
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文MimicMotion
MimicMotion:基于置信度感知姿态引导的高质量人体运动视频生成
张远1,2,顾嘉熙1,王立文1,王瀚1,2,程俊奇1,朱跃峰1,邹方圆1
[1腾讯; 2上海交通大学]






亮点:细节丰富,时序平滑度好,以及视频长度长。
概述
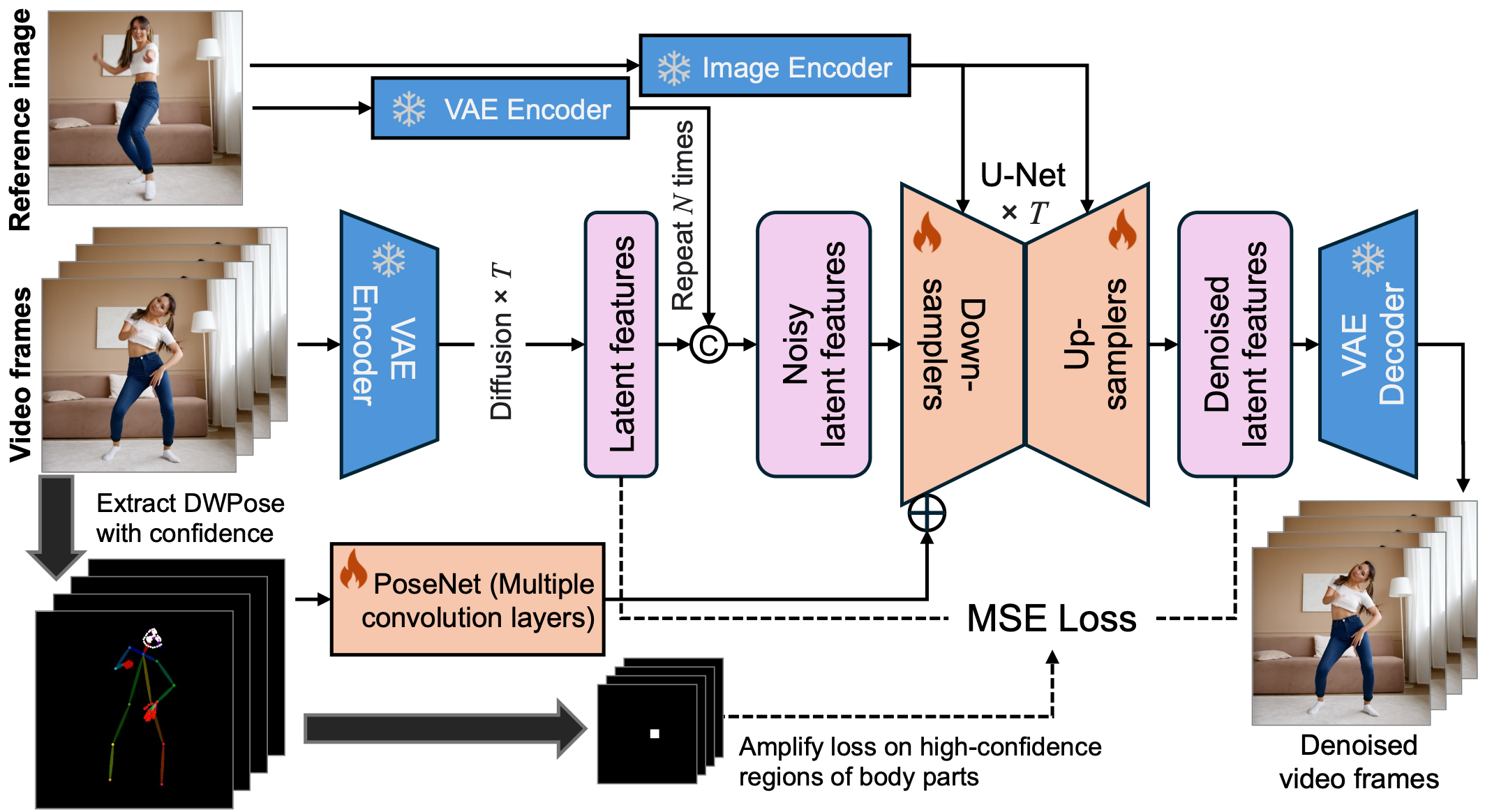
MimicMotion框架概览。
近年来,生成式人工智能在图像生成领域取得了显著进展,催生了各种应用。然而,视频生成在可控性、视频长度和细节丰富度等方面仍面临相当大的挑战,这阻碍了该技术的应用和普及。在本研究中,我们提出了一个可控的视频生成框架,名为MimicMotion,它能够根据任何运动引导生成任意长度的高质量视频。与之前的方法相比,我们的方法有几个亮点。首先,通过置信度感知的姿态引导,可以实现时间平滑性,从而通过大规模训练数据增强模型的鲁棒性。其次,基于姿态置信度的区域损失放大显著缓解了图像的失真。最后,为了生成长时间平滑视频,提出了一种渐进式潜在融合策略。通过这种方式,可以在可接受的资源消耗下生成任意长度的视频。通过广泛的实验和用户研究,MimicMotion在多个方面展示了比之前方法显著的改进。
新闻
[2024-07-08]: 🔥 作为1.1版本发布了一个更优秀的模型检查点。视频帧数的最大数量现已从16扩展到72,显著提升了视频质量![2024-07-01]: 项目页面、代码、技术报告和一个基础模型检查点已发布。一个支持更高质量视频生成的更好的检查点将很快发布。敬请关注!
快速开始
对于最初发布的模型检查点版本,它支持生成最多72帧、分辨率为576x1024的视频。如果遇到内存不足的问题,可以适当减少帧数。
环境设置
推荐使用Python 3+和Torch 2.x,已在Nvidia V100 GPU上验证。按照以下命令安装所有Python依赖:
conda env create -f environment.yaml
conda activate mimicmotion
下载权重
如果在连接Hugging Face时遇到问题,可以通过设置环境变量来使用镜像端点:export HF_ENDPOINT=https://hf-mirror.com。
请按如下方式手动下载权重:
cd MimicMotions/
mkdir models
- 下载DWPose预训练模型:dwpose
