
 访问官网
访问官网 Github
Github 文档
文档


引用安全策略优化
如果您发现安全策略优化有用,请在您的出版物中引用它。
@article{ji2023safety,
title={Safety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark},
author={Ji, Jiaming and Zhang, Borong and Zhou, Jiayi and Pan, Xuehai and Huang, Weidong and Sun, Ruiyang and Geng, Yiran and Zhong, Yifan and Dai, Juntao and Yang, Yaodong},
journal={arXiv preprint arXiv:2310.12567},
year={2023}
}
最新动态:
**安全策略优化(SafePO)**是一个全面的安全强化学习(Safe RL)算法基准。它为强化学习研究社区提供了一个统一的平台,用于处理和评估各种安全强化学习环境中的算法。为了更好地帮助社区研究这个问题,SafePO开发时具有以下关键特性:
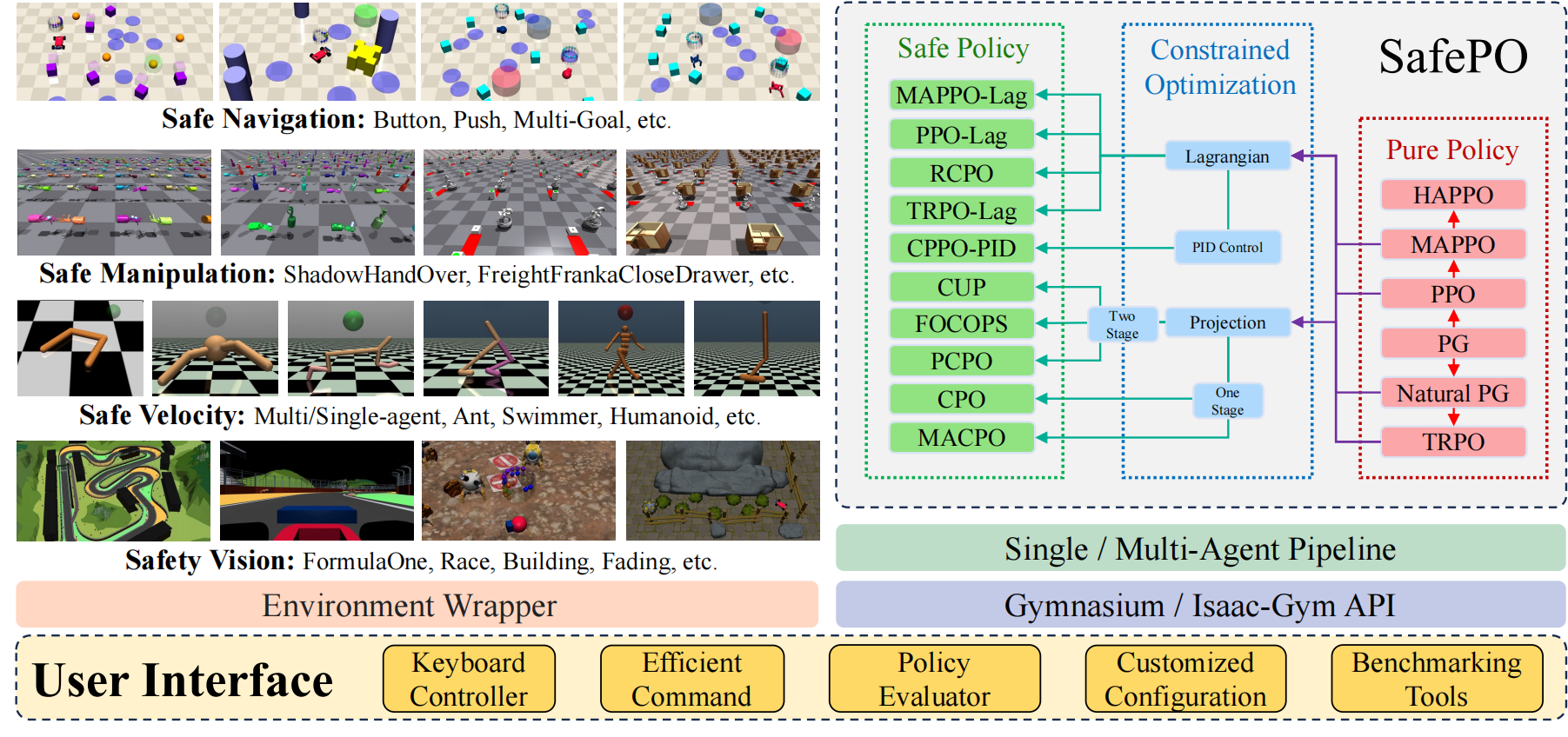
**正确性。**对于基准来说,确保其正确性和可靠性至关重要。为实现这一目标,我们仔细检查了SafePO的实现。首先,每个算法都严格按照原始论文实现(例如,确保与原始论文的梯度流一致等)。其次,对于具有公认开源代码库的算法,我们逐行比较我们的实现与这些代码库,以再次检查正确性。最后,我们将SafePO与现有基准(如Safety-Starter-Agents和RL-Safety-Algorithms)进行比较,结果表明SafePO优于其他现有实现。
**可扩展性。**得益于其架构,SafePO具有高度的可扩展性。新算法可以通过继承基础算法并仅实现其独特特性来集成到SafePO中。例如,我们通过继承策略梯度并仅添加剪切比率变量和重写计算策略损失的函数来集成PPO。以类似的方式,算法可以轻松添加到SafePO中。
**日志记录和可视化。**SafePO的另一个重要功能是日志记录和可视化。支持TensorBoard和WandB,我们提供了40多个参数和中间计算结果的可视化代码,以便检查训练过程。通用可视化的常见参数和指标包括KL散度、SPS(每秒步数)和成本方差。在训练过程中,用户能够检查每个参数的变化,收集日志文件,并获取保存的检查点模型。完整而全面的可视化使观察、模型选择和比较变得更加容易。
**文档。**除了代码实现,SafePO还附带了详细文档。我们包含了安装指南和常见问题的解决方案。此外,我们还提供了SafePO简单使用和高级自定义的说明。官方信息涉及维护、道德和负责任使用,供参考。
算法概述
这里我们提供了基准包含的安全强化学习算法表格。
注意:基准中还包括四种经典的强化学习算法,即PG、NaturalPG、TRPO和PPO。
| 算法 | 会议与引用次数 | 官方代码仓库 | 官方代码最后更新时间 | 官方GitHub星数 |
|---|---|---|---|---|
| PPO-Lag | :x: | Tensorflow 1 |  |  |
| TRPO-Lag | :x: | Tensorflow 1 | | |
| CUP | Neurips 2022 (引用: 6) | Pytorch |  |  |
| FOCOPS | Neurips 2020 (引用: 27) | Pytorch |  |  |
