
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文OpenShape: 扩展3D形状表示以实现开放世界理解
[新闻] OpenShape已被NeurIPS 2023接收。新奥尔良见!
[新闻] 我们已发布模型检查点、训练代码和训练数据!
[新闻] 在线演示已上线!感谢HuggingFace🤗赞助此演示!
"OpenShape: 扩展3D形状表示以实现开放世界理解"的官方代码。
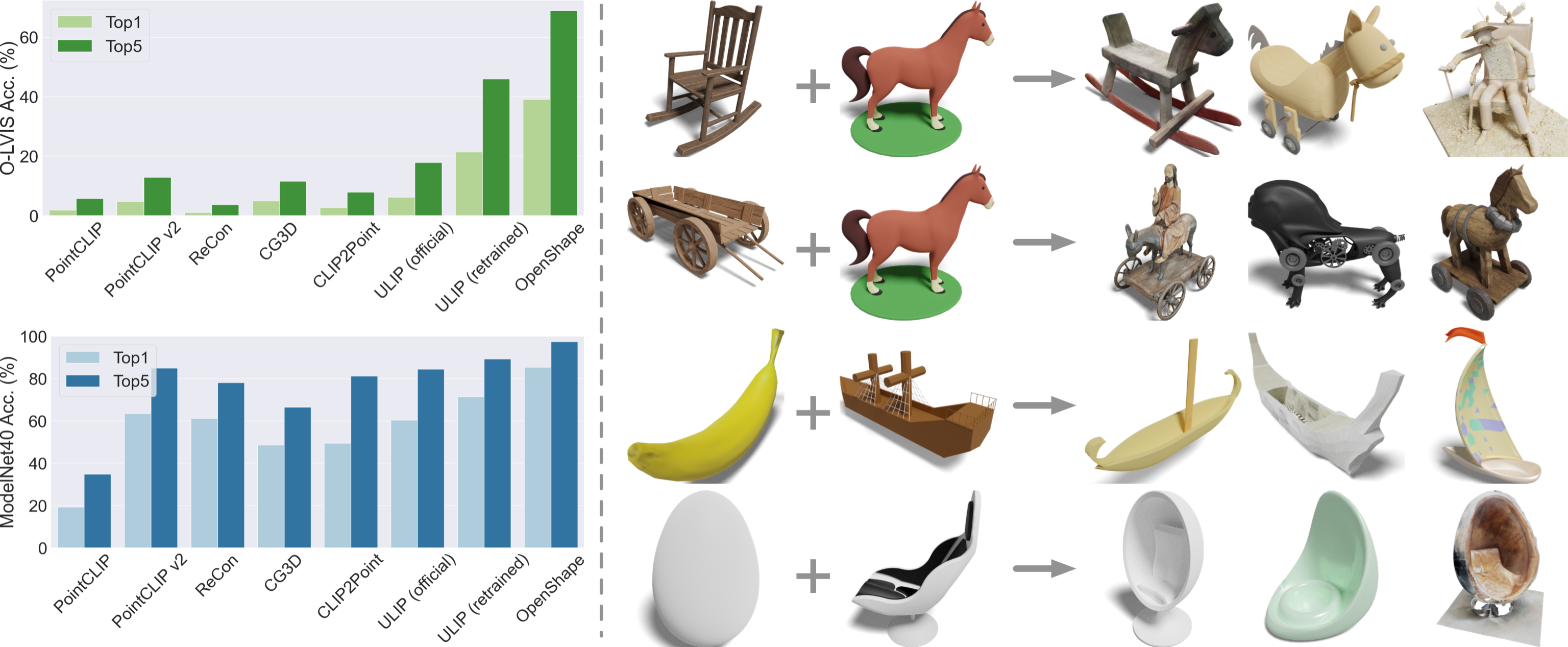 左图:在Objaverse-LVIS(1,156个类别)和ModelNet40数据集(40个常见类别)上的零样本3D形状分类。右图:我们的形状表示编码了广泛的语义和视觉概念。我们输入两个3D形状,并使用它们的形状嵌入来检索嵌入同时最接近两个输入的前三个形状。
左图:在Objaverse-LVIS(1,156个类别)和ModelNet40数据集(40个常见类别)上的零样本3D形状分类。右图:我们的形状表示编码了广泛的语义和视觉概念。我们输入两个3D形状,并使用它们的形状嵌入来检索嵌入同时最接近两个输入的前三个形状。
在线演示
探索在线演示,目前支持:(a) 3D形状分类(LVIS类别和用户上传的文本),(b) 3D形状检索(基于文本、图像和3D点云),(c) 点云描述生成,以及(d) 基于点云的图像生成。
演示使用streamlit构建。如遇"连接错误",请尝试清除浏览器缓存或使用隐身模式。
演示代码可在此处和此处找到。支持库(README)也可作为PointBERT骨干网络模型的推理库。
检查点
| 模型 | 训练数据 | CLIP版本 | 骨干网络 | Objaverse-LVIS零样本Top1(Top5) | ModelNet40零样本Top1(Top5) | 重力轴 | 备注 |
|---|---|---|---|---|---|---|---|
| pointbert-vitg14-rgb | 四个数据集 | OpenCLIP ViT-bigG-14 | PointBERT | 46.8 (77.0) | 84.4 (98.0) | z轴 | |
| pointbert-no-lvis | 四个数据集(无LVIS) | OpenCLIP ViT-bigG-14 | PointBERT | 39.1 (68.9) | 85.3 (97.4) | z轴 | |
| pointbert-shapenet-only | 仅ShapeNet | OpenCLIP ViT-bigG-14 | PointBERT | 10.8 (25.0) | 70.3 (91.3) | z轴 | |
| spconv-all | 四个数据集 | OpenCLIP ViT-bigG-14 | SparseConv | 42.7 (72.8) | 83.7 (98.4) | z轴 | |
| spconv-all-no-lvis | 四个数据集(无LVIS) | OpenCLIP ViT-bigG-14 | SparseConv | 38.1 (68.2) | 84.0 (97.3) | z轴 | |
| spconv-shapenet-only | 仅ShapeNet | OpenCLIP ViT-bigG-14 | SparseConv | 12.1 (27.1) | 74.1 (89.5) | z轴 | |
| pointbert-vitl14-rgb | Objaverse(无LVIS) | CLIP ViT-L/14 | PointBERT | 不适用 | 不适用 | y轴 | 用于图像生成演示 |
| pointbert-vitb32-rgb | Objaverse | CLIP ViT-B/32 | PointBERT | 不适用 | 不适用 | y轴 | 用于点云描述生成演示 |
安装
如果您想在本地运行推理或(和)训练,可能需要安装以下依赖项。
- 创建conda环境并通过以下命令或官方指南安装pytorch、MinkowskiEngine和DGL:
conda create -n OpenShape python=3.9
conda activate OpenShape
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine
conda install -c dglteam/label/cu113 dgl
- 安装以下软件包:
pip install huggingface_hub wandb omegaconf torch_redstone einops tqdm open3d
推理
尝试以下示例代码,计算3D点云的OpenShape嵌入,并计算3D-文本和3D-图像相似度。
python3 src/example.py
请对输入点云进行归一化,并确保点云的重力轴与预训练模型一致。
训练
- 处理后的训练和评估数据可在此处找到。使用以下命令下载并解压数据:
python3 download_data.py
总数据大小约为205G,文件将并行下载和解压。如果您不需要在Objaverse数据集上进行训练和评估,可以跳过该部分(约185G)。
- 使用以下命令运行训练:
wandb login {YOUR_WANDB_ID}
python3 src/main.py dataset.train_batch_size=20 --trial_name bs_20
默认配置可在src/configs/train.yml中找到,适用于单个A100 GPU训练。您也可以通过传递参数来更改设置。以下是论文中使用的主要实验的一些示例:
python3 src/main.py --trial_name spconv_all
python3 src/main.py --trial_name spconv_no_lvis dataset.train_split=meta_data/split/train_no_lvis.json
python3 src/main.py --trial_name spconv_shapenet_only dataset.train_split=meta_data/split/ablation/train_shapenet_only.json
python3 src/main.py --trial_name pointbert_all model.name=PointBERT model.scaling=4 model.use_dense=True training.lr=0.0005 training.lr_decay_rate=0.967
python3 src/main.py --trial_name pointbert_no_lvis model.name=PointBERT model.scaling=4 model.use_dense=True training.lr=0.0005 training.lr_decay_rate=0.967 dataset.train_split=meta_data/split/train_no_lvis.json
python3 src/main.py --trial_name pointbert_shapenet_only model.name=PointBERT model.scaling=4 model.use_dense=True training.lr=0.0005 training.lr_decay_rate=0.967 dataset.train_split=meta_data/split/ablation/train_shapenet_only.json
你可以在wandb页面上跟踪训练和评估(Objaverse-LVIS和ModelNet40)的曲线。
数据
所有数据可以在这里找到。使用python3 download_data.py下载它们。
训练数据
训练数据包括Objaverse/000-xxx.tar.gz、ShapeNet.tar.gz、3D-FUTURE.tar.gz和ABO.tar.gz。解压后,你将得到每个形状的一个numpy文件,其中包括:
dataset:str,形状的数据集。group:str,形状的组别。id:str,形状的ID。xyz:numpy数组(10000 x 3, [-1,1]),形状的点云。rgb:numpy数组(10000 x 3, [0, 1]),点云的颜色。image_feat:numpy数组,12张渲染图像的图像特征。thumbnail_feat:numpy数组,缩略图的图像特征。text:字符串列表,形状的原始文本,使用数据集的元数据构建。text_feat:字典列表,text的文本特征。"original"表示没有提示工程的原始文本特征。"prompt_avg"表示使用基于模板的提示工程的平均文本特征。blip_caption:str,为缩略图或渲染图像生成的BLIP描述。blip_caption_feat:dict,blip_caption的文本特征。msft_caption:str,为缩略图或渲染图像生成的Microsoft Azure描述。msft_caption_feat:dict,msft_caption的文本特征。retrieval_text:str列表,为缩略图或渲染图像检索的文本。retrieval_text_feat:字典列表,retrieval_text的文本特征。
所有图像和文本特征都是使用OpenCLIP (ViT-bigG-14, laion2b_s39b_b160k)提取的。
元数据
meta_data.zip包括用于训练和评估(在Objaverse-LVIS、ModelNet40和ScanObjectNN上)的元数据:
split/:训练形状列表。train_all.json表示使用四个数据集(Objaverse、ShapeNet、ABO和3D-FUTURE)进行训练。train_no_lvis.json表示使用四个数据集但排除Objaverse-LVIS形状进行训练。ablation/train_shapenet_only.json表示仅使用ShapeNet形状进行训练。gpt4_filtering.json:使用GPT4生成的Objaverse原始文本的过滤结果。point_feat_knn.npy:使用形状特征计算的KNN索引,用于训练期间的困难挖掘。modelnet40/test_split.json:ModelNet40测试形状列表。modelnet40/test_pc.npy:ModelNet40测试形状的点云,10000 x 3。modelnet40/cat_name_pt_feat.npy:ModelNet40类别名称的文本特征,使用了提示工程。lvis_cat_name_pt_feat.npy:Objeverse-LVIS类别名称的文本特征,使用了提示工程。scanobjectnn/xyz_label.npy:ScanObjectNN测试形状的点云和标签。scanobjectnn/cat_name_pt_feat.npy:ScanObjectNN类别名称的文本特征,使用了提示工程。 所有文本特征都是使用OpenCLIP (ViT-bigG-14, laion2b_s39b_b160k)提取的。
引用
如果您发现我们的代码有帮助,请引用我们的论文:
@misc{liu2023openshape,
title={OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding},
author={Minghua Liu and Ruoxi Shi and Kaiming Kuang and Yinhao Zhu and Xuanlin Li and Shizhong Han and Hong Cai and Fatih Porikli and Hao Su},
year={2023},
eprint={2305.10764},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