mkdir -p models/DWPose wget https://huggingface.co/yzd-v/DWPose/resolve/main/yolox_l.onnx?download=true -O models/DWPose/yolox_l.onnx wget https://huggingface.co/yzd-v/DWPose/resolve/main/dw-ll_ucoco_384.onnx?download=true -O models/DWPose/dw-ll_ucoco_384.onnx - 从Huggingface下载MimicMotion的预训练检查点
wget -P models/ https://huggingface.co/ixaac/MimicMotion/resolve/main/MimicMotion_1-1.pth - SVD模型stabilityai/stable-video-diffusion-img2vid-xt-1-1将自动下载。
最后,所有权重应按以下方式组织在models文件夹中:
models/
├── DWPose
│ ├── dw-ll_ucoco_384.onnx
│ └── yolox_l.onnx
└── MimicMotion_1-1.pth
模型推理
提供了一个用于测试的样例配置文件test.yaml。您也可以根据需要轻松修改各种配置。
python inference.py --inference_config configs/test.yaml
提示:如果您的GPU内存有限,请尝试设置环境变量PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:256。
VRAM要求和运行时间
对于35秒的演示视频,72帧模型需要16GB VRAM(4060ti),在4090 GPU上需要20分钟完成。
16帧U-Net模型的最低VRAM要求为8GB;但VAE解码器需要16GB。您可以选择在CPU上运行VAE解码器。
引用
@article{mimicmotion2024,
title={MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance},
author={Yuang Zhang and Jiaxi Gu and Li-Wen Wang and Han Wang and Junqi Cheng and Yuefeng Zhu and Fangyuan Zou},
journal={arXiv preprint arXiv:2406.19680},
year={2024}
}