| CPO | ICML 2017(引用: 663) | :x: | :x: | :x: |
| PCPO | ICLR 2020(引用: 67) | Theano | :x: | :x: |
| RCPO | ICLR 2019 (引用: 238) | :x: | :x: | :x: |
| CPPO-PID | Neurips 2020(引用: 71) | Pytorch |  |  |
| MACPO | 预印本(引用: 4) | Pytorch |  |  |
| MAPPO-Lag | 预印本(引用: 4) | Pytorch | | |
| HAPPO (纯奖励优化) | ICLR 2022 (引用: 10) | Pytorch |  |  |
| MAPPO (纯奖励优化) | 预印本(引用: 98) | Pytorch |  |  |
支持的环境:Safety-Gymnasium
更多详情,请参考 Safety-Gymnasium。
| 类别 | 任务 | 智能体 | 示例 |
|---|---|---|---|
| 安全导航 | 目标[012] | 点、汽车、狗狗、赛车、蚂蚁 | SafetyPointGoal1-v0 |
| 按钮[012] | |||
| 推动[012] | |||
| 圆圈[012] | |||
| 安全速度 | 速度 | 半猎豹、跳跃者、游泳者、行走者2d、蚂蚁、人形 | SafetyAntVelocity-v1 |
| 安全多智能体 | 多目标[012] | 多点、多蚂蚁 | SafetyAntMultiGoal1-v0 |
| 多智能体速度 | 6x1半猎豹、2x3半猎豹、3x1跳跃者、2x1游泳者、2x3行走者2d、2x4蚂蚁、4x2蚂蚁、9|8人形 | Safety2x4AntVelocity-v0 | |
| 安全Isaac Gym | FreightFranka关抽屉 | FreightFranka | FreightFrankaCloseDrawer |
| FreightFranka拾取放置 | |||
| 影子手抓接过顶到下臂_安全手指 | 影子手 | ShadowHandCatchOver2Underarm_Safe_finger | |
| 影子手抓接过顶到下臂_安全关节 | |||
| 影子手传递_安全手指 | |||
| 影子手传递_安全关节 |
注意:
- 安全速度和安全Isaac Gym任务同时支持单智能体和多智能体算法。
- 安全导航任务支持单智能体算法。
- 安全多目标任务支持多智能体算法。
- 安全Isaac Gym任务目前还不支持训练后的评估。
- 由于Isaac Gym不在PyPI上,您需要手动安装它,然后通过运行
python/examples目录中的一个示例(如joint_monkey.py)来确保Isaac Gym在您的系统上正常工作。 - ❗️由于安全多目标和安全Isaac Gym任务因包大小过大未上传到PyPI,请手动安装Safety-Gymnasium以运行这两个任务,使用以下命令:
conda create -n safepo python=3.8
conda activate safepo
wget https://github.com/PKU-Alignment/safety-gymnasium/archive/refs/heads/main.zip
unzip main.zip
cd safety-gymnasium-main
pip install -e .
