
 Github
Github 文档
文档野生指令数据集:基于用户的指令数据集
新闻
我们在 data v2 目录下发布了 InstructWild v2,其中包含超过 11 万条高质量的基于用户的指令。我们没有使用自指令生成任何指令。我们还为这些指令中的一部分标注了指令类型和特殊标签。详情请参阅 README。
简介
指令微调是 ChatGPT 的关键组成部分。OpenAI 使用了他们基于用户的指令数据集,但遗憾的是,这个数据集并未开源。Self-Instruct 发布了一个包含 175 条人工编写指令的小型指令数据集。斯坦福 Alpaca 团队基于上述 175 条种子指令,使用 text-davinci-003 模型生成了 5.2 万条指令。
本项目旨在创建一个更大、更多样化的指令数据集。为此,我们收集了(v2 数据集中有 11 万条,v1 数据集中有 429 条)来自 ChatGPT 使用分享的指令,并发布了英文和中文版本。我们发现这些指令非常多样化。我们参照 Alpaca 的方法生成了 5.2 万条指令及其回应。所有数据可以在 data 和 data v2 目录中找到。
注意:这是一个正在进行的项目。我们仍在收集和改进我们的数据。我们尽早发布这个数据集以加速我们的大语言模型研究。我们也将很快发布一份白皮书。
数据发布
我们的数据集使用与 Alpaca 相同的格式,以便快速和轻松使用。我们的指令没有输入字段。
数据收集(InsturctWild v1)
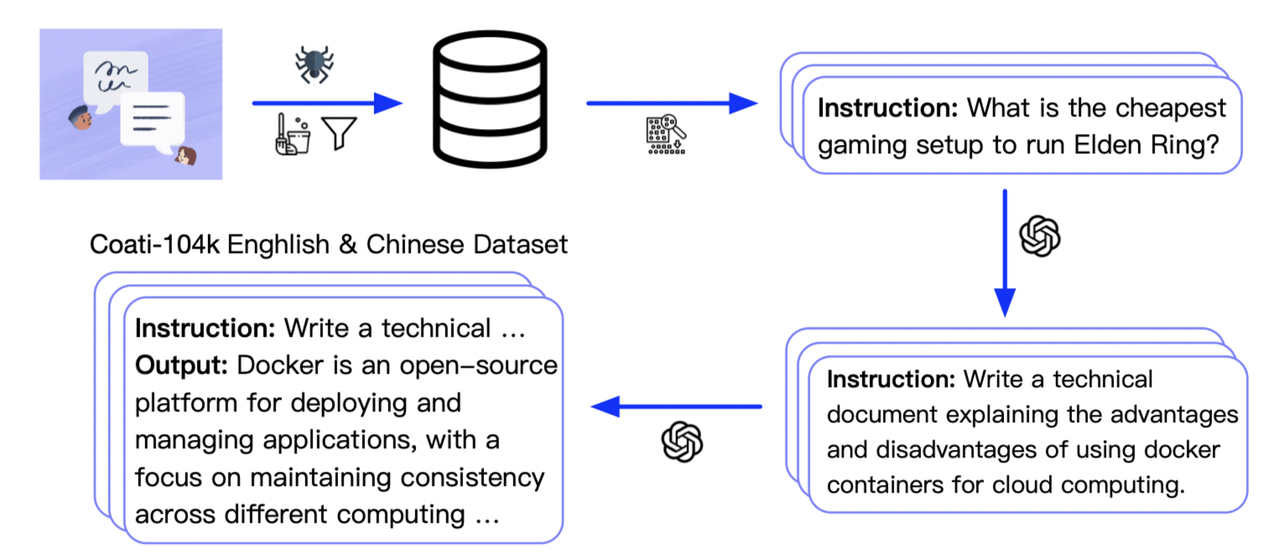
我们从 Twitter 上抓取了超过 700 条噪声指令,并过滤掉了噪声指令。然后我们挑选了 429 条清洁指令以确保高质量。
我们使用了与 Alpaca 类似的方法来收集指令。然而,我们不需要指令的输出,因此避免了人工参与。生成的提示比 Alpaca 的更加多样化,涵盖了更多主题。
我们提供 5 个提示作为示例,用于从 OpenAI API 生成新指令。在收集提示后,我们从 OpenAI API 收集这些指令的回应。英文和中文数据集是分别生成的。总共花费了 880 美元来收集数据集。英文有 5.2 万条指令(约 2400 万个标记),中文也有 5.2 万条指令。
InstructWild 有多好?
Colossal AI 使用我们的模型训练了 ColossalChat 模型。ColossalChat-7B(仅在第一阶段之后)结合了原始的 alpaca 数据集和我们的数据集。我们将 ColossalChat-7B 与 Alpaca-7B 进行比较,看看我们的数据集带来了哪些改进。
评估聊天机器人是困难的。我们对不同类别的指令进行了人工评估。我们的主要发现是:
优点
- 我们的新数据集改善了模型在生成、开放式问答和头脑风暴指令方面的能力。这与我们的数据收集过程相对应。我们的数据是从 Twitter 收集的,用户倾向于分享他们有趣的提示,主要是生成、开放式问答和头脑风暴类型。
基于 LLaMA 微调模型的局限性
- Alpaca 和 ColossalChat 都基于 LLaMA。很难弥补预训练阶段缺失的知识。
- 缺乏计数能力:无法计算列表中的项目数量。
- 缺乏逻辑(推理和计算)。
- 倾向于重复最后一句话(未能生成结束标记)。
- 多语言结果较差:LLaMA 主要在英语数据集上训练(生成表现比问答更好)。
数据集的局限性
- 缺乏总结能力:微调数据集中没有此类指令。
- 缺乏多轮对话和角色扮演:微调数据集中没有此类指令。
- 缺乏自我认知:微调数据集中没有此类指令。
- 缺乏安全性:
- 当输入包含虚假事实时,模型会编造虚假事实和解释。
- 无法遵守 OpenAI 的政策:从 OpenAI API 生成提示时,它总是遵守其政策。因此数据集中没有违规案例。
详细比较
详细比较请参见此处。
待办事项
- 数据集 v1
- 数据集 v2
- 细粒度标注(v2)
- 更大的数据集
作者
本项目目前由以下作者维护:
引用
如果您使用本仓库中的数据或代码,请引用本仓库。
@misc{instructionwild,
author = {Jinjie Ni and Fuzhao Xue and Kabir Jain and Mahir Hitesh Shah and Zangwei Zheng and Yang You },
title = {Instruction in the Wild: A User-based Instruction Dataset},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/XueFuzhao/InstructionWild}},
}











