
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文
简单的线性注意力语言模型平衡了召回率和吞吐量的权衡。




Based 是一种受恢复注意力类似能力(即召回)启发的高效架构。我们通过结合两个简单的想法来实现这一点:
- 短滑动窗口注意力(例如,窗口大小为 64),用于建模细粒度的局部依赖关系
- "密集"和全局线性注意力,用于建模长程依赖关系
通过这种方式,我们旨在在一个100%次二次方的模型中捕捉与 Transformer 相同的依赖关系,局部使用精确的 softmax 注意力,对所有其他标记使用近似 softmax 的线性注意力。我们发现这有助于缩小 Transformer 和其他次二次方架构提案之间的许多性能差距(匹配困惑度并不是你所需要的全部?)。
发布
- 在此仓库中,您可以找到(1)训练新的 Based 模型和(2)在下游任务上评估现有 Based 检查点的代码。
- 新 使用 ThunderKittens CUDA 内核演示预训练 Based 模型,让它飞起来!!!
安装
**注意:**此仓库中的代码在 python=3.8.18 和 torch=2.1.2 上进行了测试。我们建议在干净的环境中使用这些版本。
# 克隆仓库
git clone git@github.com:HazyResearch/based.git
cd based
# 安装 torch
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118 # 由于观察到的 causal-conv1d 依赖
# 安装 based 包
pip install -e .
# 注意,有时 causal-conv1d 接口会发生变化(https://github.com/state-spaces/mamba/pull/168),以防您遇到错误。
预训练检查点
我们正在发布以下检查点用于研究,在 360M 和 1.3B 参数规模上进行训练。每个检查点都在 Pile 语料库的相同 10B 到 50B 标记(如下所述)上训练,使用相同的数据顺序。这些检查点使用相同的代码和基础设施进行训练。在 notebooks/03-24-quick-start.ipynb 中提供了一个快速入门笔记本,更多详细信息如下:
使用以下代码加载 Based 检查点:
import torch
from transformers import AutoTokenizer
from based.models.gpt import GPTLMHeadModel
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = GPTLMHeadModel.from_pretrained_hf("hazyresearch/based-360m")
| 架构 | 大小 | 标记数 | WandB | HuggingFace | 配置 |
|---|---|---|---|---|---|
| Based | 360m | 10b | 02-20-based-360m | hazyresearch/based-360m | reference/based-360m.yaml |
| Based | 1.4b | 10b | 02-21-based-1b | hazyresearch/based-1b | reference/based-1b.yaml |
| Based | 1.4b | 50b | 03-31-based-1b-50b | hazyresearch/based-1b-50b | reference/based_1.3b_50b_tok.yaml |
| Attention | 360m | 10b | 02-21-attn-360m | hazyresearch/attn-360m | reference/attn-360m.yaml |
| Attention | 1.4b | 10b | 02-25-attn-1b | hazyresearch/attn-1b | reference/attn-360m.yaml |
| Mamba | 360m | 10b | 02-21-mamba-360m | hazyresearch/mamba-360m | reference/mamba-360m.yaml |
| Mamba | 1.4b | 10b | 02-22-mamba-1b | hazyresearch/mamba-1b | reference/mamba-1b.yaml |
| Mamba | 1.4b | 50b | 03-31-mamba-1b-50b | hazyresearch/mamba-1b-50b | reference/mamba-1.3b_50b_tok.yaml |
**警告:**我们发布这些模型是为了进行高效架构研究。由于它们尚未经过指令微调或审核,因此不适用于任何下游应用。
以下代码将为提示生成文本并打印出响应。
input = tokenizer.encode("If I take one more step, it will be", return_tensors="pt").to("cuda")
output = model.generate(input, max_length=20)
print(tokenizer.decode(output[0]))
**注意:**对于其他模型的检查点,您需要安装其他依赖项并使用略有不同的代码。
要加载 Attention 模型,请使用以下代码:
import torch
from transformers import AutoTokenizer
from based.models.transformer.gpt import GPTLMHeadModel
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = GPTLMHeadModel.from_pretrained_hf("hazyresearch/attn-360m").to("cuda")
要使用 Mamba 检查点,首先运行 pip install mamba-ssm,然后使用以下代码:
import torch
from transformers import AutoTokenizer
from based.models.mamba import MambaLMHeadModel
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = MambaLMHeadModel.from_pretrained_hf("hazyresearch/mamba-360m").to("cuda")
训练
按照 based/train/ 中的 README.md 说明训练您自己的 Based 模型!
评估
在我们的论文中,我们在 LM Evaluation Harness 的标准基准套件以及三个召回密集型任务套件上评估预训练语言模型:
- SWDE(信息提取)。一个流行的半结构化数据信息提取基准。SWDE 包括来自 8 个电影和 5 个大学网站(如 IMDB、US News)的原始 HTML 文档,以及每个网站 8-274 个属性的注释(如电影运行时间)。HuggingFace: hazyresearch/based-swde
- FDA(信息提取)。一个流行的非结构化数据信息提取基准。FDA 设置包含 16 个黄金属性和 100 个 PDF 文档,这些文档最长可达 20 页,从 FDA 510(k) 中随机抽样。HuggingFace: hazyresearch/based-fda
- SQUAD-Completion(文档问答)。我们发现,没有指令微调,原始 SQUAD 数据集对我们的模型来说具有挑战性。因此,我们引入了 SQUAD 的修改版本,其中问题被重新措辞为下一个标记预测任务。例如,"法国的首都是什么?"变成了"法国的首都是"。HuggingFace: hazyresearch/based-squad
在 evaluate 下,我们克隆了 EleutherAI 的 lm-evaluation-harness,其中包括这些新任务,并提供了运行论文中所有评估的脚本。以下说明可用于使用预训练检查点在 LM-Eval harness 上重现我们的结果。
设置
cd evaluate
# 初始化子模块并安装
git submodule init
git submodule update
pip install -e .
