
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文⚡FlashRAG:高效RAG研究的Python工具包
安装 | 特性 | 快速开始 | 组件 | 支持的方法 | 支持的数据集 | 常见问题
FlashRAG是一个用于复现和开发检索增强生成(RAG)研究的Python工具包。我们的工具包包含32个预处理过的基准RAG数据集和14种最先进的RAG算法。
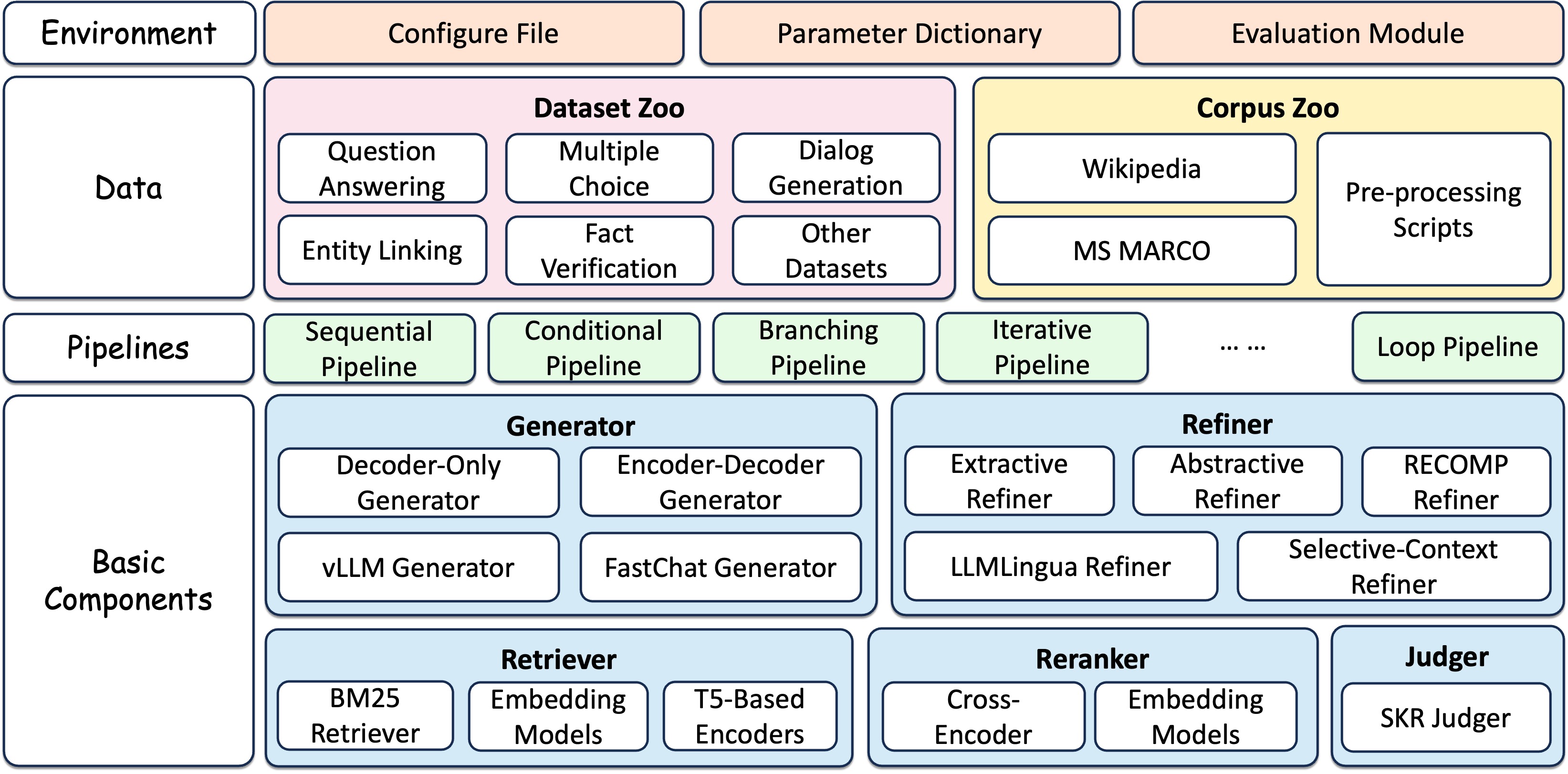
使用FlashRAG和提供的资源,您可以轻松地复现RAG领域现有的最先进工作,或实现自定义的RAG流程和组件。
:sparkles: 特性
-
广泛且可定制的框架:包括RAG场景的必要组件,如检索器、重排器、生成器和压缩器,允许灵活组装复杂的流程。
-
全面的基准数据集:收集了32个预处理过的RAG基准数据集,用于测试和验证RAG模型的性能。
-
预先实现的高级RAG算法:基于我们的框架,提供14种先进的RAG算法及其报告结果。可以轻松在不同设置下复现结果。
