频类型的多样性。跨越6个主要视觉领域,即知识、影视、体育比赛、生活记录和多语言,包含30个子领域,以确保广泛的场景泛化能力;
- 数据模态的广度。除视频帧外,还整合了多模态输入,包括字幕和音频,以评估MLLMs的全方位能力;
- 标注的质量。所有数据都是新收集和人工标注的,不来自任何现有视频数据集,确保多样性和质量。
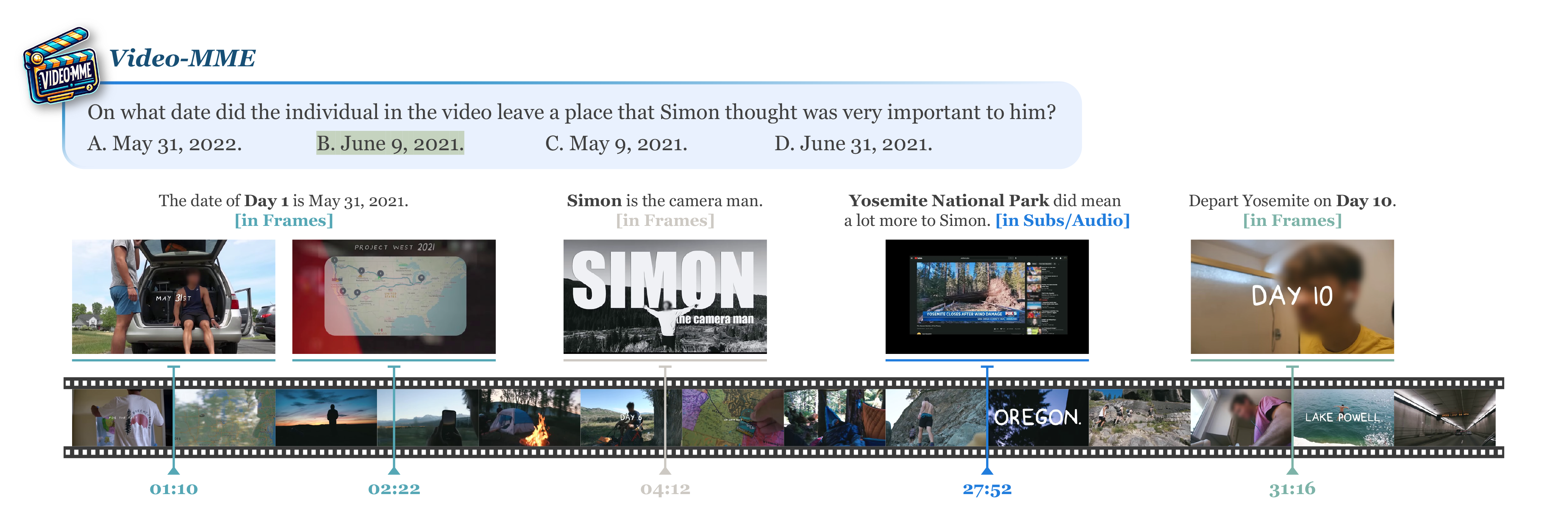
📐 数据集示例

点击展开更多示例


🔍 数据集
许可证:
Video-MME仅用于学术研究。禁止任何形式的商业使用。
所有视频的版权归视频所有者所有。
如果Video-MME中存在任何侵权行为,请发送电子邮件至videomme2024@gmail.com,我们将立即删除。
未经事先批准,您不得全部或部分分发、发布、复制、传播或修改Video-MME。
您必须严格遵守上述限制。
请发送电子邮件至videomme2024@gmail.com。🌟
🔮 评估流程
📍 提取帧和字幕:
共有900个视频和744个字幕,所有长视频都有字幕。
对于添加字幕的设置,您应该只使用与采样视频帧对应的字幕。 例如,如果您为评估提取每个视频的10帧,则取与这10帧时间对应的10个字幕。
如果您已准备好视频和字幕文件,可以参考此脚本来提取帧和对应的字幕。
📍 提示:
我们评估中使用的通用提示格式如下:
此视频的字幕如下所示:
[字幕]
根据视频选择以下多项选择题的最佳答案。仅回答正确选项的字母(A、B、C或D)。
[问题]
最佳答案是:
对于无字幕设置,您应该删除字幕内容。
点击展开提示示例。
- 带字幕:
此视频的字幕如下所示:
大家好,我将向你们展示如何完美地准备一个...
