
 Github
Github Huggingface
HuggingfacexVA合成器
xVASynth是一款基于机器学习的语音合成应用程序,使用来自视频游戏的角色/语音集。
Steam: https://store.steampowered.com/app/1765720/xVASynth_v2
HuggingFace 🤗 在线演示空间: https://huggingface.co/spaces/Pendrokar/xVASynth
新功能:xVATrainer,用于训练您自己的自定义语音:https://github.com/DanRuta/xva-trainer
观看演示(YouTube链接)
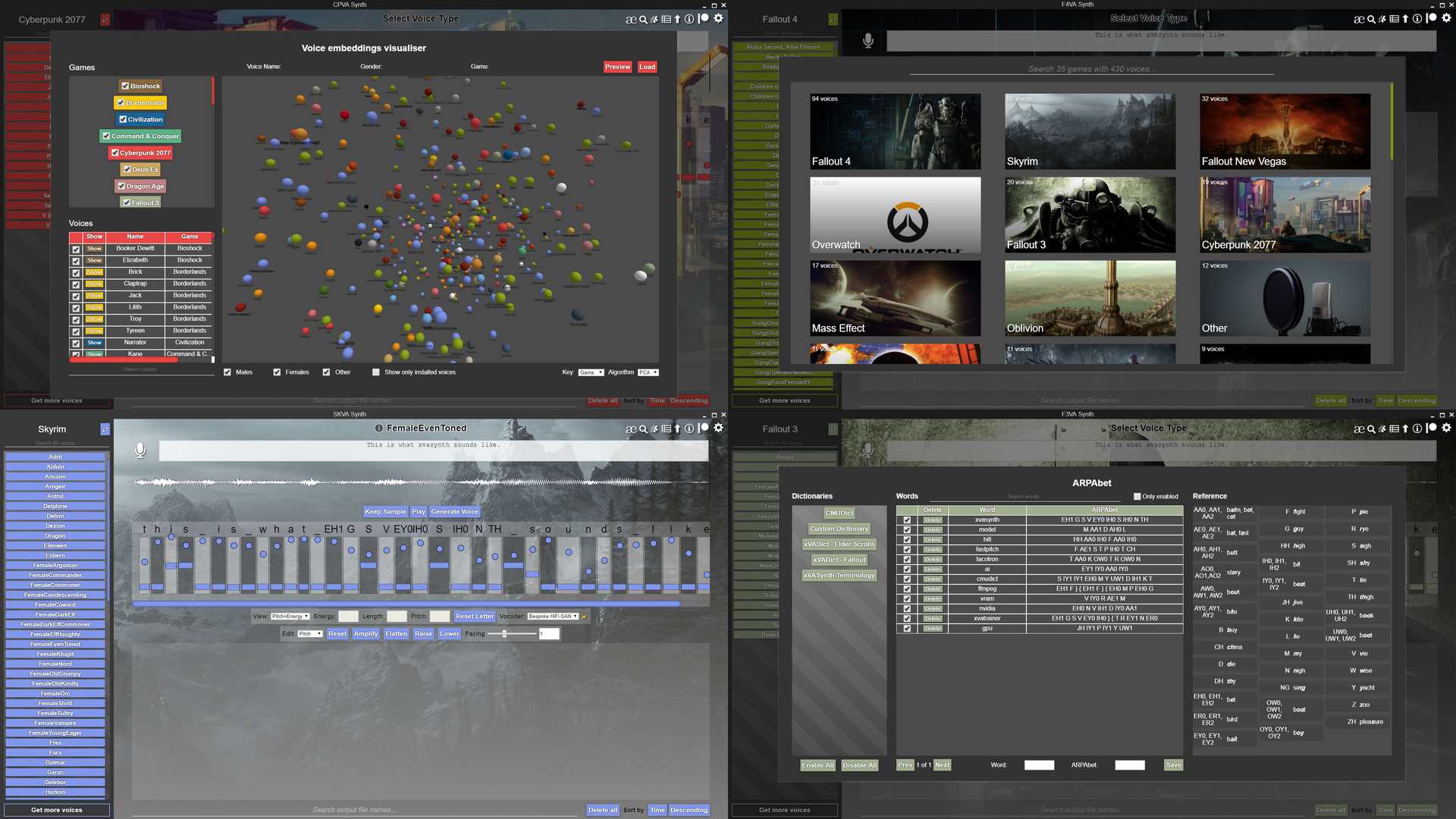
这是一个Electron UI,包装了对训练于视频游戏语音数据的FastPitch模型的推理。该应用程序作为一个框架,加载并使用给定的任何模型。因此,应用程序本身不执行任何操作,需要安装模型。具有相应资产文件的模型将在各自的游戏/类别中加载。其他模型则加载在"其他"类别中。
这个工具的主要优点是允许模组创作者为第三方游戏修改(模组)生成新的语音线。它还有其他用途,如创建游戏视频,以及用熟悉的声音进行娱乐。
加入Discord聊天:https://discord.gg/nv7c6E2TzV
安装
尽可能从Nexusmods网站下载应用程序(文件选项卡,"主要文件"部分)。那里的编译版本将是最新的。
基础应用程序可以下载并放置在任何位置。如果有空间,尽量将其安装在SSD上,以减少语音集加载时间。要安装语音集,可以将文件放入相应的游戏目录:xVASynth/resources/app/models/<game>/
使用说明
观看上面的视频,了解本节的概要。
首先,下载最新版本,双击xVASynth.exe文件,如果Windows要求允许运行python服务器脚本(内部使用),请确保点击允许。或者,查看开发部分,了解如何运行未打包的开发代码。
应用程序启动并运行后,从左上角的下拉菜单中选择语音集类别(游戏),然后点击特定的语音集。
显示该语音集已合成的音频文件列表(如果有)。要进行合成,点击加载模型按钮。在速度较慢的机器上,这可能需要一分钟。
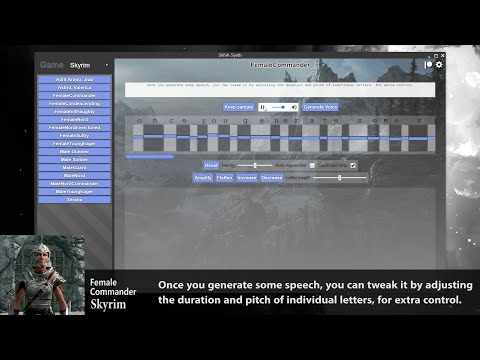
