
 访问官网
访问官网 Github
Github 论文
论文
DragDiffusion: 利用扩散模型进行交互式基于点的图像编辑
施宇俊
薛楚辉
刘俊豪
潘嘉淳
严汉舒
张文清
陈元方
白松




免责声明
这是一个研究项目,而非商业产品。用户可以自由使用该工具创建图像,但应遵守当地法律并负责任地使用。开发者不对用户可能的滥用行为承担任何责任。
新闻与更新
- [1月29日] 更新支持 diffusers==0.24.0!
- [10月23日] DragBench 的代码和数据已发布!详情请查看 "drag_bench_evaluation" 下的 README。
- [10月16日] 在拖拽生成的图像时集成 FreeU。
- [10月3日] 加速编辑真实图像时的 LoRA 训练。(现在在 A100 上仅需约 20 秒!)
- [9月3日] v0.1.0 发布。
- 启用拖拽扩散生成的图像。
- 引入新的引导机制,大大提高拖拽结果的质量。(灵感来自 MasaCtrl)
- 支持拖拽任意纵横比的图像
- 增加对 DPM++Solver 的支持(生成的图像)
- [7月18日] v0.0.1 发布。
- 将 LoRA 训练集成到用户界面。无需使用训练脚本,一切都可以在 UI 中方便完成!
- 优化用户界面布局。
- 支持使用更好的 VAE 处理眼睛和面部(参见 此处)
- [7月8日] v0.0.0 发布。
- 实现 DragDiffusion 的基本功能
安装
建议在配备 Nvidia GPU 的 Linux 系统上运行我们的代码。我们尚未在其他配置上进行测试。目前,运行我们的方法需要约 14 GB 的 GPU 内存。我们将继续优化内存效率。
要安装所需的库,只需运行以下命令:
conda env create -f environment.yaml
conda activate dragdiff
运行 DragDiffusion
首先,在命令行中运行以下命令启动 gradio 用户界面:
python3 drag_ui.py
您可以查看我们上面的 GIF,它逐步演示了 UI 的使用方法。
基本上,它包括以下步骤:
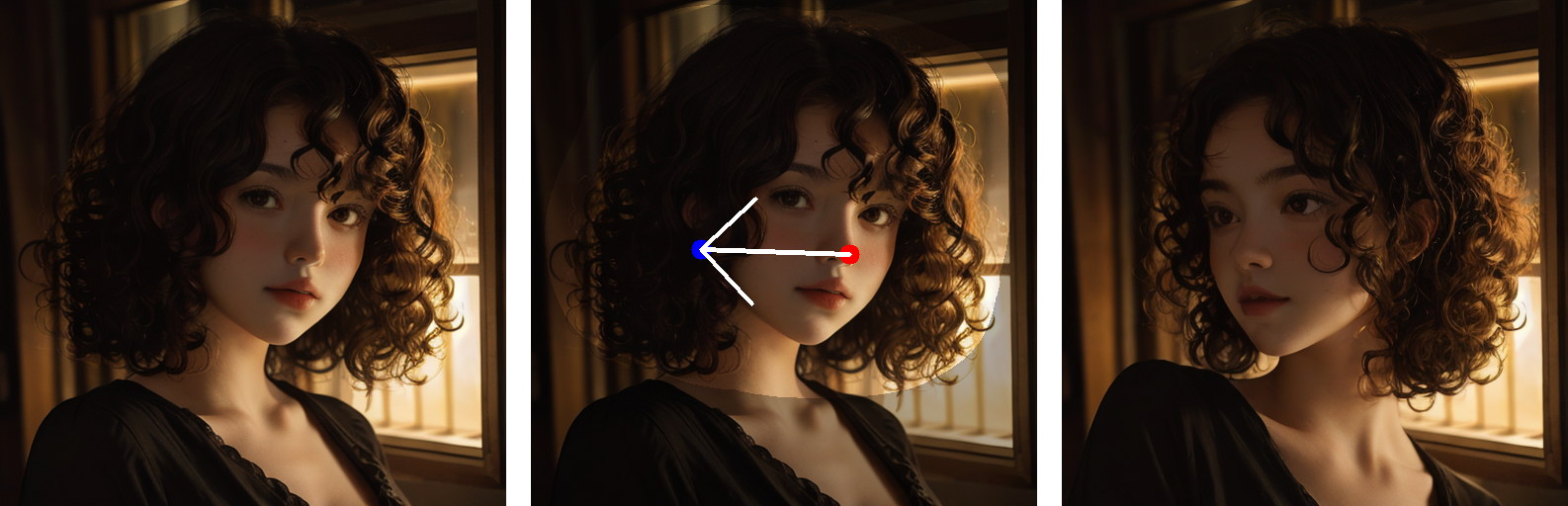
情况 1:拖拽输入的真实图像
1) 训练 LoRA
- 将输入图像拖放到最左侧的框中。
- 在"prompt"字段中输入描述图像的提示词
- 点击"Train LoRA"按钮,根据输入图像训练 LoRA
2) 进行"拖拽"编辑
- 在最左侧的框中绘制蒙版,指定可编辑区域。
- 在中间框中点击控制点和目标点。此外,您可以通过点击"Undo point"重置所有点。
- 点击"Run"按钮运行我们的算法。编辑结果将显示在最右侧的框中。
情况 2:拖拽扩散生成的图像
1) 生成图像
- 填写生成参数(例如,正面/负面提示词,Generation Config 和 FreeU Parameters 下的参数)。
- 点击"Generate Image"。
2) 对生成的图像进行"拖拽"
-
在最左侧的框中绘制蒙版,指定可编辑区域。
-
在中间框中点击控制点和目标点。
-
