
 Github
Github Huggingface
Huggingface 论文
论文
简介
欢迎来到InfiniteBench,这是一个尖端基准测试,专门用于评估语言模型处理、理解和推理超长上下文(10万个以上标记)的能力。长上下文对于增强大型语言模型的应用和实现高级交互至关重要。InfiniteBench旨在通过测试10万个以上标记的上下文长度来突破语言模型的界限,这是传统数据集长度的10倍。
特点
- 超长上下文: InfiniteBench在测试10万个以上标记上下文长度的语言模型方面开创先河,为该领域提供了无与伦比的挑战。
- 多样化领域: 该基准测试包含12个独特任务,每个任务都旨在评估延长上下文中语言处理和理解的不同方面。
- 专门测试: InfiniteBench包含的任务是已知最先进的大型语言模型在使用较短上下文时能够胜任的。这确保了性能下降仅由上下文长度引起。
- 真实和合成场景: 任务混合了真实世界场景和合成构造,确保对模型进行全面评估。真实世界场景使测试更加实用,而合成场景则为进一步延长上下文长度留下了空间。
任务组成
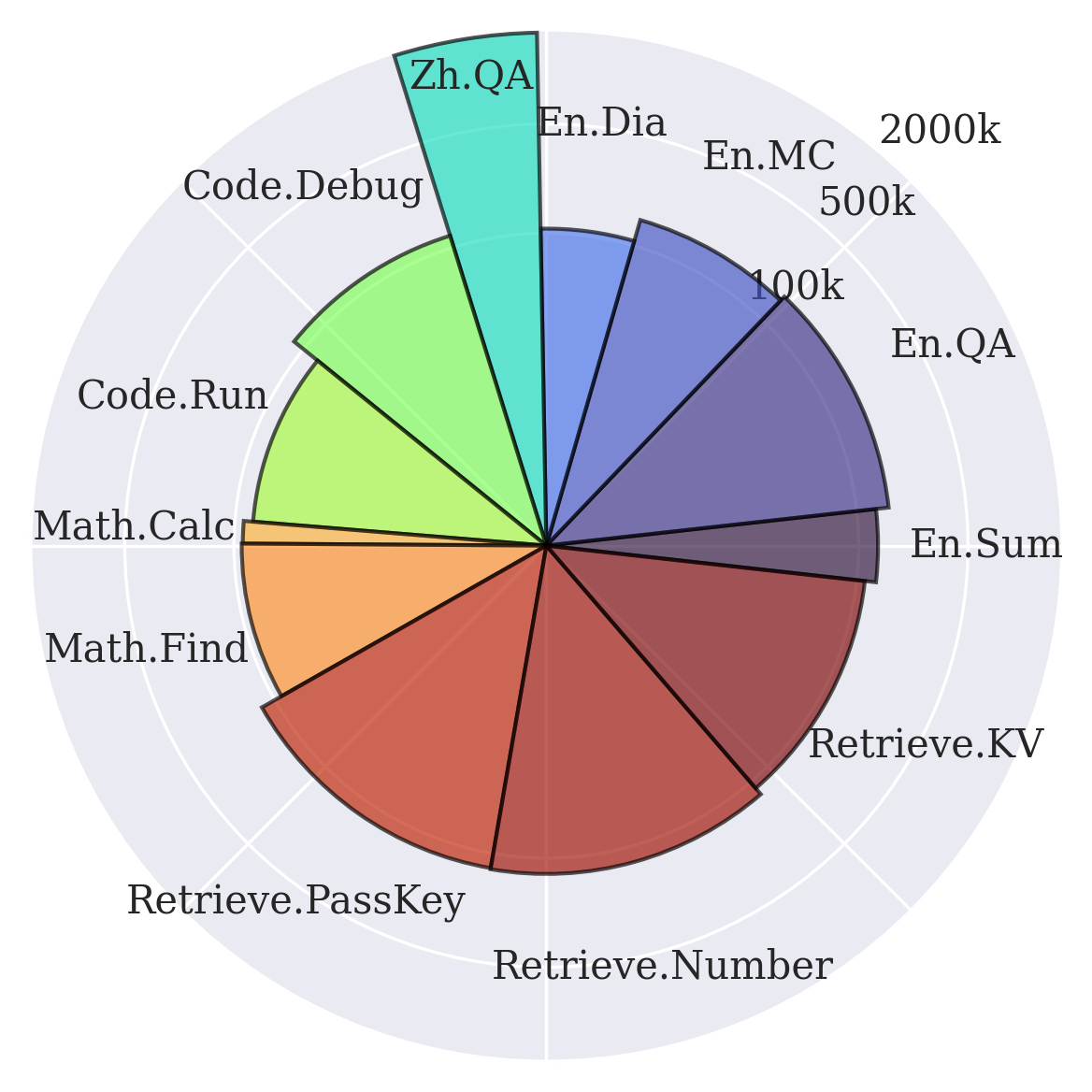
| 任务名称 | 上下文 | 示例数量 | 平均输入标记数 | 平均输出标记数 | 描述 |
|---|---|---|---|---|---|
| En.Sum | 虚构书籍 | 103 | 171.5k | 1.1k | 通过核心实体替换创建的虚构书籍摘要 |
| En.QA | 虚构书籍 | 351 | 192.6k | 4.8 | 基于虚构书籍的自由形式问答 |
| En.MC | 虚构书籍 | 229 | 184.4k | 5.3 | 源自虚构书籍的多项选择题 |
| En.Dia | 剧本 | 200 | 103.6k | 3.4 | 在部分匿名化的剧本中识别说话者 |
| Zh.QA | 新书 | 175 | 2068.6k | 6.3 | 基于新收集的一组书籍进行问答 |
| Code.Debug | 代码文档 | 394 | 114.7k | 4.8 | 找出代码仓库中包含崩溃错误的函数(以多项选择形式呈现) |
| Code.Run | 合成 | 400 | 75.2k | 1.3 | 模拟执行多个简单的合成函数 |
| Math.Calc | 合成 | 50 | 43.9k | 43.9k | 涉及超长算术方程的计算 |
| Math.Find | 合成 | 350 | 87.9k | 1.3 | 在冗长列表中查找特殊整数 |
| Retrieve.PassKey1 | 合成 | 590 | 122.4k | 2.0 | 在嘈杂的长上下文中检索隐藏的密钥 |
| Retrieve.Number | 合成 | 590 | 122.4k | 4.0 | 在嘈杂的长上下文中定位重复的隐藏数字 |
| Retrieve.KV2 | 合成 | 500 | 89.9k | 22.7 | 从字典和键中找到对应的值 |
如何下载数据
点击这里直接从🤗 Huggingface下载数据:https://huggingface.co/datasets/xinrongzhang2022/InfiniteBench
使用🤗 Datasets
或者,您可以使用🤗 Datasets库按如下方式下载。
from datasets import load_dataset
dataset = load_dataset("xinrongzhang2022/InfiniteBench")
使用脚本
cd InfiniteBench
bash scripts/download_dataset.sh
这将直接将数据下载到data目录。
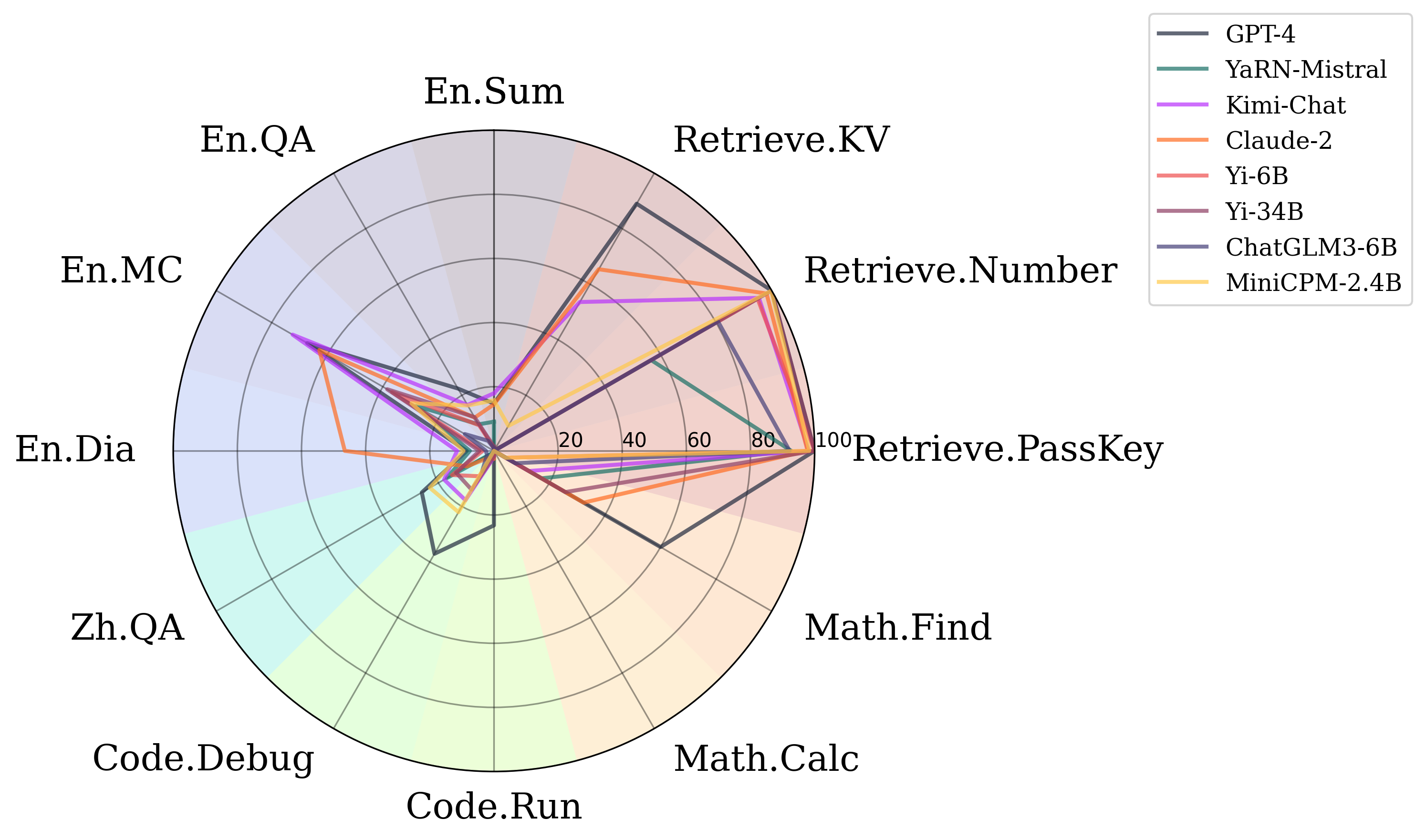
评估结果
我们对最先进的专有和开源大型语言模型进行了评估,结果如下。
| 任务名称 | GPT-4 | YaRN-Mistral-7B | Kimi-Chat | Claude 2 | Yi-6B-200K | Yi-34B-200K | Chatglm3-6B-128K |
|---|---|---|---|---|---|---|---|
| 检索.密码 | 100% | 92.71% | 98.14% | 97.80% | 100.00% | 100.00% | 92.20% |
| 检索.数字 | 100% | 56.61% | 95.42% | 98.14% | 94.92% | 100.00% | 80.68% |
| 检索.键值 | 89.00% | < 5% | 53.60% | 65.40% | < 5% | < 5% | < 5% |
| 英文.总结 | 14.73% | 9.09% | 17.96% | 14.50% | < 5% | < 5% | < 5% |
| 英文.问答 | 22.44% | 9.55% | 16.52% | 11.97% | 9.20% | 12.17% | < 5% |
| 英文.多选 | 67.25% | 27.95% | 72.49% | 62.88% | 36.68% | 38.43% | 10.48% |
| 英文.对话 | 8.50% | 7.50% | 11.50% | 46.50% | < 5% | < 5% | < 5% |
| 中文.问答 | 25.96% | 16.98% | 17.93% | 9.64% | 15.07% | 13.61% | < 5% |
| 代码.调试 | 37.06% | < 5% | 17.77% | < 5% | 9.14% | 13.96% | 7.36% |
| 代码.运行 | 23.25% | < 5% | < 5% | < 5% | < 5% | < 5% | < 5% |
| 数学.计算 | < 5% | < 5% | < 5% | < 5% | < 5% | < 5% | < 5% |
| 数学.查找 | 60.00% | 17.14% | 12.57% | 32.29% | < 5% | 25.71% | 7.71% |
注意:
-
YaRN-Mistral-7B的评估代码是我们自己实现的,如有任何问题,请联系我们或提交问题。
-
Kimi-Chat、Claude 2和GPT-4使用官方API的默认配置进行评估。
-
对于数学.计算任务,括号中的值以0.01%为测量单位。这是因为在这个任务中很容易得到非常低的分数。
-
数学.查找、数学.计算、代码.运行、代码.调试、英文.对话、英文.多选、检索.键值、检索.数字和检索.密码任务的评估指标是准确率;
中文.问答和英文.问答任务的评估指标是ROUGE F1分数;
英文.总结任务的评估指标是来自🤗 Evaluate库的
rougeLsum分数。
安装
pip install -r requirements.txt
如何运行
将数据集下载到data文件夹(或通过--data_dir参数设置数据集的位置)。数据文件夹结构应如下所示:
InfiniteBench
├── data
│ ├── code_debug.jsonl
│ ├── code_run.jsonl
│ ├── kv_retrieval.jsonl
│ ├── longbook_choice_eng.jsonl
│ ├── longbook_qa_chn.jsonl
│ ├── longbook_qa_eng.jsonl
│ ├── longbook_sum_eng.jsonl
│ ├── longdialogue_qa_eng.jsonl
│ ├── math_calc.jsonl
│ ├── math_find.jsonl
│ ├── number_string.jsonl
│ ├── passkey.jsonl
│ └── construct_synthetic_dataset.py
...
然后,在src文件夹中执行:
python eval_yarn_mistral.py --task kv_retrieval
python eval_gpt4.py --task longbook_sum_qa
python eval_rwkv.py --task passkey
可用的任务有:
| 任务名称 | 在--task中指定的参数 |
|---|---|
| 英文.总结 | longbook_sum_qa |
| 英文.问答 | longbook_qa_eng |
| 英文.多选 | longbook_choice_eng |
| 英文.对话 | longdialogue_qa_eng |
| 中文.问答 | longbook_qa_chn |
| 代码.调试 | code_debug |
| 代码.运行 | code_run |
| 数学.计算 | math_calc |
| 数学.查找 | math_find |
| 检索.密码 | passkey |
| 检索.数字 | number_string |
| 检索.键值 | kv_retrieval |
引用
这将在我们的预印本论文发布后更新。
@misc{zhang2024inftybench,
title={$\infty$Bench: Extending Long Context Evaluation Beyond 100K Tokens},
author={Xinrong Zhang and Yingfa Chen and Shengding Hu and Zihang Xu and Junhao Chen and Moo Khai Hao and Xu Han and Zhen Leng Thai and Shuo Wang and Zhiyuan Liu and Maosong Sun},
year={2024},
eprint={2402.13718},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
致谢
感谢冯聪、翟中午、曾国洋、宋晨阳、罗仁杰、何超群、涂玉琳、平博文、黄宇杰、梅煜东、张凯活、赵伟霖、孙奥、陈雨林、崔淦曲。