-
高效的预处理阶段:通过提供各种脚本,如用于检索的语料处理、检索索引构建和文档预检索,简化RAG工作流程的准备。
-
优化的执行:通过使用vLLM、FastChat加速LLM推理,以及使用Faiss管理向量索引,提高了库的效率。
:mag_right: 路线图
FlashRAG仍在开发中,存在许多问题和改进空间。我们将继续更新。我们也真诚欢迎对这个开源工具包的贡献。
- 支持OpenAI模型
- 支持Claude和Gemini模型
- 为每个组件提供说明
- 集成句子转换器
- 包含更多RAG方法
- 添加更多评估指标(如Unieval、命名实体F1)和基准(如RGB基准)
- 提高代码适应性和可读性
:page_with_curl: 更新日志
[24/08/02] 我们增加了对新方法Spring的支持,通过仅添加少量token嵌入,显著提高了LLM的性能。查看其在结果表中的表现。
[24/07/17] 由于HuggingFace的一些未知问题,我们原来的数据集链接已失效。我们已更新链接。如果遇到任何问题,请查看新链接。
[24/07/06] 我们增加了对新方法的支持:Trace,该方法通过构建知识图谱来优化文本。查看其结果和详情。
[24/06/19] 我们增加了对新方法的支持:IRCoT,并更新了结果表。
[24/06/15] 我们提供了一个演示来使用我们的工具包执行RAG过程。
[24/06/11] 我们在检索器模块中集成了sentence transformers。现在无需设置池化方法就可以更方便地使用检索器。
[24/06/05] 我们提供了复现现有方法的详细文档(参见如何复现、基线详情),以及配置设置。
[24/06/02] 我们为初学者提供了FlashRAG的介绍,参见FlashRAG入门指南(中文版 한국어)。
[24/05/31] 我们支持使用Openai系列模型作为生成器。
:wrench: 安装
要开始使用FlashRAG,只需从Github克隆并安装(需要Python 3.9+):
