
 访问官网
访问官网 Github
Github 论文
论文MotionClone
本仓库是MotionClone的官方实现。这是一个无需训练的框架,能够从参考视频中克隆动作,用于可控的文本到视频生成。
点击查看MotionClone的完整摘要
我们提出了MotionClone,一个无需训练的框架,能够从参考视频中克隆动作来控制文本到视频的生成。我们在视频反演中使用时间注意力来表示参考视频中的动作,并引入主要时间注意力引导来减轻注意力权重中噪声或非常细微动作的影响。此外,为了帮助生成模型合成合理的空间关系并增强其遵循提示的能力,我们提出了一种位置感知的语义引导机制,利用参考视频中前景的粗略位置和原始的无分类器引导特征来指导视频生成。
MotionClone: 用于可控视频生成的无训练动作克隆
凌鹏洋*,
卜佳梓*,
张盼†,
董晓毅,
臧宇航,
吴桐,
陈华安,
王佳琦,
金毅†
(*共同第一作者)(†通讯作者)


🖋 新闻
- 我们论文的最新版本(v3)已在arXiv上发布!(7.2)
- 代码已发布!(6.29)
🏗️ 待办事项
- 发布Gradio演示
- 发布MotionClone代码(我们已发布代码的第一个版本,并将继续优化。欢迎提出任何问题或疑问,我们将及时处理。)
- 发布论文
📚 展示
更多结果请参见项目页面。
🚀 方法概述
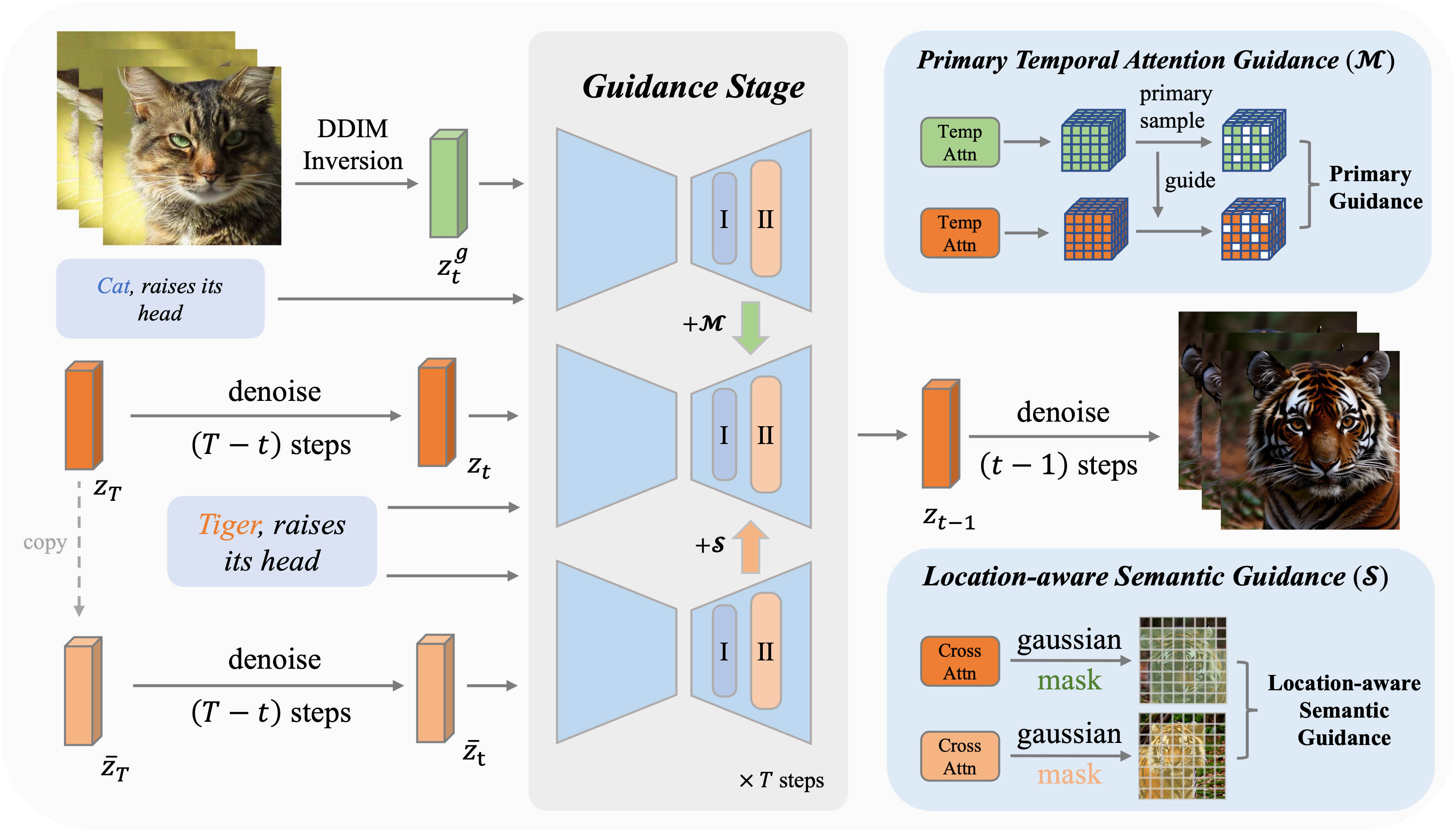
如上图所示,MotionClone在引导阶段包含两个核心组件:主要时间注意力引导和位置感知语义引导,它们协同工作,为可控视频生成提供全面的动作和语义引导。
🔧 安装(推荐python==3.11.3)
设置仓库和conda环境
git clone https://github.com/Bujiazi/MotionClone.git
cd MotionClone
conda env create -f environment.yaml
conda activate motionclone
🔑 预训练模型准备
下载Stable Diffusion V1.5
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5 models/StableDiffusion/
下载Stable Diffusion后,将其保存到models/StableDiffusion。
准备社区模型
手动从RealisticVision V5.1下载社区.safetensors模型,并保存到models/DreamBooth_LoRA。
准备AnimateDiff动作模块
手动从AnimateDiff下载AnimateDiff模块,我们推荐v3_adapter_sd_v15.ckpt和v3_sd15_mm.ckpt.ckpt。将模块保存到models/Motion_Module。
🎈 快速开始
执行DDIM反演
python invert.py --config configs/inference_config/fox.yaml
执行动作克隆
python sample.py --config configs/inference_config/fox.yaml
📎 引用
如果您觉得这项工作有帮助,请引用以下论文:
@article{ling2024motionclone,
title={MotionClone: Training-Free Motion Cloning for Controllable Video Generation},
author={Ling, Pengyang and Bu, Jiazi and Zhang, Pan and Dong, Xiaoyi and Zang, Yuhang and Wu, Tong and Chen, Huaian and Wang, Jiaqi and Jin, Yi},
journal={arXiv preprint arXiv:2406.05338},
year={2024}
}
📣 免责声明
这是MotionClone的官方代码。 演示图像和音频的所有版权均来自社区用户。 如果您希望删除它们,请随时与我们联系。
💞 致谢
本代码基于以下仓库构建,我们感谢所有贡献者的开源:











