
 访问官网
访问官网 Github
Github 文档
文档 论文
论文VideoReTalking
基于音频的野外人头视频编辑唇形同步技术

1 西安电子科技大学 2 腾讯AI实验室 3 清华大学
SIGGRAPH Asia 2022 会议论文

我们提出了VideoReTalking,这是一个新系统,可以根据输入的音频编辑真实世界说话人头视频中的面部,即使表情不同,也能产生高质量且唇形同步的输出视频。我们的系统将这一目标分解为三个连续的任务:
(1) 生成具有标准表情的人脸视频
(2) 基于音频的唇形同步
(3) 提高照片真实感的人脸增强
给定一个说话人头视频,我们首先使用表情编辑网络根据相同的表情模板修改每一帧的表情,生成一个具有标准表情的视频。然后将这个视频与给定的音频一起输入到唇形同步网络中,生成唇形同步的视频。最后,我们通过一个身份感知的人脸增强网络和后处理来提高合成人脸的照片真实感。我们对所有三个步骤都采用基于学习的方法,所有模块都可以在一个连续的流程中处理,无需用户干预。
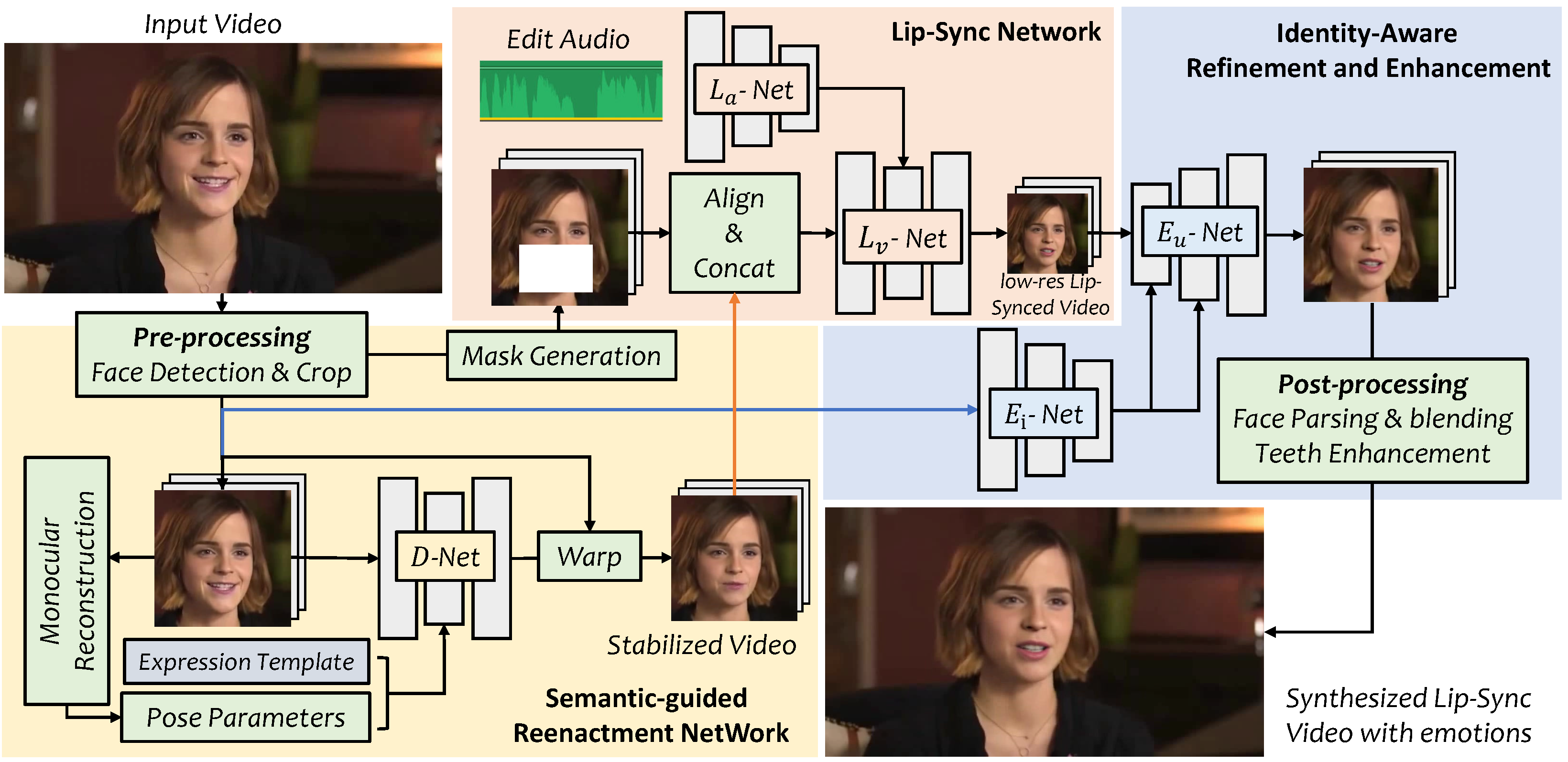
流程图
野外效果展示(包含音频)
https://user-images.githubusercontent.com/4397546/224310754-665eb2dd-aadc-47dc-b1f9-2029a937b20a.mp4
环境配置
git clone https://github.com/vinthony/video-retalking.git
cd video-retalking
conda create -n video_retalking python=3.8
conda activate video_retalking
conda install ffmpeg
# 请按照以下链接的说明进行操作 https://pytorch.org/get-started/previous-versions/
# 此安装命令仅适用于CUDA 11.1
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
快速推理
预训练模型
请下载我们的预训练模型并将它们放在./checkpoints目录下。
推理
python3 inference.py \
--face examples/face/1.mp4 \
--audio examples/audio/1.wav \
--outfile results/1_1.mp4
此脚本包含数据预处理步骤。您可以测试任何人脸视频而无需手动对齐。但值得注意的是,DNet无法处理极端姿势。
您还可以通过添加以下参数来控制表情:
--exp_img:预定义的表情模板。默认为"neutral"。您可以选择"smile"或一个图像路径。
--up_face:您可以选择"surprise"或"angry"来使用GANimation修改上半部分脸的表情。
引用
如果您发现我们的工作对您的研究有用,请考虑引用:
@misc{cheng2022videoretalking,
title={VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild},
author={Kun Cheng and Xiaodong Cun and Yong Zhang and Menghan Xia and Fei Yin and Mingrui Zhu and Xuan Wang and Jue Wang and Nannan Wang},
year={2022},
eprint={2211.14758},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
致谢
感谢 Wav2Lip、 PIRenderer、 GFP-GAN、 GPEN、 ganimation_replicate、 STIT 分享他们的代码。
相关工作
- StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN (ECCV 2022)
- CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior (CVPR 2023)
- SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation (CVPR 2023)
- DPE: Disentanglement of Pose and Expression for General Video Portrait Editing (CVPR 2023)
- 3D GAN Inversion with Facial Symmetry Prior (CVPR 2023)
- T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations (CVPR 2023)
免责声明
这不是腾讯的官方产品。
1. 在使用本代码之前,请仔细阅读并遵守适用于本代码的开源许可证。
2. 在使用本代码之前,请仔细阅读并遵守适用于本代码的知识产权声明。
3. 本开源代码完全离线运行,不会收集任何个人信息或其他数据。如果您使用本代码为最终用户提供服务并收集相关数据,请根据适用的法律法规采取必要的合规措施(如发布隐私政策、采取必要的数据安全策略等)。如果收集的数据涉及个人信息,必须获得用户同意(如适用)。由此产生的任何法律责任与腾讯无关。
4. 未经腾讯书面许可,您无权使用腾讯合法拥有的名称或标识,如"腾讯"。否则,您可能需要承担法律责任。
5. 本开源代码不具备直接向最终用户提供服务的能力。如果您需要使用本代码进行进一步的模型训练或演示,作为您产品的一部分向最终用户提供服务,或类似用途,请遵守适用于您的产品或服务的法律法规。由此产生的任何法律责任与腾讯无关。
6. 禁止使用本开源代码从事损害他人合法权益的活动(包括但不限于欺诈、欺骗、侵犯他人肖像权、名誉权等),或其他违反适用法律法规或违背社会公德和良好风俗的行为(包括提供不正确或虚假信息,传播色情、恐怖主义和暴力信息等)。否则,您可能需要承担法律责任。











