
 访问官网
访问官网 Github
Github 文档
文档 论文
论文llmc: 实现精准高效的大语言模型压缩
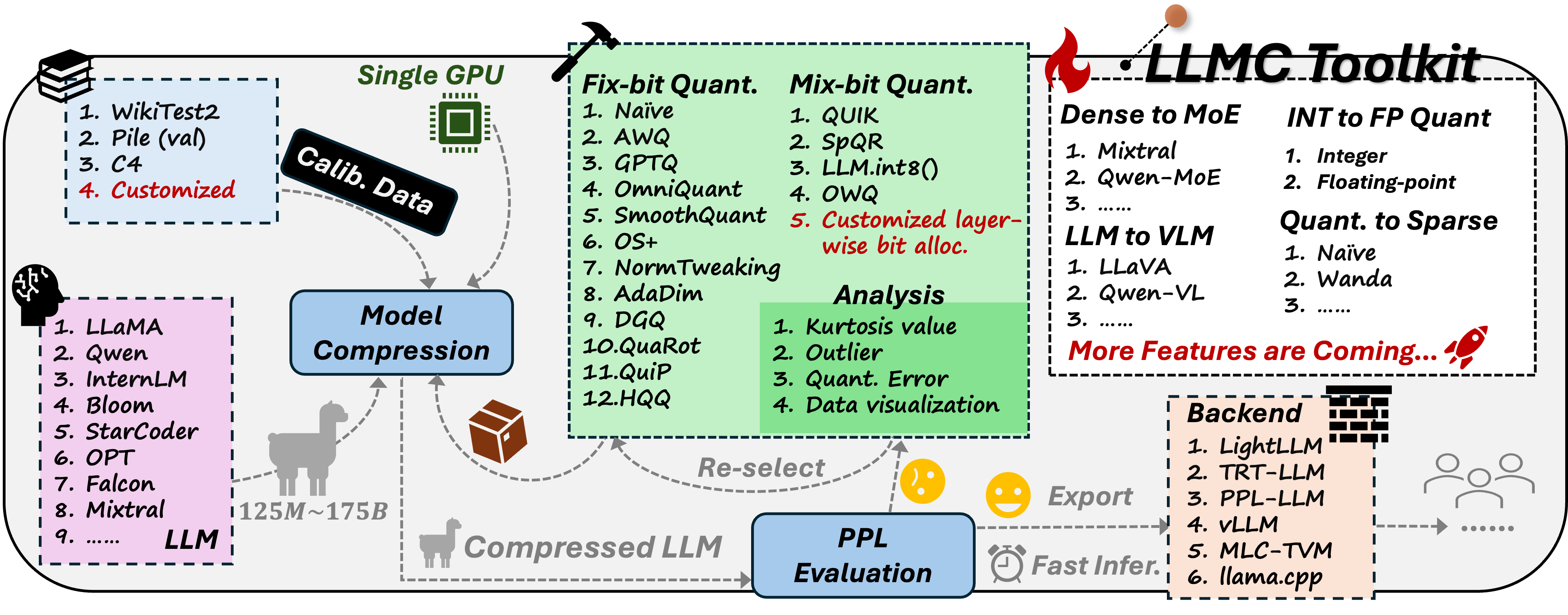



llmc 是一款现成的大语言模型压缩工具,利用最先进的压缩算法提高效率并减小模型大小,同时保持性能不受影响。
英文文档请点击这里。
中文文档请点击这里。
社区:
新闻
-
2024年8月22日: 🔥我们支持了大量小型语言模型,包括当前最先进的 SmolLM(参见支持的模型列表)。此外,我们还通过修改后的 lm-evaluation-harness 支持下游任务评估 🤗。具体来说,用户可以首先使用
save_trans模式(参见配置中的save部分)保存修改后的权重模型。获得转换后的模型后,他们可以直接参考 run_lm_eval.sh 评估量化后的模型。更多详情可以在这里找到。 -
2024年7月23日: 🍺🍺🍺 我们发布了全新版本的基准论文:
LLMC:使用多功能压缩工具包对大型语言模型量化进行基准测试。
龚瑞昊*、杨勇*、顾世桥*、黄宇实*、吕成涛、张运宸、刘祥龙📧、陶大程
(* 表示贡献相同,📧 表示通讯作者。)

我们不仅仅关注最佳实践,而是从校准数据、算法和数据格式等方面对LLM量化进行模块化和公平的基准测试。通过详细的观察和分析,我们在不同配置下为性能和方法改进提供了各种新颖的见解。借助强大的LLMC工具包和全面的洞察,未来的LLM研究人员可以为其应用高效地集成合适的算法和低位格式,从而实现大型语言模型压缩的民主化。
-
2024年7月16日: 🔥我们现在支持Wanda/Naive(Magnitude)用于LLM稀疏化和逐层混合位量化!
-
2024年7月14日: 🔥我们现在支持基于旋转的量化算法QuaRot!