完成后,在文本区域输入您的文本,然后点击生成语音按钮。生成后,您将看到输出的预览。点击保留样本按钮保存到文件,或在修改文本输入后点击生成语音以丢弃并重新生成。
您可以通过上下移动字母滑块或使用下方工具栏中的工具来调整单个字母的音高、持续时间和能量。
在音频文件列表中,您可以预览、重命名、点击打开包含文件夹或删除每个文件。
如果您的系统上安装了所需的CUDA依赖项,可以通过切换设置菜单中的开关(点击右上角的设置齿轮)来启用GPU推理。
开发
- 使用
npm install安装Node模块。 - 使用
python -m venv .venv创建Python 3.9虚拟环境。 - 激活虚拟环境。
- 从
requirements_*.txt文件之一安装Python依赖项。例如,pip install -r requirements_cpu.txt。 - 使用
npm start运行应用程序。
该应用程序同时使用JavaScript(Electron,UI)和Python代码(FastPitch模型)。由于python脚本需要与应用程序一起持续运行并接收输入,通信是通过HTTP服务器完成的,JavaScript代码在本地主机端口8008发送请求。在开发过程中,使用python源代码。在生产环境中,使用编译后的python。
打包
首先,运行package.json中的脚本创建electron可分发文件。
其次,使用pyinstaller编译python。pip install pyinstaller并运行pyinstaller -F server.spec。丢弃build文件夹,将dist中的server文件夹移动到release-builds/xVASynth-win32-x64/resources/app中,并将其重命名为cpython。分发xVASynth-win32-x64中的内容,并通过xVASynth.exe运行应用程序。
运行分发的应用程序一次,检查server.log文件是否有问题,在分发前删除任何不必要的文件。
确保删除环境文件夹,如果它被复制到分发输出中。
不过,如果您只是在JS/HTML/CSS中进行小的调整,可能更容易直接编辑/复制文件到现有的打包可分发文件中。这里没有使用代码混淆或类似的技术。
模型
已经为这个应用程序训练了大量模型。它们公开托管在nexus.com网站上,在相应游戏的游戏页面上。
未来计划
目前的未来计划是继续为更多声音训练模型,还有很多待完成。