git clone https://github.com/RUC-NLPIR/FlashRAG.git
cd FlashRAG
pip install -e .
由于使用pip安装faiss时存在不兼容问题,需要使用以下conda命令进行安装。
# 仅CPU版本
conda install -c pytorch faiss-cpu=1.8.0
# GPU(+CPU)版本
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
注意:在某些系统上无法安装最新版本的faiss。
来自Faiss官方仓库(来源):
- 仅CPU的faiss-cpu conda包目前在Linux(x86_64和arm64)、OSX(仅arm64)和Windows(x86_64)上可用
- 包含CPU和GPU索引的faiss-gpu在Linux(仅x86_64)上适用于CUDA 11.4和12.1
:rocket: 快速开始
示例
对于初学者,我们提供了FlashRAG入门指南(中文版 한국어)帮助您熟悉我们的工具包。或者,您可以直接参考以下代码。
演示
我们提供了一个简单的演示来实现基本的RAG过程。您可以自由更改想要使用的语料库和模型。英文演示使用通用知识作为语料库,e5-base-v2作为检索器,Llama3-8B-instruct作为生成器。中文演示使用从中国人民大学官方网站爬取的数据作为语料库,bge-large-zh-v1.5作为检索器,qwen1.5-14B作为生成器。请在文件中填写相应的路径。
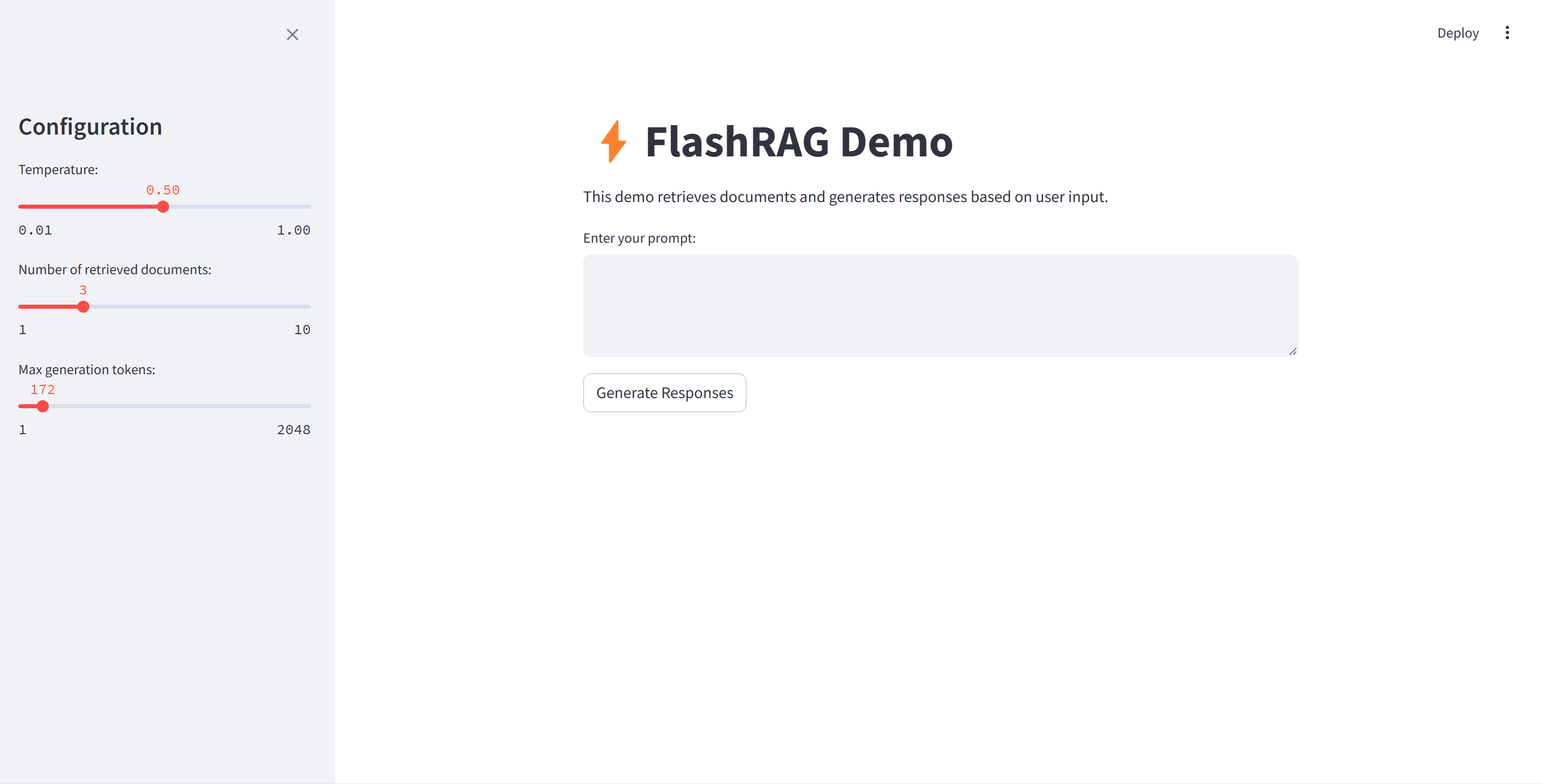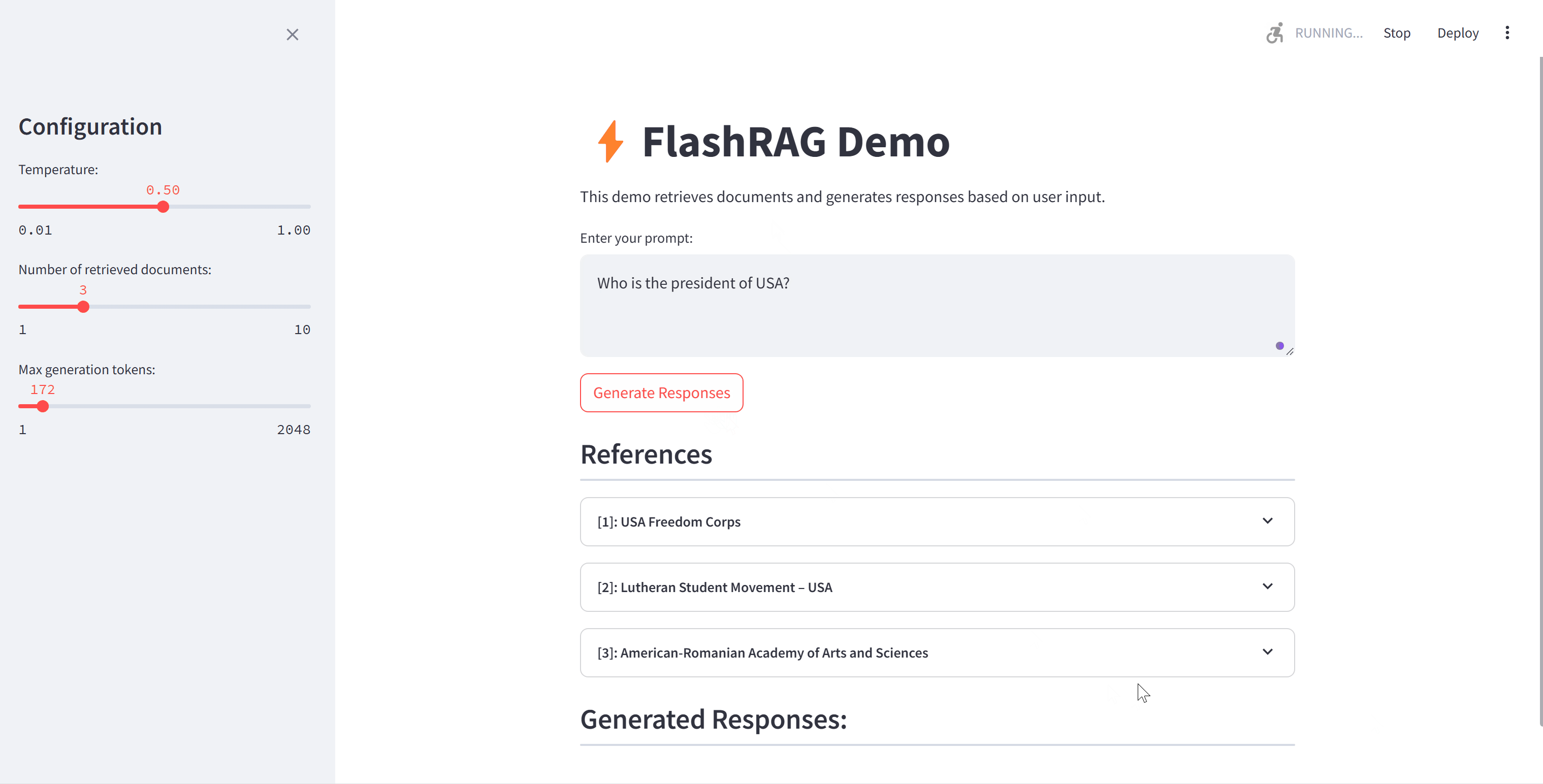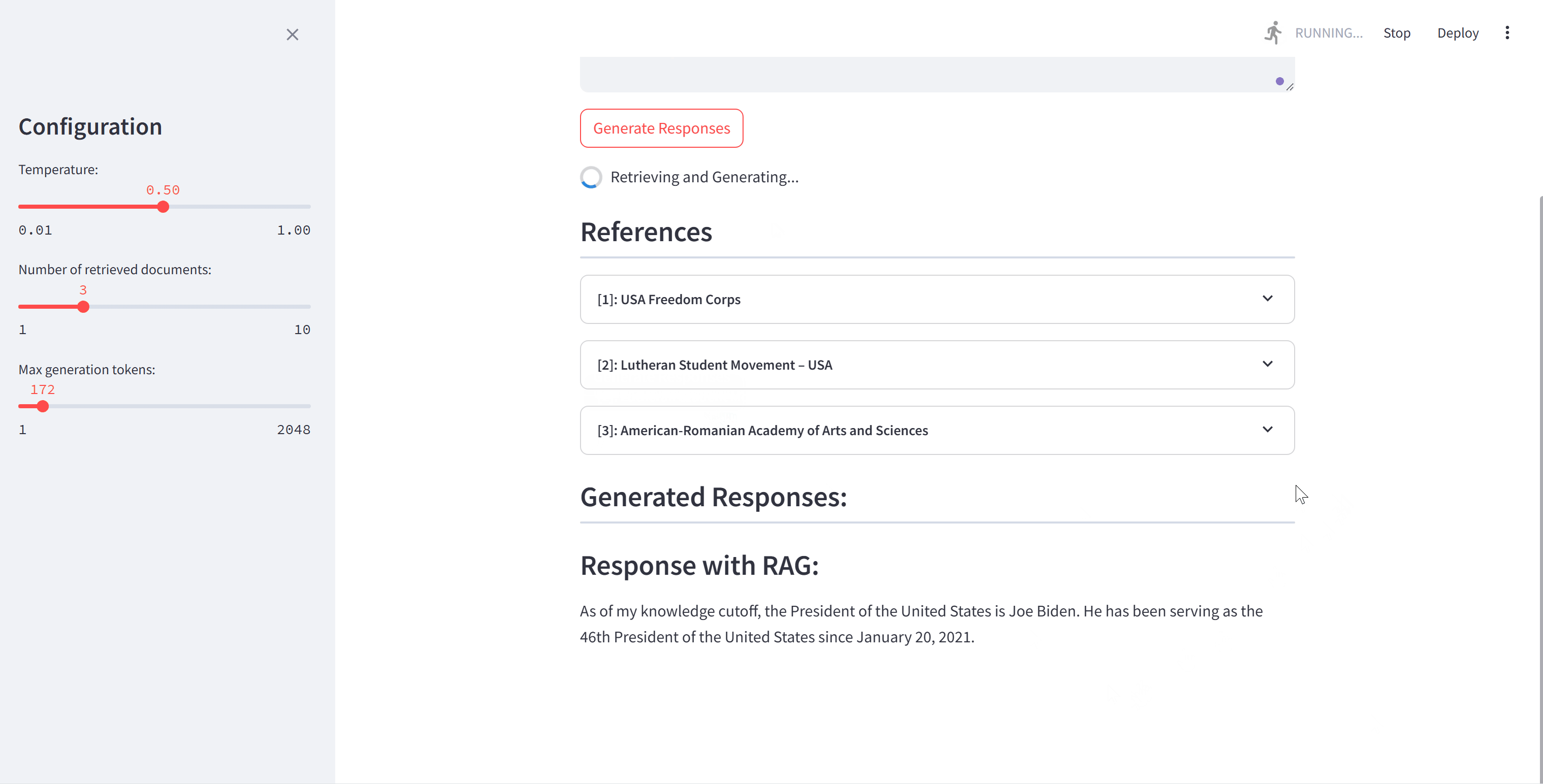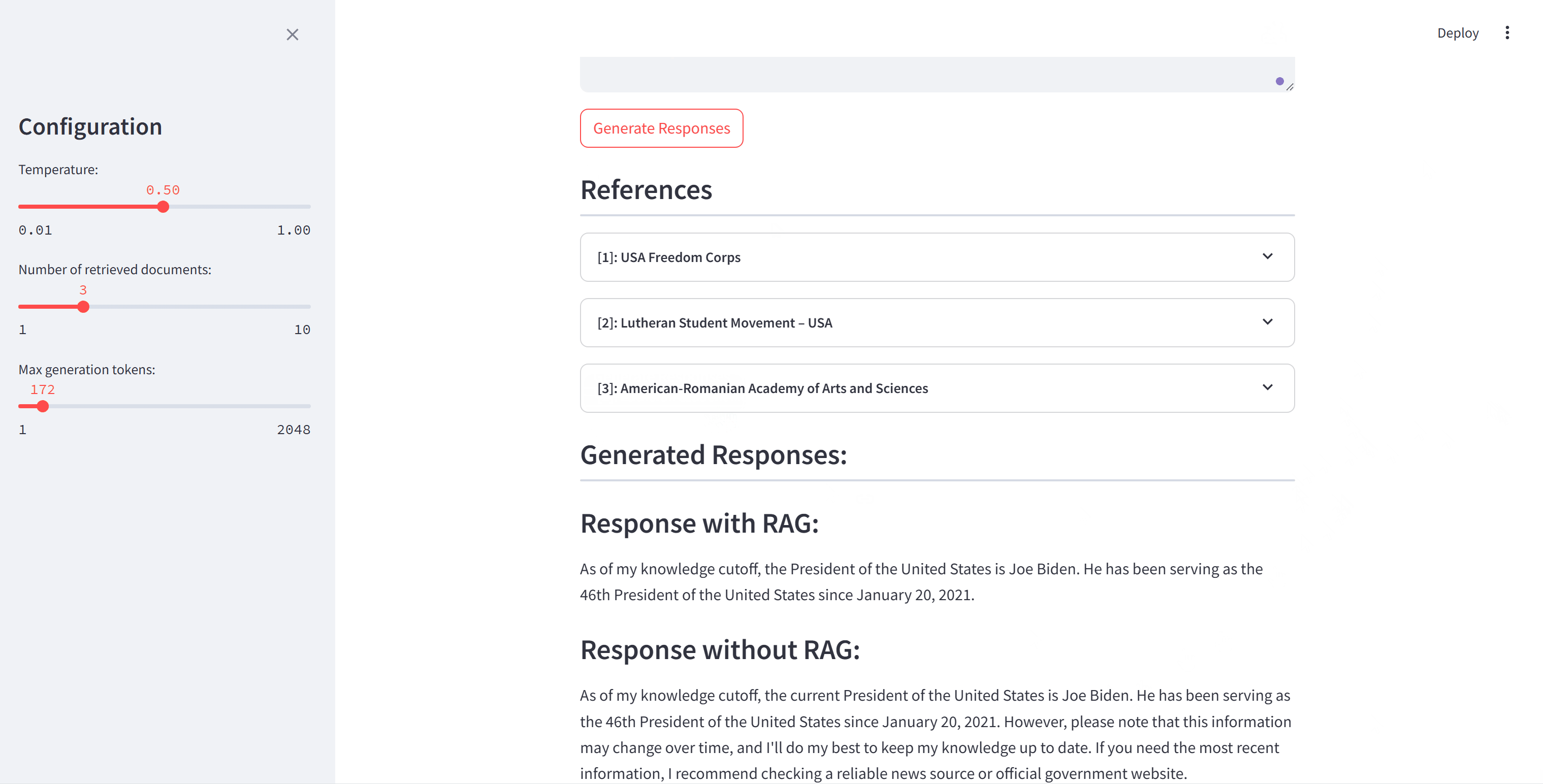
运行演示:
cd examples/quick_start
# 将配置文件复制到这里,否则streamlit会抱怨找不到文件
cp ../methods/my_config.yaml .
