
 Github
Github 论文
论文  HippoRAG
HippoRAG
神经生物学启发的长期记忆
用于大型语言模型
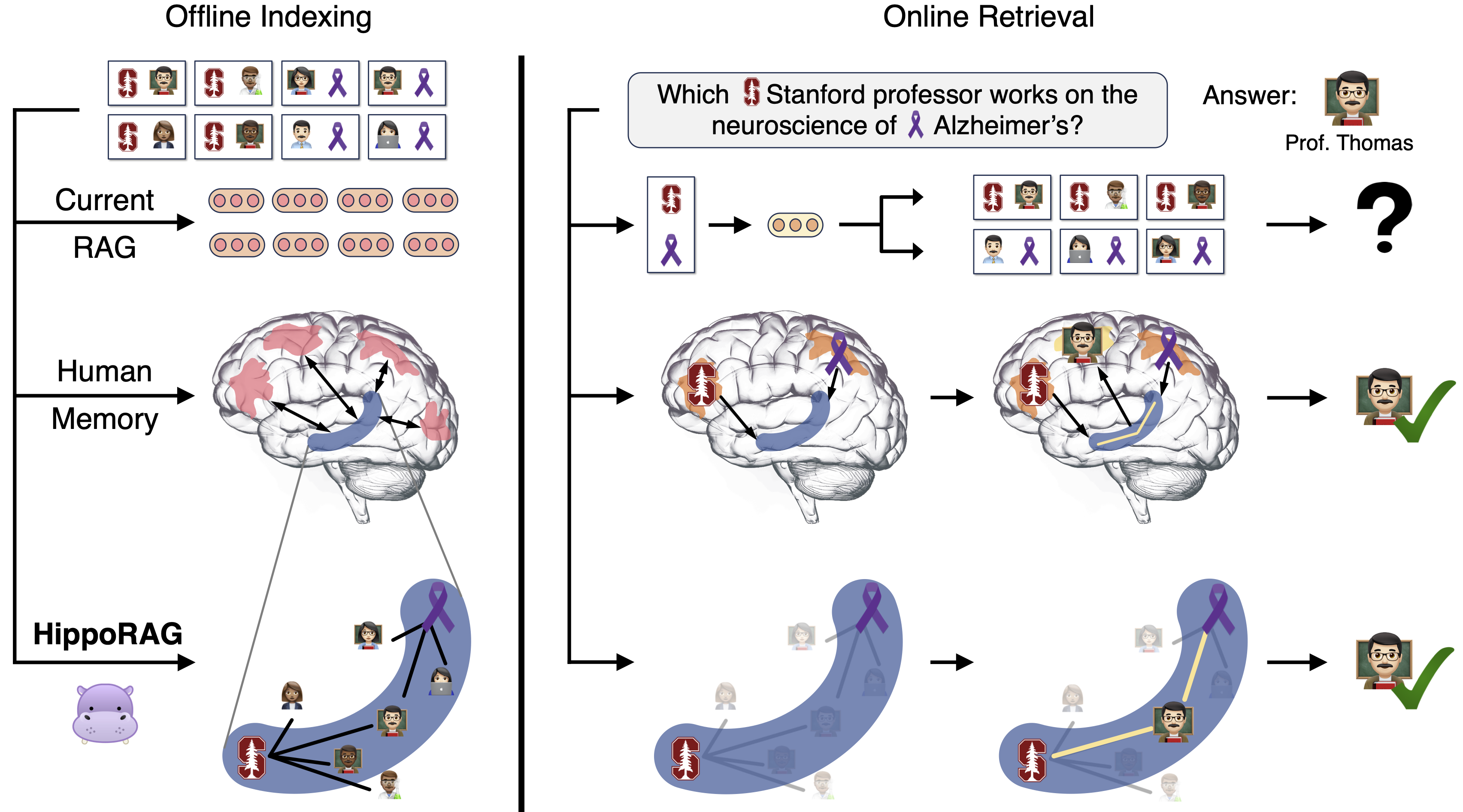
HippoRAG 是一个受人类长期记忆神经生物学启发的新型检索增强生成 (RAG) 框架,使大型语言模型能够持续整合外部文档中的知识。我们的实验表明,HippoRAG 可以为 RAG 系统提供通常需要昂贵且高延迟的迭代 LLM 流程才能实现的功能,而计算成本仅为其一小部分。
欲了解更多详情,请查看我们的论文!