-
2024年7月4日: 📱 我们开放了讨论渠道。如果您有任何问题,请加入我们的社区:
-
2024年5月17日: 🚀 我们现在支持一些先进的大型模型,如LLaVA、Mixtral、LLaMA V3和Qwen V2。欢迎尝试!
-
2024年5月13日: 🍺🍺🍺 我们发布了量化基准测试论文:
LLM-QBench: 大型语言模型后训练量化最佳实践的基准测试。
龚瑞昊*、杨勇*、顾世桥*、黄宇时*、张云辰、刘祥龙📧、陶大程
(* 表示贡献相同, 📧 表示通讯作者。)
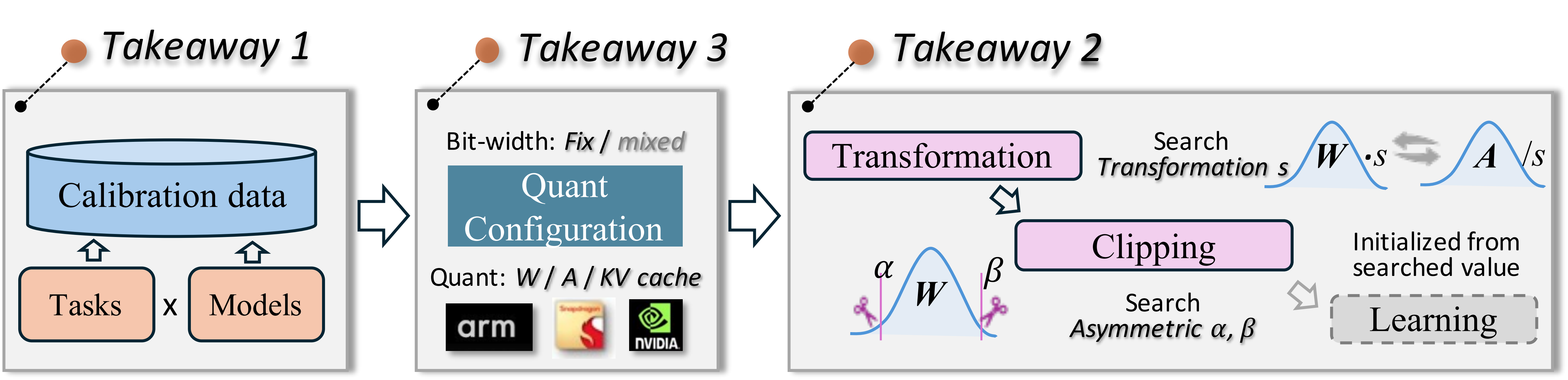
我们从校准成本、推理效率和量化精度等方面对量化技术进行了模块化和公平的基准测试。在不同模型和数据集上进行的近600次实验提供了三个有见地的结论,涉及校准数据、算法流程和量化配置选择。基于这些结论,我们设计了LLM PTQ流程的最佳实践,以在各种场景下实现精度和效率性能的最佳平衡。
-
2024年3月7日: 🚀 我们发布了一个强大高效的LLM压缩工具的量化部分。值得注意的是,我们的基准测试论文即将发布😊。
亮点功能
- 在仅一张A100/H100/H800 GPU上量化LLM(如Llama2-70B、OPT-175B)并评估其PPL💥。
- 提供多种最先进的压缩算法与原始仓库保持一致供用户选择,用户可以在一个LLM上顺序使用多种算法💥。
- 我们工具导出的经特定压缩算法处理的转换模型(
quant部分的save_trans模式,见配置)可通过多个后端(如Lightllm、TensorRT-LLM)进行简单量化,得到经特定压缩算法优化的模型,该模型可由相应后端进行推理💥。 - 我们压缩后的模型(
quant部分的save_lightllm模式,见配置)具有浅层内存占用,可直接由Lightllm进行推理💥。
使用方法
-
克隆此仓库并安装包:
# 安装包 cd llmc pip install -r requirements.txt -
准备模型和数据。
# 从huggingface下载LLM后,按如下方式准备校准和评估数据: cd tools python download_calib_dataset.py --save_path [校准数据路径] python download_eval_dataset.py --save_path [评估数据路径] -
选择一种算法来量化您的模型:
# 以下是关于Awq的示例:
cd scripts
# 修改bash文件中的llmc路径,即``llmc_path``。您还可以选择位于``llmc/configs/quantization/Awq/``中的一个配置
# 来量化您的模型,或者通过更改run_awq_llama.sh中的``--config``参数来参考我们提供的配置创建您自己的配置。
bash run_awq_llama.sh
配置
为了帮助用户设计他们的配置,我们现在解释一下llmc/configs/下所有配置中的一些通用配置:
-
model:model: # 替换为``llmc/models/*.py``中的类名。 type: Llama # 替换为您的模型路径。 path: 模型路径 torch_dtype: auto -
calib:# 注意:某些算法不需要``calib``,比如naive...因此,您可以删除这部分。 calib: # 替换为校准数据名称,例如之前下载的pileval、c4、wikitext2或ptb。 name: pileval download: False # 替换为之前下载的校准数据路径,例如pileval、c4、wikitext2或ptb。 path: 校准数据路径 n_samples: 128 bs: -1 seq_len: 512 # 替换为``llmc/data/dataset/specified_preproc.py``中的函数名。 preproc: general seed: *seed -
eval:# 如果您想评估预训练/转换/伪量化模型的PPL。 eval: # 您可以评估预训练、转换、伪量化模型,并设置您想评估的位置。 eval_pos: [pretrain, transformed, fake_quant] # 替换为评估数据的名称,例如之前下载的c4、wikitext2、ptb或[c4, wikitext2]。 name: wikitext2 download: False path: 评估数据路径 # 对于70B模型评估,bs可以设置为20,inference_per_block可以设置为True。 # 对于7B / 13B模型评估,bs可以设置为1,inference_per_block可以设置为False。 bs: 1 inference_per_block: False seq_len: 2048 -
save:save: # ``save_trans``为True,表示您想导出转换后的模型,例如参数修改后的 # 模型,其性能和结构与原始模型相同,用户可以 # 对转换后的模型进行简单量化,以获得与 # 特定算法量化模型相同的性能。 save_trans: False # ``save_lightllm``或``save_trtllm``为True,表示您想导出真实量化模型,例如 # 低位权重以及权重和激活量化参数。 save_lightllm: False # ``save_fake``为True表示您想导出伪量化模型,例如 # 反量化权重和激活量化参数。 save_fake: False save_path: ./save -