# 运行英文演示
streamlit run demo_en.py
# 运行中文演示
streamlit run demo_zh.py
流程
我们还提供了一个使用我们框架进行流水线执行的示例。
运行以下代码以使用提供的玩具数据集实现一个简单的RAG流水线。
默认的检索器是e5-base-v2,默认的生成器是Llama3-8B-instruct。您需要在以下命令中填写相应的模型路径。如果您希望使用其他模型,请参考下面的详细说明。
cd examples/quick_start
python simple_pipeline.py \
--model_path <Llama-3-8B-instruct-路径> \
--retriever_path <E5-路径>
代码完成后,您可以在相应路径下的输出文件夹中查看运行的中间结果和最终评估得分。
使用现成的流水线
您可以使用我们已经构建好的流水线类(如流水线所示)来实现内部的RAG流程。在这种情况下,您只需配置config并加载相应的流水线。
首先,加载整个流程的配置,其中记录了RAG过程中所需的各种超参数。您可以将yaml文件作为参数输入,也可以直接作为变量输入。变量输入的优先级高于文件输入。
from flashrag.config import Config
config_dict = {'data_dir': 'dataset/'}
my_config = Config(config_file_path = 'my_config.yaml',
config_dict = config_dict)
我们提供了关于如何设置配置的全面指导,您可以查看我们的配置指南。 您也可以参考我们提供的基本yaml文件来设置您自己的参数。
接下来,加载相应的数据集并初始化流水线。流水线中的组件将自动加载。
from flashrag.utils import get_dataset
from flashrag.pipeline import SequentialPipeline
from flashrag.prompt import PromptTemplate
from flashrag.config import Config
config_dict = {'data_dir': 'dataset/'}
my_config = Config(config_file_path = 'my_config.yaml',
config_dict = config_dict)
all_split = get_dataset(my_config)
test_data = all_split['test']
pipeline = SequentialPipeline(my_config)
您可以使用PromptTemplete指定自己的输入提示:
prompt_templete = PromptTemplate(
config,
system_prompt = "根据给定的文档回答问题。只给我答案,不要输出任何其他文字。\n以下是给定的文档。\n\n{reference}",
user_prompt = "问题:{question}\n回答:"
)
pipeline = SequentialPipeline(my_config, prompt_template=prompt_templete)
最后,执行pipeline.run获取最终结果。
output_dataset = pipeline.run(test_data, do_eval=True)
output_dataset包含输入数据集中每个项目的中间结果和指标得分。
同时,带有中间结果的数据集和整体评估得分也将被保存为文件(如果指定了save_intermediate_data和save_metric_score)。
构建自己的流水线
有时您可能需要实现更复杂的RAG流程,您可以构建自己的流水线来实现它。
您只需继承BasicPipeline,初始化所需的组件,并完成run函数。
from flashrag.pipeline import BasicPipeline
from flashrag.utils import get_retriever, get_generator
class ToyPipeline(BasicPipeline):
def __init__(self, config, prompt_templete=None):
# 加载您自己的组件
pass
def run(self, dataset, do_eval=True):
# 完成您自己的处理逻辑
# 使用`.`获取数据集中的属性
input_query = dataset.question
...
# 使用`update_output`保存中间数据
dataset.update_output("pred",pred_answer_list)
dataset = self.evaluate(dataset, do_eval=do_eval)
return dataset
请首先从我们的文档中了解您需要使用的组件的输入和输出形式。
仅使用组件
如果您已经有自己的代码,只想使用我们的组件嵌入原始代码,可以参考组件基本介绍获取每个组件的输入和输出格式。
:gear: 组件
在FlashRAG中,我们构建了一系列常见的RAG组件,包括检索器、生成器、细化器等。基于这些组件,我们组装了几个流水线来实现RAG工作流,同时也提供了灵活性,可以自定义组合这些组件以创建您自己的流水线。
RAG组件
| 类型 | 模块 | 描述 |
|---|---|---|
| 判断器 | SKR判断器 | 使用SKR方法判断是否进行检索 |
| 检索器 | 密集检索器 | 双编码器模型,如dpr、bge、e5,使用faiss进行搜索 |
| BM25检索器 | 基于Lucene的稀疏检索方法 | |
| 双编码器重排器 | 使用双编码器计算匹配分数 | |