选定任务
| 基础环境 | 描述 | 演示 |
|---|---|---|
| 影子手传递 | 这些环境涉及两个固定位置的手。开始时拥有物体的手必须找到一种方法将其传递给第二只手。 |  |
| 影子手抓接过顶到下臂 | 这个环境由半个影子手抓接下臂和半个影子手抓接过顶组成,物体需要从垂直的手抛向朝上的手掌 |  |
我们对基础环境实施了一些不同的约束,包括"安全手指"和"安全关节"。更多详情请参考Safety-Gymnasium

先决条件
要使用SafePO-Baselines,您需要安装环境。有关安装的更多详细信息,请参阅Safety-Gymnasium。IsaacGym的安装详情可以在这里找到。
Conda环境
conda create -n safepo python=3.8
conda activate safepo
# 由于cuda版本的原因,我们建议您手动安装pytorch。
pip install -e .
入门
高效命令
要验证SafePO的性能,您可以运行以下命令:
conda create -n safepo python=3.8
conda activate safepo
make benchmark
我们还为单智能体和多智能体算法提供了简单的基准测试命令:
conda create -n safepo python=3.8
conda activate safepo
make simple-benchmark
上述命令将在采样的环境中运行所有算法,以快速概览算法的性能。
请注意,这些命令会从PyPI重新安装Safety-Gymnasium。要运行安全Isaac Gym和安全多目标,请通过以下方式从源代码手动重新安装:
conda activate safepo
wget https://github.com/PKU-Alignment/safety-gymnasium/archive/refs/heads/main.zip
unzip main.zip
cd safety-gymnasium-main
pip install -e .
单智能体
每个算法文件都是入口。运行带有算法和环境参数的ALGO.py进行训练。例如,要在SafetyPointGoal1-v0中运行PPO-Lag,种子为0,您可以使用以下命令:
cd safepo/single_agent
python ppo_lag.py --task SafetyPointGoal1-v0 --seed 0
要并行运行基准测试,例如,您可以使用以下命令在SafetyAntVelocity-v1、SafetyHalfCheetahVelocity-v1中运行PPO-Lag、TRPO-Lag:
cd safepo/single_agent
python benchmark.py --tasks SafetyAntVelocity-v1 SafetyHalfCheetahVelocity-v1 --algo ppo_lag trpo_lag --workers 2
上述命令将并行运行两个进程,每个进程将在一个环境中运行一个算法。结果将保存在./runs/中。
多智能体
我们还在Safety-Gymnasium的具有挑战性的任务上提供了安全MARL算法基准,包括安全多智能体速度、安全Isaac Gym和安全多目标任务。已经实现了HAPPO、MACPO、MAPPO-Lag和MAPPO。
要训练多智能体算法:
cd safepo/multi_agent
python macpo.py --task Safety2x4AntVelocity-v0 --experiment benchmark
如果您已安装Isaac Gym,还可以在基于Isaac Gym的环境中进行训练。
cd safepo/multi_agent
python macpo.py --task ShadowHandOver_Safe_joint --experiment benchmark
实验评估
运行实验后,您可以使用以下命令绘制结果:
cd safepo
python plot.py --logdir ./runs/benchmark
要评估算法的性能,可以使用以下命令:
cd safepo
python evaluate.py --benchmark-dir ./runs/benchmark
机器配置
我们在CPU: AMD Ryzen Threadripper PRO 3975WX 32核和GPU: NVIDIA GeForce RTX 3090,驱动版本:495.44上测试了所有算法和实验。我们所有的实验都在Linux平台上运行。如果您在Mac或Windows上遇到任何问题,请随时提出issue。
道德和负责任的使用
SafePO旨在为安全强化学习社区研究提供帮助,并在Apache-2.0许可下发布。不允许非法使用或任何违反许可的行为。
北京大学对齐团队
这个基准测试是北京大学对齐团队的项目贡献。我们还感谢以下开源仓库的贡献者列表: Spinning Up、Bullet-Safety-Gym、Safety-Gym。











