
 Github
Github Huggingface
Huggingface 论文
论文

轻松地像人类一样对复杂文档进行分块。
文档分块是任何RAG系统的基础性挑战任务。高质量的结果对于成功的AI应用至关重要,然而大多数开源库在处理复杂文档方面的能力有限。
Open Parse旨在填补这一空白,提供一个灵活、易用的库,能够视觉识别文档布局并有效地进行分块。
这与其他布局解析器有何不同?
✂️ 文本分割
文本分割将文件转换为原始文本并进行切片。
- 你失去了在原始PDF上轻松叠加块的能力
- 你忽略了文件的基本语义结构 - 标题、章节、要点代表了宝贵的信息。
- 不支持表格、图像或markdown。
🤖 机器学习布局解析器
有一些出色的库,如layout-parser。
- 虽然它们可以识别各种元素,如文本块、图像和表格,但它们并不是为有效地分组相关内容而构建的。
- 它们严格专注于布局解析 - 你需要添加另一个模型来从图像中提取markdown、解析表格、分组节点等。
- 我们发现在许多文档上性能不佳,同时计算成本也很高。
💼 商业解决方案
亮点
-
🔍 视觉驱动: Open-Parse通过视觉分析文档,为LLM提供更优质的输入,超越了简单的文本分割。
-
✍️ Markdown支持: 支持解析标题、粗体和斜体的基本markdown。
-
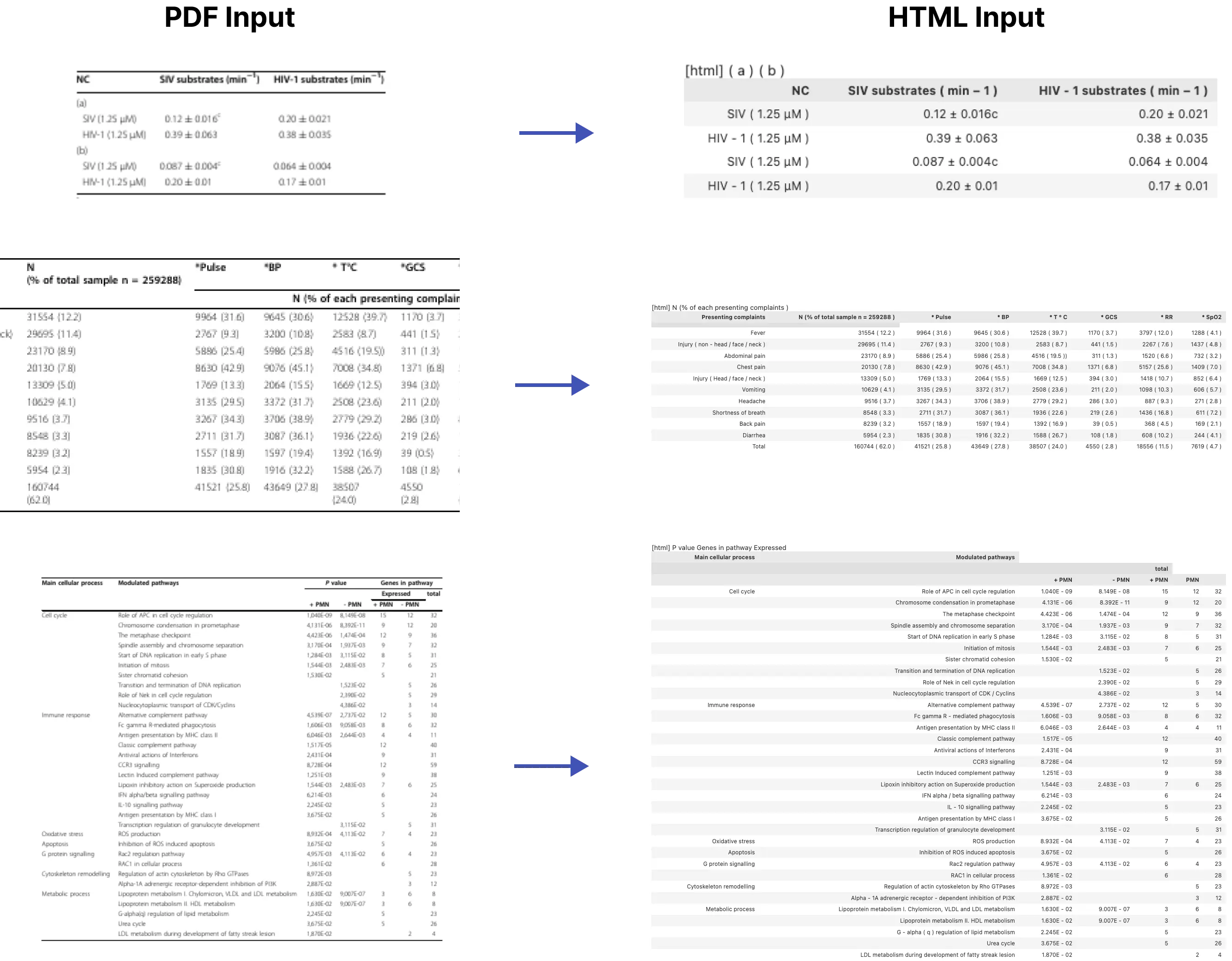
📊 高精度表格支持: 将表格提取为干净的Markdown格式,准确度超过传统工具。
示例
以下示例使用unitable进行解析。
-
🛠️ 可扩展: 轻松实现自己的后处理步骤。
-
💡直观: 出色的编辑器支持。处处都有自动完成。减少调试时间。
-
🎯 简单: 设计易于使用和学习。减少阅读文档的时间。