点击"Run"按钮运行我们的算法。编辑结果将显示在最右侧的框中。 |参数|说明| |-----|------| |扩散模型路径|扩散模型的路径。默认使用"runwayml/stable-diffusion-v1-5"。我们将在未来支持更多模型。| |VAE选择|VAE的选择。目前有两个选项,一个是"default",将使用原始VAE。另一个选项是"stabilityai/sd-vae-ft-mse",可以改善人眼和面部图像的效果(详见解释)|
-
拖拽参数
| 参数 | 说明 |
|---|---|
| n_pix_step | 运动监督的最大步数。如果控制点未被"拖拽"到理想位置,请增加此值。 |
| lam | 控制未遮罩区域保持不变的正则化系数。如果未遮罩区域的变化超出预期,请增加此值(大多数情况下无需调整)。 |
| n_actual_inference_step | 执行的DDIM逆转步数(大多数情况下无需调整)。 |
- LoRA参数
| 参数 | 说明 |
|---|---|
| LoRA训练步数 | LoRA训练的步数(大多数情况下无需调整)。 |
| LoRA学习率 | LoRA的学习率(大多数情况下无需调整) |
| LoRA秩 | LoRA的秩(大多数情况下无需调整)。 |
--->
许可证
与DragDiffusion算法相关的代码采用Apache 2.0许可证。
BibTeX
如果您觉得我们的仓库有帮助,请考虑给我们一个星标或引用我们的论文 :)
@article{shi2023dragdiffusion,
title={DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing},
author={Shi, Yujun and Xue, Chuhui and Pan, Jiachun and Zhang, Wenqing and Tan, Vincent YF and Bai, Song},
journal={arXiv preprint arXiv:2306.14435},
year={2023}
}
联系方式
如对本项目有任何问题,请联系Yujun(shi.yujun@u.nus.edu)
致谢
本工作受到了令人惊叹的DragGAN的启发。LoRA训练代码修改自diffusers的一个示例。图像样本收集自unsplash、pexels、pixabay。最后,非常感谢所有令人惊叹的开源扩散模型和库。
相关链接
- Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
- MasaCtrl: Tuning-free Mutual Self-Attention Control for Consistent Image Synthesis and Editing
- Emergent Correspondence from Image Diffusion
- DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models
- FreeDrag: Point Tracking is Not You Need for Interactive Point-based Image Editing
常见问题及解决方案
- 对于因网络限制而难以从huggingface加载模型的用户,请1)按照此链接下载模型到"local_pretrained_models"目录;2)运行"drag_ui.py"并在"算法参数 -> 基础模型配置 -> 扩散模型路径"中选择您的预训练模型目录。












{kind=link}