| 交叉编码器重排器 | 使用交叉编码器计算匹配分数 | |
| 细化器 | 抽取式细化器 | 通过提取重要上下文细化输入 |
| 生成式细化器 | 通过seq2seq模型细化输入 | |
| LLMLingua细化器 | LLMLingua系列提示压缩器 | |
| SelectiveContext细化器 | Selective-Context提示压缩器 | |
| 知识图谱细化器 | 使用Trace方法构建知识图谱 | |
| 生成器 | 编码器-解码器生成器 | 编码器-解码器模型,支持Fusion-in-Decoder (FiD) |
| 仅解码器生成器 | 原生transformers实现 | |
| FastChat生成器 | 使用FastChat加速 | |
| vllm生成器 | 使用vllm加速 |
流水线
参考检索增强生成调查,我们根据推理路径将RAG方法分为四类。
- 顺序型:RAG过程的顺序执行,如查询-(预检索)-检索器-(后检索)-生成器
- 条件型:为不同类型的输入查询实现不同的路径
- 分支型:并行执行多个路径,合并每个路径的响应
- 循环型:迭代执行检索和生成
在每个类别中,我们都实现了相应的常见流水线。一些流水线有相应的工作论文。
| 类型 | 模块 | 描述 |
|---|---|---|
| 顺序 | 顺序流水线 | 查询的线性执行,支持精炼器、重排序器 |
| 条件 | 条件流水线 | 通过判断模块,为不同类型的查询提供不同的执行路径 |
| 分支 | REPLUG流水线 | 通过整合多个生成路径的概率来生成答案 |
| SuRe流水线 | 基于每个文档对生成的结果进行排序和合并 | |
| 循环 | 迭代流水线 | 交替进行检索和生成 |
| 自问流水线 | 使用自问方法将复杂问题分解为子问题 | |
| 自RAG流水线 | 自适应检索、批评和生成 | |
| FLARE流水线 | 在生成过程中动态检索 | |
| IRCoT流水线 | 将检索过程与思维链整合 |
:robot: 支持的方法
我们已经实现了14种工作,使用一致的设置:
- 生成器: LLAMA3-8B-instruct,输入长度为2048
- 检索器: e5-base-v2作为嵌入模型,每次查询检索5个文档
- 提示词: 一致的默认提示词,模板可以在方法详情中找到。
对于开源方法,我们使用我们的框架实现了它们的流程。对于作者没有提供源代码的方法,我们会尽最大努力按照原论文中的方法进行实现。
对于某些方法特有的必要设置和超参数,我们在特定设置列中进行了记录。更多详情,请查阅我们的复现指南和方法详情。
需要注意的是,为了保证一致性,我们使用了统一的设置。然而,这种设置可能与方法的原始设置不同,导致结果与原始结果有所差异。
| 方法 | 类型 | NQ (EM) | TriviaQA (EM) | Hotpotqa (F1) | 2Wiki (F1) | PopQA (F1) | WebQA(EM) | 特定设置 |
|---|---|---|---|---|---|---|---|---|
| 朴素生成 | 顺序 | 22.6 | 55.7 | 28.4 | 33.9 | 21.7 | 18.8 | |
| 标准RAG | 顺序 | 35.1 | 58.9 | 35.3 | 21.0 | 36.7 | 15.7 | |
| AAR-contriever-kilt | 顺序 | 30.1 | 56.8 | 33.4 | 19.8 | 36.1 | 16.1 | |
| LongLLMLingua | 顺序 | 32.2 | 59.2 | 37.5 | 25.0 | 38.7 | 17.5 | 压缩比=0.5 |
| RECOMP-abstractive | 顺序 | 33.1 | 56.4 | 37.5 | 32.4 | 39.9 | 20.2 | |
| Selective-Context | 顺序 | 30.5 | 55.6 | 34.4 | 18.5 | 33.5 | 17.3 | 压缩比=0.5 |
| Trace | 顺序 | 30.7 | 50.2 | 34.0 | 15.5 | 37.4 | 19.9 | |
| Spring | 顺序 | 37.9 | 64.6 | 42.6 | 37.3 | 54.8 | 27.7 | 使用Llama2-7B-chat和训练过的嵌入表 |
| SuRe | 分支 | 37.1 | 53.2 | 33.4 | 20.6 | 48.1 | 24.2 | 使用提供的提示词 |
| REPLUG | 分支 | 28.9 | 57.7 | 31.2 | 21.1 | 27.8 | 20.2 | |
| SKR | 条件 | 33.2 | 56.0 | 32.4 | 23.4 | 31.7 | 17.0 | 使用推理时训练数据 |
| Ret-Robust | 循环 | 42.9 | 68.2 | 35.8 | 43.4 | 57.2 | 33.7 | 使用训练过lora的LLAMA2-13B |
| Self-RAG | 循环 | 36.4 | 38.2 | 29.6 | 25.1 | 32.7 | 21.9 | 使用训练过的selfrag-llama2-7B |
| FLARE | 循环 | 22.5 | 55.8 | 28.0 | 33.9 | 20.7 | 20.2 | |
| Iter-Retgen, ITRG | 循环 | 36.8 | 60.1 | 38.3 | 21.6 | 37.9 | 18.2 | |
| IRCoT | 循环 | 33.3 | 56.9 | 41.5 | 32.4 | 45.6 | 20.7 |
:notebook: 支持的数据集和文档语料库
数据集
我们收集并处理了35个在RAG研究中广泛使用的数据集,对它们进行预处理以确保格式一致,便于使用。对于某些数据集(如Wiki-asp),我们根据社区内常用的方法将其调整以符合RAG任务的要求。所有数据集都可在Huggingface datasets上获取。