quant:quant: # 替换为``llmc/compression/quantization/*.py``中的类名 method: OmniQuant # 仅权重量化没有``act``部分。 weight: bit: 8 symmetric: True # 量化粒度:per_channel、per_tensor、per_head(不推荐)。 granularity: per_channel group_size: -1 # 校准算法:learnble、mse和minmax(默认)。 calib_algo: learnable # 使用直通估计,这对于可学习的校准算法是必要的。 ste: True act: bit: 8 symmetric: True # 量化粒度:per_token、per_tensor granularity: per_token ste: True # 静态量化(校准期间量化)或动态量化(推理期间量化)。 static: True # 这部分是为特定算法设计的,用户可以参考 # 我们提供的来设计自己的。 special: let: True lwc_lr: 0.01 let_lr: 0.005 use_shift: False alpha: 0.5 deactive_amp: True epochs: 20 wd: 0 # 如果quant_out为True,则使用前一个量化块的输出作为 # 后续块的校准数据。 quant_out: True
支持的模型列表
✅ BLOOM
✅ LLaMA
✅ LLaMA V2
✅ OPT
✅ Falcon
✅ Mixtral
✅ Qwen V2
✅ LLaVA
✅ StableLM
✅ Gemma2
✅ Phi2
✅ Phi 1.5
✅ MiniCPM
✅ SmolLM
您可以参考llmc/models/*.py下的文件添加自己的模型类型。
支持的算法列表
量化
✅ 朴素量化
✅ AWQ
✅ GPTQ
✅ OS+
✅ AdaDim
✅ QUIK
✅ SpQR
✅ DGQ
✅ OWQ
✅ HQQ
✅ QuaRot
剪枝
✅ 朴素剪枝(幅度)
✅ Wanda
✅ ShortGPT
致谢
我们的代码开发参考了以下仓库:
- https://github.com/mit-han-lab/llm-awq
- https://github.com/mit-han-lab/smoothquant
- https://github.com/OpenGVLab/OmniQuant
- https://github.com/IST-DASLab/gptq
- https://github.com/ModelTC/Outlier_Suppression_Plus
- https://github.com/IST-DASLab/QUIK
- https://github.com/Vahe1994/SpQR
- https://github.com/ilur98/DGQ
- https://github.com/xvyaward/owq
- https://github.com/TimDettmers/bitsandbytes
- https://github.com/mobiusml/hqq
- https://github.com/spcl/QuaRot
- https://github.com/locuslab/wanda
- https://github.com/EleutherAI/lm-evaluation-harness
Star历史
引用
如果您发现我们的LLM-QBench论文/llmc工具包对您的研究有用或相关,请引用我们的论文:
@misc{llmc,
author = {llmc contributors},
title = {llmc: Towards Accurate and Efficient LLM Compression},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/ModelTC/llmc}},
}
@misc{gong2024llmqbench,
title={LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models},
author={Ruihao Gong and Yang Yong and Shiqiao Gu and Yushi Huang and Yunchen Zhang and Xianglong Liu and Dacheng Tao},
year={2024},
eprint={2405.06001},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{gong2024llmcbenchmarkinglargelanguage,
title={LLMC: Benchmarking Large Language Model Quantization with a Versatile Compression Toolkit},
author={Ruihao Gong and Yang Yong and Shiqiao Gu and Yushi Huang and Chentao Lv and Yunchen Zhang and Xianglong Liu and Dacheng Tao},
year={2024},
eprint={2405.06001},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2405.06001},
}