根据视频选择以下多项选择题的最佳答案。仅回答正确选项的字母(A、B、C或D)。
视频中人物穿着什么颜色的衣服?
A. 黑色。
B. 灰色。
C. 绿色。
D. 棕色。
最佳答案是:
- 无字幕:
根据视频选择以下多项选择题的最佳答案。只需回答正确选项的字母(A、B、C或D)。
视频中人物穿的衣服是什么颜色的?
A. 黑色。
B. 灰色。
C. 绿色。
D. 棕色。
最佳答案是:
📍 评估:
为了提取答案并计算分数,我们将模型响应添加到JSON文件中。这里我们提供了一个示例模板output_test_template.json。一旦您按此格式准备好模型响应,请参考评估脚本eval_your_results.py,您将获得不同视频时长、视频领域、视频子类别和任务类型的准确度分数。 评估不会引入任何第三方模型,如ChatGPT。
python eval_your_results.py \
--results_file $YOUR_RESULTS_FILE \
--video_duration_type $VIDEO_DURATION_TYPE \
--return_categories_accuracy \
--return_sub_categories_accuracy \
--return_task_types_accuracy
请确保results_file遵循上述指定的JSON格式,并将video_duration_type指定为short、medium或long之一。如果您希望评估不同时长类型的结果,可以指定多个类型,用逗号分隔或组织成列表,例如:short,medium,long或["short","medium","long"]。
📍 排行榜:
如果您想将您的模型添加到我们的排行榜,请将模型响应发送至bradyfu24@gmail.com,格式应与output_test_template.json相同。
📈 实验结果
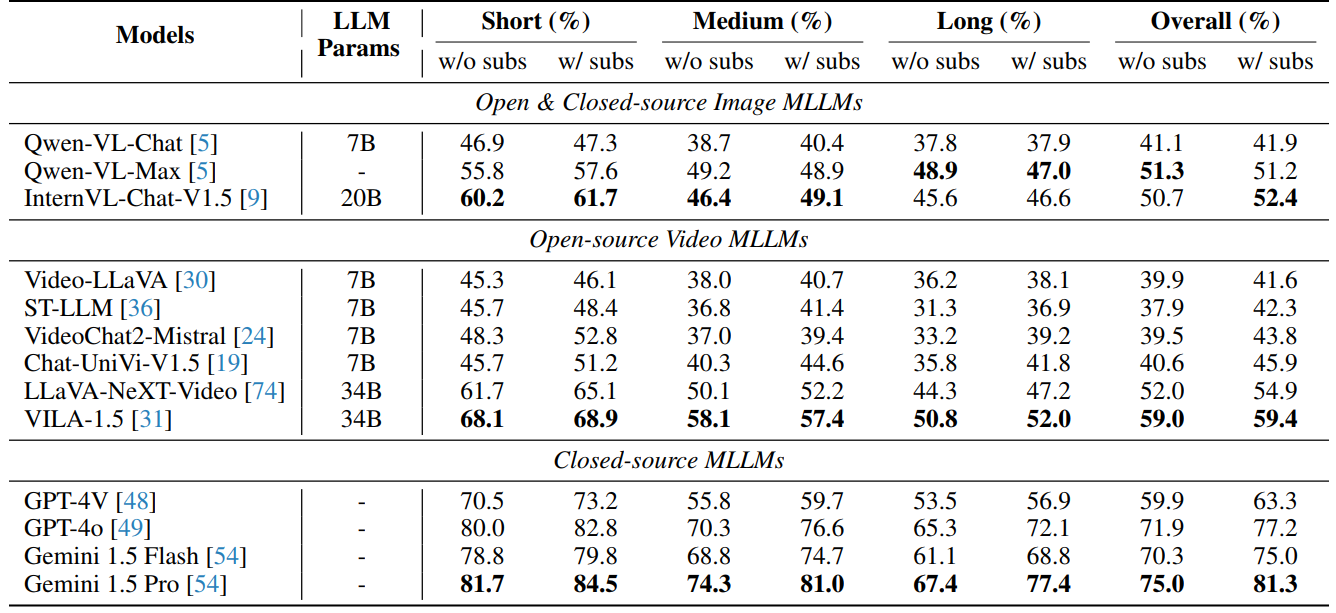
- 不同MLLM的评估结果。
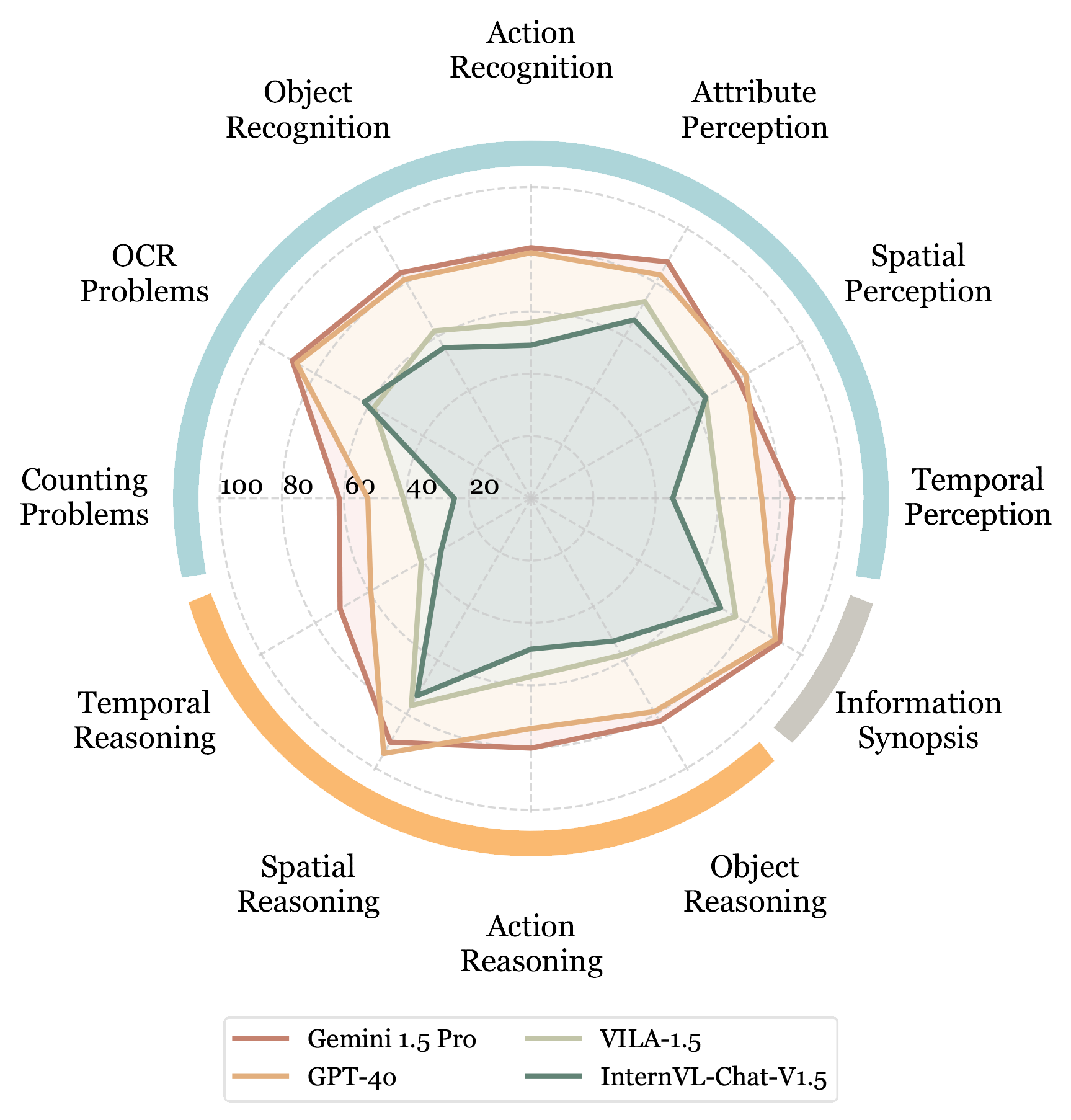
- 不同MLLM在不同任务类型上的评估结果。
- Gemini 1.5 Pro在不同视频时长类型上的评估结果。
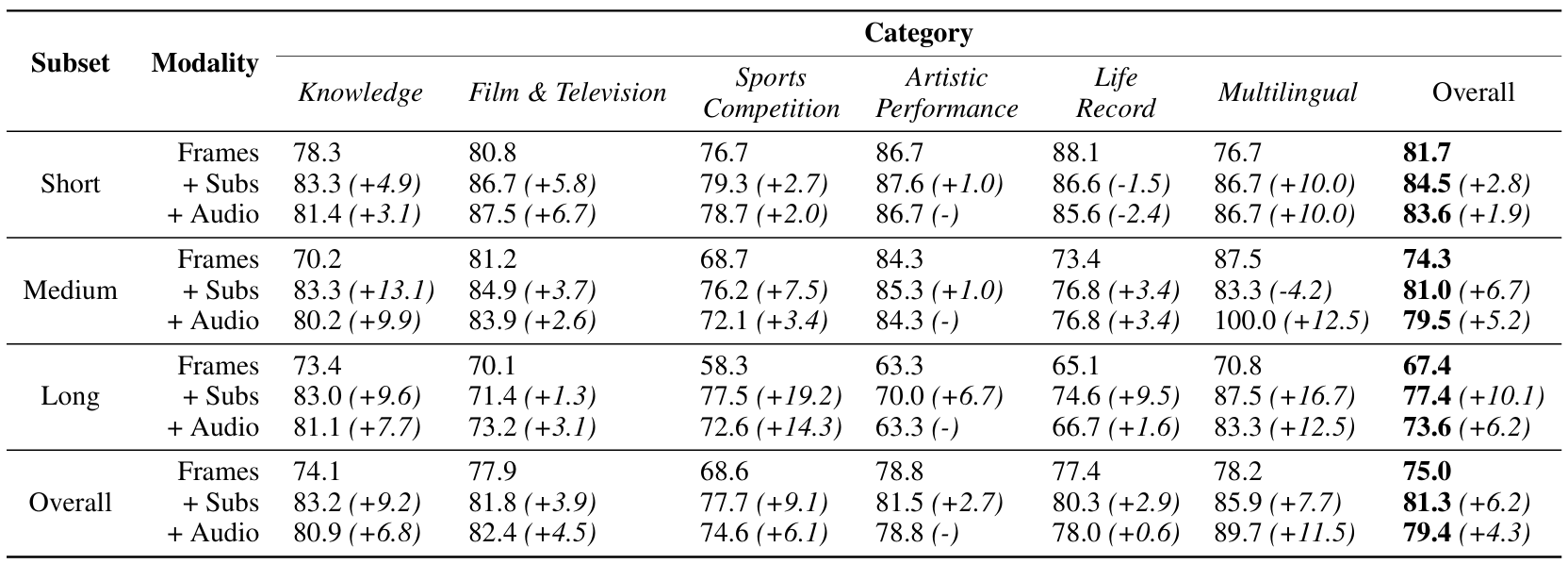
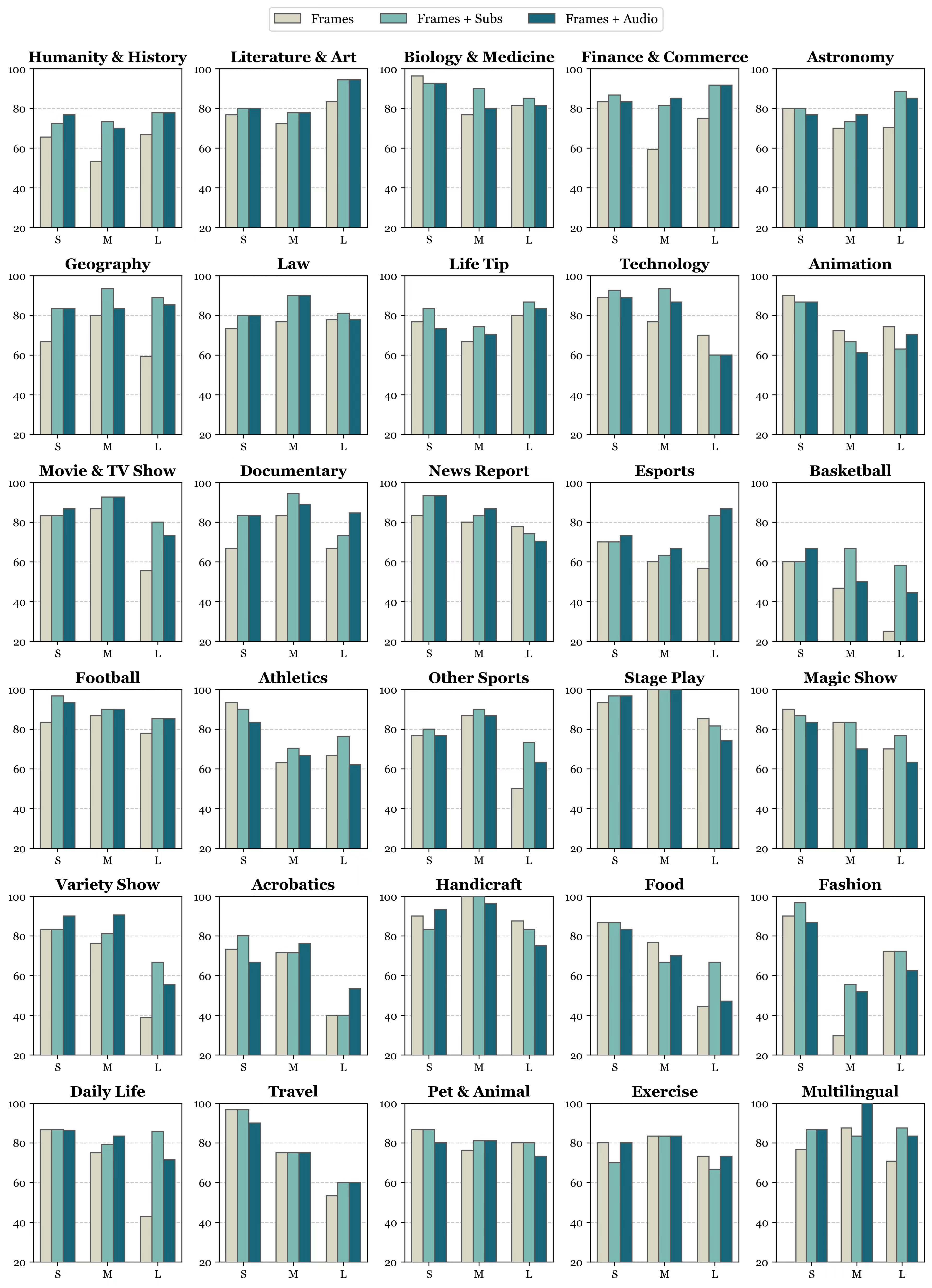
- Gemini 1.5 Pro在不同视频子类型上的评估结果。
:black_nib: 引用
如果您发现我们的工作对您的研究有帮助,请考虑引用我们的工作。
@article{fu2024video,
title={Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis},
author={Fu, Chaoyou and Dai, Yuhan and Luo, Yondong and Li, Lei and Ren, Shuhuai and Zhang, Renrui and Wang, Zihan and Zhou, Chenyu and Shen, Yunhang and Zhang, Mengdan and others},
journal={arXiv preprint arXiv:2405.21075},
year={2024}
}
📜 相关工作
探索我们的相关研究:
- [MME] MME: 多模态大语言模型的综合评估基准
- [Awesome-MLLM] 多模态大语言模型综述