示例
基本示例
import openparse
basic_doc_path = "./sample-docs/mobile-home-manual.pdf"
parser = openparse.DocumentParser()
parsed_basic_doc = parser.parse(basic_doc_path)
for node in parsed_basic_doc.nodes:
print(node)
📓 试用示例笔记本 点击这里
语义处理示例
文档分块本质上是将相似的语义节点分组在一起。通过嵌入每个节点的文本,我们可以根据它们的相似性将它们聚类在一起。
from openparse import processing, DocumentParser
semantic_pipeline = processing.SemanticIngestionPipeline(
openai_api_key=OPEN_AI_KEY,
model="text-embedding-3-large",
min_tokens=64,
max_tokens=1024,
)
parser = DocumentParser(
processing_pipeline=semantic_pipeline,
)
parsed_content = parser.parse(basic_doc_path)
📓 示例笔记本 点击这里
序列化结果
底层使用pydantic,因此你可以使用以下方式序列化结果
parsed_content.dict()
# 或转换为有效的json字典
parsed_content.json()
要求
Python 3.8+
处理PDF:
- pdfminer.six 完全开源。
提取表格:
- PyMuPDF 有一些表格检测功能。请查看他们的许可证。
- Table Transformer 是一种深度学习方法。
- unitable 是另一种基于transformer的方法,具有最先进的性能。
安装
1. 核心库
pip install openparse
启用OCR支持:
PyMuPDF已经包含了支持OCR功能的所有逻辑。但它还需要Tesseract的语言支持数据,所以仍然需要安装Tesseract-OCR。
语言支持文件夹的位置必须通过将其存储在环境变量"TESSDATA_PREFIX"中,或作为适用函数中的参数来传达。
因此,要使OCR功能正常工作,请确保完成以下清单:
-
安装Tesseract。
-
定位Tesseract的语言支持文件夹。通常你会在以下位置找到它:
-
Windows:
C:/Program Files/Tesseract-OCR/tessdata -
Unix系统:
/usr/share/tesseract-ocr/5/tessdata -
macOS(通过Homebrew安装):
- 标准安装:
/opt/homebrew/share/tessdata - 特定版本安装:
/opt/homebrew/Cellar/tesseract/<version>/share/tessdata/
- 标准安装:
-
-
设置环境变量TESSDATA_PREFIX
-
Windows:
setx TESSDATA_PREFIX "C:/Program Files/Tesseract-OCR/tessdata" -
Unix系统:
declare -x TESSDATA_PREFIX=/usr/share/tesseract-ocr/5/tessdata -
macOS(通过Homebrew安装):
export TESSDATA_PREFIX=$(brew --prefix tesseract)/share/tessdata
-
注意: 在Windows系统上,这必须在Python外部进行 – 在启动脚本之前。仅仅操作os.environ是不够的!
2. 机器学习表格检测(可选)
本仓库提供了一个可选功能,可以使用各种深度学习模型从表格中解析内容。
pip install "openparse[ml]"
然后使用以下命令下载模型权重
openparse-download
你可以使用以下方式运行解析。
parser = openparse.DocumentParser(
table_args={
"parsing_algorithm": "unitable",
"min_table_confidence": 0.8,
},
)
parsed_nodes = parser.parse(pdf_path)
请注意,我们目前使用table-transformers进行所有表格检测,我们发现其性能不佳。这会对unitable的下游结果产生负面影响。如果你知道更好的模型,请开一个Issue - unitable团队提到他们可能很快也会添加这个功能。
指南
https://github.com/Filimoa/open-parse/tree/main/src/cookbooks
文档
https://filimoa.github.io/open-parse/
赞助商

你的用例需要特殊功能吗?请联系我们。