运行评估
我们提供了一个脚本 evaluate/launch.py,用于启动对我们发布的检查点的评估。
例如,从 evaluate 文件夹运行以下命令将在 SWDE 数据集上评估 360M Based、Mamba 和 Attention 模型。
您可以将您的 huggingface 缓存目录设置为具有足够空间的位置(export TRANSFORMERS_CACHE,export HF_HOME)。
python launch.py \
--task swde --task fda --task squad_completion \
--model "hazyresearch/based-360m" \
--model "hazyresearch/mamba-360m" \
--model "hazyresearch/attn-360m" \
--model "hazyresearch/based-1b" \
--model "hazyresearch/mamba-1b" \
--model "hazyresearch/attn-1b"
如果您可以访问多个 GPU,您可以传递 -p 标志以在不同的 GPU 上运行每个评估。
要为每个任务运行有限数量的样本(例如 100),请使用 --limit=100 选项。
以下是运行上述命令得到的结果。注意:下面的结果是使用本仓库中经过清理的代码训练和评估的新模型得出的。因此,我们论文中报告的结果略有不同,但趋势和结论保持不变。
| 架构 | 大小 | HuggingFace | SWDE | FDA | SQUAD |
|---|---|---|---|---|---|
| Based | 360m | hazyresearch/based-360m | 25.65 | 14.34 | 24.23 |
| Mamba | 360m | hazyresearch/mamba-360m | 17.28 | 5.90 | 24.83 |
| Attention | 360m | hazyresearch/attn-360m | 56.26 | 57.89 | 27.85 |
| Based | 1.4b | hazyresearch/attn-1b | 37.71 | 19.06 | 29.49 |
| Mamba | 1.4b | hazyresearch/attn-1b | 28.35 | 11.07 | 29.42 |
| Attention | 1.4b | hazyresearch/attn-1b | 69.04 | 68.87 | 35.89 |
请注意,如果在推理过程中不使用Flash-Attention内核,显示的结果可能会略有不同。
合成数据实验
在我们的论文中,我们使用合成联想回忆任务展示了召回率-吞吐量的权衡(见下图2和论文中的图3)。
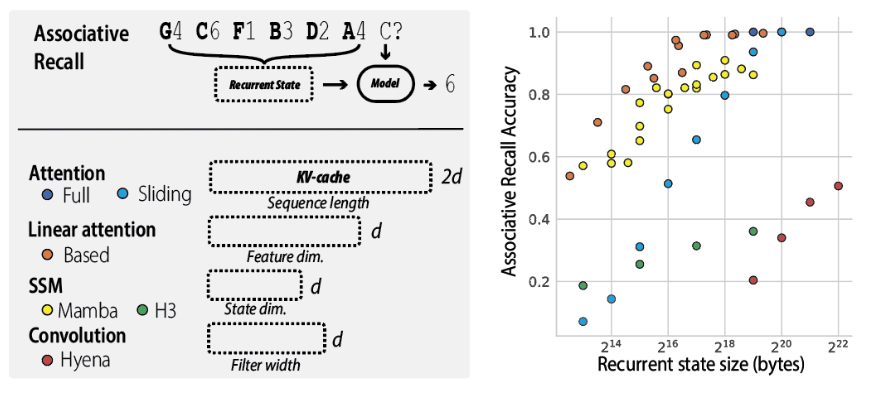
reproducing这些图表的代码在另一个仓库中提供:HazyResearch/zoology。请按照Zoology README中的设置说明进行操作。reproducing的说明在zoology/experiments中提供。例如,你可以使用以下命令创建上面的图表:
python -m zoology.launch zoology/experiments/arxiv24_based_figure2/configs.py -p
基准测试和效率
尝试使用快速ThunderKittens内核的Based模型!
git submodule init
git submodule update
cd ThunderKittens/demos/based_demos
尽情享受!
引用和致谢
本仓库包含基于以下论文的工作。如果你发现这些工作或代码有用,请考虑引用:
@article{arora2024simple,
title={Simple linear attention language models balance the recall-throughput tradeoff},
author={Arora, Simran and Eyuboglu, Sabri and Zhang, Michael and Timalsina, Aman and Alberti, Silas and Zinsley, Dylan and Zou, James and Rudra, Atri and Ré, Christopher},
journal={arXiv:2402.18668},
year={2024}
}
@article{zhang2024hedgehog,
title={The Hedgehog \& the Porcupine: Expressive Linear Attentions with Softmax Mimicry},
author={Zhang, Michael and Bhatia, Kush and Kumbong, Hermann and R{\'e}, Christopher},
journal={arXiv preprint arXiv:2402.04347},
year={2024}
}
@article{arora2023zoology,
title={Zoology: Measuring and Improving Recall in Efficient Language Models},
author={Arora, Simran and Eyuboglu, Sabri and Timalsina, Aman and Johnson, Isys and Poli, Michael and Zou, James and Rudra, Atri and Ré, Christopher},
journal={arXiv:2312.04927},
year={2023}
}
本项目得以实现要感谢许多其他开源项目;如果你使用了他们的工作,请引用!特别是:
- 我们的训练代码和滑动窗口实现基于Tri Dao的FlashAttention。
- 我们使用EleutherAI的lm-evaluation-harness进行评估。
- 我们使用Mamba中的conv1d内核。
- 我们集成了Fast Transformers的因果点积内核。
- 我们集成了Flash Linear Attention的based内核。
本项目中的模型使用以下提供的计算资源进行训练:
- Together.ai
- 通过Stanford HAI提供的Google Cloud Platform
如有反馈和问题,请随时联系我们!