设置环境
创建 conda 环境并安装依赖:
conda create -n hipporag python=3.9
conda activate hipporag
pip install -r requirements.txt
GPUS=0,1,2,3 #替换为您自己的可用 GPU 设备
将 conda 环境添加到 PATH,如下所示,其中 /path/HippoRAG 是 HippoRAG 的根目录,/path/HippoRAG/hipporag 是 conda 环境的路径。考虑将此添加到您的 ~/.bashrc 中
export PATH=$PATH:/path/HippoRAG/hipporag/bin
设置 LLM API 密钥:TOGETHER_API_KEY 是可选的,当您想使用他们的开源模型(如 Llama-3)时设置它。
export OPENAI_API_KEY='在此添加您自己的 OpenAI API 密钥。'
export TOGETHER_API_KEY='在此添加您自己的 TogetherAI API 密钥。'
要使用 ColBERTv2,下载预训练的检查点并将其放在 exp/colbertv2.0 下。
cd exp
wget https://downloads.cs.stanford.edu/nlp/data/colbert/colbertv2/colbertv2.0.tar.gz
tar -xvzf colbertv2.0.tar.gz
cd .. # 返回根目录
使用 HippoRAG
注意,以下命令的工作目录为 HippoRAG 根目录。
设置您的数据
要设置您自己的检索语料库,请按照 data/sample_corpus.json 中显示的格式和命名约定(您的数据集名称后应跟 _corpus.json)。如果要运行预定义问题的实验,请根据查询文件 data/sample.json 组织您的查询语料库,务必同样遵循我们的命名约定。
语料库和可选查询 JSON 文件应具有以下格式:
检索语料库 JSON
[
{
"title": "第一段落标题",
"text": "第一段落文本",
"idx": 0
},
{
"title": "第二段落标题",
"text": "第二段落文本",
"idx": 1
}
]
(可选)查询 JSON
[
{
"id": "sample/question_1.json",
"question": "问题",
"answer": [
"答案"
],
"answerable": true,
"paragraphs": [
{
"title": "{第一个支持段落标题}",
"text": "{第一个支持段落文本}",
"is_supporting": true,
"idx": 0
},
{
"title": "{第二个支持段落标题}",
"text": "{第二个支持段落文本}",
"is_supporting": true,
"idx": 1
}
]
}
]
(可选)分段语料库
在准备语料库数据时,您可能需要对每个段落进行分段,因为较长的段落可能对 OpenIE 过程来说过于复杂。如果需要,请查看 src/data_process/util.py 以对整个语料库进行分段。
与 LangChain 集成
此代码库通过 LangChain 调用 LLM,这使得 HippoRAG 更容易调用不同的在线 LLM API 或离线 LLM 部署。
查看 src/langchain_util.py 以了解我们如何为实验设置 OpenAI 和 TogetherAI。您还可以使用 LangChain 设置自己的 LLM 选择,例如,Ollama 支持本地的 Llama、Gemma 和 Mistral 模型。
索引
一旦创建了语料库,将其添加到 data 目录下。现在我们准备使用以下命令开始索引。
我们将使用论文中定义的最佳超参数,并假设您的数据集名称为 sample。
对于以下命令,您不必同时使用 ColBERTv2 和 Contriever 进行索引。根据您的偏好选择其中一个。
使用 ColBERTv2 为同义边索引
DATA=sample
LLM=gpt-3.5-turbo-1106
SYNONYM_THRESH=0.8
GPUS=0,1,2,3
LLM_API=openai # LLM API 提供商,例如 'openai'、'together',见 'src/langchain_util.py'
bash src/setup_hipporag_colbert.sh $DATA $LLM $GPUS $SYNONYM_THRESH $LLM_API
使用 HuggingFace 检索编码器为同义边索引(即 Contriever)
DATA=sample
HF_RETRIEVER=facebook/contriever
LLM=gpt-3.5-turbo-1106
SYNONYM_THRESH=0.8
GPUS=0,1,2,3
LLM_API=openai # LLM API 提供商,例如 'openai'、'together',见 'src/langchain_util.py'
bash src/setup_hipporag.sh $DATA $HF_RETRIEVER $LLM $GPUS $SYNONYM_THRESH $LLM_API
检索
索引后,HippoRAG 已准备好协助在线检索。以下我们提供了两种使用 HippoRAG 的策略:
- 对一组预定义查询进行检索。
- 直接与我们的 API 集成以接收用户的查询。
预定义查询
要对上述格式的特定预定义查询集进行检索,我们根据您想使用的检索主干运行以下命令之一:
ColBERTv2
RETRIEVER=colbertv2
python3 src/ircot_hipporag.py --dataset $DATA --retriever $RETRIEVER --llm $LLM_API --llm_model $LLM --max_steps 1 --doc_ensemble f --top_k 10 --sim_threshold $SYNONYM_THRESH --damping 0.5
Huggingface 模型(即 Contriever)
RETRIEVER=$HF_RETRIEVER
python3 src/ircot_hipporag.py --dataset $DATA --retriever $RETRIEVER --llm $LLM_API --llm_model $LLM --max_steps 1 --doc_ensemble f --top_k 10 --sim_threshold $SYNONYM_THRESH --damping 0.5
注意: 在此设置中,您可以将 HippoRAG 与 IRCoT 结合以获得互补的改进。要运行此操作,只需将上面的 --max_steps 参数更改为所需的最大 LLM 推理步骤数。此外,请确保在 data/ircot_prompt/ 下创建一个以您数据集名称命名的目录,并添加一个名为 gold_with_3_distractors_context_cot_qa_codex.txt 的文件,其中包含适用于您数据集的 IRCoT 提示。查看其他数据集的 IRCoT 提示以获取格式和内容灵感。