对于每个数据集,我们将每个分割保存为一个jsonl文件,每行是一个如下所示的字典:
{
'id': str,
'question': str,
'golden_answers': List[str],
'metadata': dict
}
以下是数据集列表以及相应的样本数量:
| 任务 | 数据集名称 | 知识来源 | 训练集数量 | 验证集数量 | 测试集数量 |
|---|---|---|---|---|---|
| 问答 | NQ | 维基百科 | 79,168 | 8,757 | 3,610 |
| 问答 | TriviaQA | 维基百科和网络 | 78,785 | 8,837 | 11,313 |
| 问答 | PopQA | 维基百科 | / | / | 14,267 |
| 问答 | SQuAD | 维基百科 | 87,599 | 10,570 | / |
| 问答 | MSMARCO-QA | 网络 | 808,731 | 101,093 | / |
| 问答 | NarrativeQA | 书籍和故事 | 32,747 | 3,461 | 10,557 |
| 问答 | WikiQA | 维基百科 | 20,360 | 2,733 | 6,165 |
| 问答 | WebQuestions | Google Freebase | 3,778 | / | 2,032 |
| 问答 | AmbigQA | 维基百科 | 10,036 | 2,002 | / |
| 问答 | SIQA | - | 33,410 | 1,954 | / |
| 问答 | CommenseQA | - | 9,741 | 1,221 | / |
| 问答 | BoolQ | 维基百科 | 9,427 | 3,270 | / |
| 问答 | PIQA | - | 16,113 | 1,838 | / |
| 问答 | Fermi | 维基百科 | 8,000 | 1,000 | 1,000 |
| 多跳问答 | HotpotQA | 维基百科 | 90,447 | 7,405 | / |
| 多跳问答 | 2WikiMultiHopQA | 维基百科 | 15,000 | 12,576 | / |
| 多跳问答 | Musique | 维基百科 | 19,938 | 2,417 | / |
| 多跳问答 | Bamboogle | 维基百科 | / | / | 125 |
| 长答案问答 | ASQA | 维基百科 | 4,353 | 948 | / |
| 长答案问答 | ELI5 | 272,634 | 1,507 | / | |
| 开放域摘要生成 | WikiASP | 维基百科 | 300,636 | 37,046 | 37,368 |
| 多项选择 | MMLU | - | 99,842 | 1,531 | 14,042 |
| 多项选择 | TruthfulQA | 维基百科 | / | 817 | / |
| 多项选择 | HellaSWAG | ActivityNet | 39,905 | 10,042 | / |
| 多项选择 | ARC | - | 3,370 | 869 | 3,548 |
| 多项选择 | OpenBookQA | - | 4,957 | 500 | 500 |
| 事实验证 | FEVER | 维基百科 | 104,966 | 10,444 | / |
| 对话生成 | WOW | 维基百科 | 63,734 | 3,054 | / |
| 实体链接 | AIDA CoNll-yago | Freebase和维基百科 | 18,395 | 4,784 | / |
| 实体链接 | WNED | 维基百科 | / | 8,995 | / |
| 槽位填充 | T-REx | DBPedia | 2,284,168 | 5,000 | / |
| 槽位填充 | Zero-shot RE | 维基百科 | 147,909 | 3,724 | / |
文档语料库
我们的工具包支持jsonl格式的检索文档集合,结构如下:
{"id":"0", "contents": "...."}
{"id":"1", "contents": "..."}
contents键对于构建索引至关重要。对于同时包含文本和标题的文档,我们建议将contents的值设置为{title}\n{text}。语料库文件还可以包含其他键来记录文档的附加特征。
在学术研究中,维基百科和MS MARCO是最常用的检索文档集合。对于维基百科,我们提供了一个全面的脚本来处理任何维基百科转储并生成干净的语料库。此外,许多工作中都提供了各种处理过的维基百科语料库版本,我们列出了一些参考链接。
对于MS MARCO,它在发布时已经经过处理,可以直接从Hugging Face上的托管链接下载。
:raised_hands: 其他常见问题
:bookmark: 许可证
FlashRAG 采用 MIT 许可证。
:star2: 引用
如果我们的工作对您的研究有帮助,请kindly引用我们的论文:
@article{FlashRAG,
author={Jiajie Jin and
Yutao Zhu and
Xinyu Yang and
Chenghao Zhang and
Zhicheng Dou},
title={FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research},
journal={CoRR},
volume={abs/2405.13576},
year={2024},
url={https://arxiv.org/abs/2405.13576},
eprinttype={arXiv},
eprint={2405.13576}
}