HippoRAG 集成
我们在 src/test_hipporag.py 中提供了一个示例,以指导希望将 HippoRAG API 直接集成到他们代码库中的用户。
from src.langchain_util import LangChainModel
from src.qa.qa_reader import qa_read
import argparse
from src.hipporag import HippoRAG
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', type=str, required=True, default='sample')
parser.add_argument('--extraction_model', type=str, default='gpt-3.5-turbo-1106')
parser.add_argument('--retrieval_model', type=str, required=True, help='例如 "facebook/contriever", "colbertv2"')
parser.add_argument('--doc_ensemble', action='store_true')
parser.add_argument('--dpr_only', action='store_true')
args = parser.parse_args()
assert not (args.doc_ensemble and args.dpr_only)
hipporag = HippoRAG(args.dataset, 'openai', args.extraction_model, args.retrieval_model, doc_ensemble=args.doc_ensemble, dpr_only=args.dpr_only,
qa_model=LangChainModel('openai', 'gpt-3.5-turbo'))
queries = ["哪位斯坦福大学教授在研究阿尔茨海默症"]
# qa_few_shot_samples = [{'document': '', 'question': '', 'thought': '', 'answer': ''}]
# 准备一个用于少样本 QA 的列表,其中每个元素是一个包含 'document'、'question'、'thought'、'answer' 键的字典('document' 和 'thought' 是可选的)
qa_few_shot_samples = None
对于每个查询:
排名、分数、日志 = hipporag.给文档排名(查询, 前k个=10)
检索到的段落 = [hipporag.通过索引获取段落(排名) for 排名 in 排名列表]
回复 = qa_阅读(查询, 检索到的段落, qa少量样本, hipporag.qa模型)
打印(排名)
打印(分数)
打印(回复)
要初始化HippoRAG类的实例,只需选择一个**LLM**和一个**检索编码器模型**,这些模型你之前已用于为检索数据集建立索引。
### 自定义数据集演示
要在自定义数据集上运行HippoRAG,请按照上述步骤进行索引和检索,同时还要添加数据处理和评估。以下是[BEIR](https://arxiv.org/abs/2104.08663)数据集的示例,请参见`src/data_process`和`src/demo`。
## 论文复现
在本节中,你将找到复现[我们论文](https://arxiv.org/abs/2405.14831)中所示结果所需的所有代码。
### 数据
我们提供了复现我们实验所需的所有必要数据。
为了在复现过程中节省成本和时间,我们还包括了通过GPT-3.5 Turbo (1106)、两个Llama-3模型和REBEL在所有三个子集和超参数调优数据集上生成的知识图谱。我们还包括了通过GPT-3.5 Turbo (1106)在所有数据集上获得的NER结果。
### 基线
更多详情请查看`src/baselines/README.md`。
### 运行HippoRAG
使用我们的HippoRAG框架需要两个步骤:索引和检索。
#### 索引
要为我们的主要实验和消融实验运行索引,请运行以下bash脚本。如果此步骤未成功,检索将失败。
```shell
bash src/setup_hipporag_main_exps.sh $GPUS
HippoRAG检索
运行索引后,运行以下bash脚本以使用HippoRAG和Contriever及ColBERTv2测试单步和多步检索。
仅HippoRAG
bash src/run_hipporag_main_exps.sh
HippoRAG与IRCoT
bash src/run_hipporag_ircot_main_exps.sh
消融实验
要运行所有消融实验,请运行以下bash脚本:
bash src/setup_hipporag_ablations.sh $GPUS
bash src/run_hipporag_ablations.sh
超参数调优
要复现我们的超参数调优,我们必须首先通过运行以下脚本在MuSiQue训练子集上运行索引:
bash src/setup_hipporag_hyperparameter_tune.sh $GPUS
索引完成后,运行以下脚本并记录测试的每个超参数组合的性能。
bash src/run_hipporag_hyperparameter_tune.sh
问答
更多详情请查看src/qa/README.md。运行QA只能在运行基线和HippoRAG的检索之后进行,因为它使用检索的输出。
路径查找多跳QA案例研究
要运行我们论文中展示的案例研究示例(我们也包括在数据目录中),请运行以下脚本。请注意,要运行这些示例,需要设置你自己的OpenAI API密钥。
索引
bash src/setup_hipporag_case_study.sh $GPUS
检索
bash src/run_hipporag_case_study.sh
运行这些之后,你可以在output/ircot/目录中探索输出。
待办事项
- 本地部署的LLM
- 提示灵活性
- 支持图形数据库,如Neo4j
- 图的读/写API
联系
有问题或问题?提交一个issue或联系 Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Su, 俄亥俄州立大学
引用
如果你觉得这项工作有用,请考虑引用我们的论文:
@article{gutiérrez2024hipporag,
title={HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models},
author={Bernal Jiménez Gutiérrez and Yiheng Shu and Yu Gu and Michihiro Yasunaga and Yu Su},
journal={arXiv preprint arXiv:2405.14831},
year={2024},
url={https://arxiv.org/abs/2405.14831}
}











