
 Github
Github Huggingface
Huggingface 论文
论文AniPortrait
AniPortrait:音频驱动的真实感人像动画合成
作者:魏华伟、杨泽骏、王志胜
机构:腾讯游戏智绘、腾讯

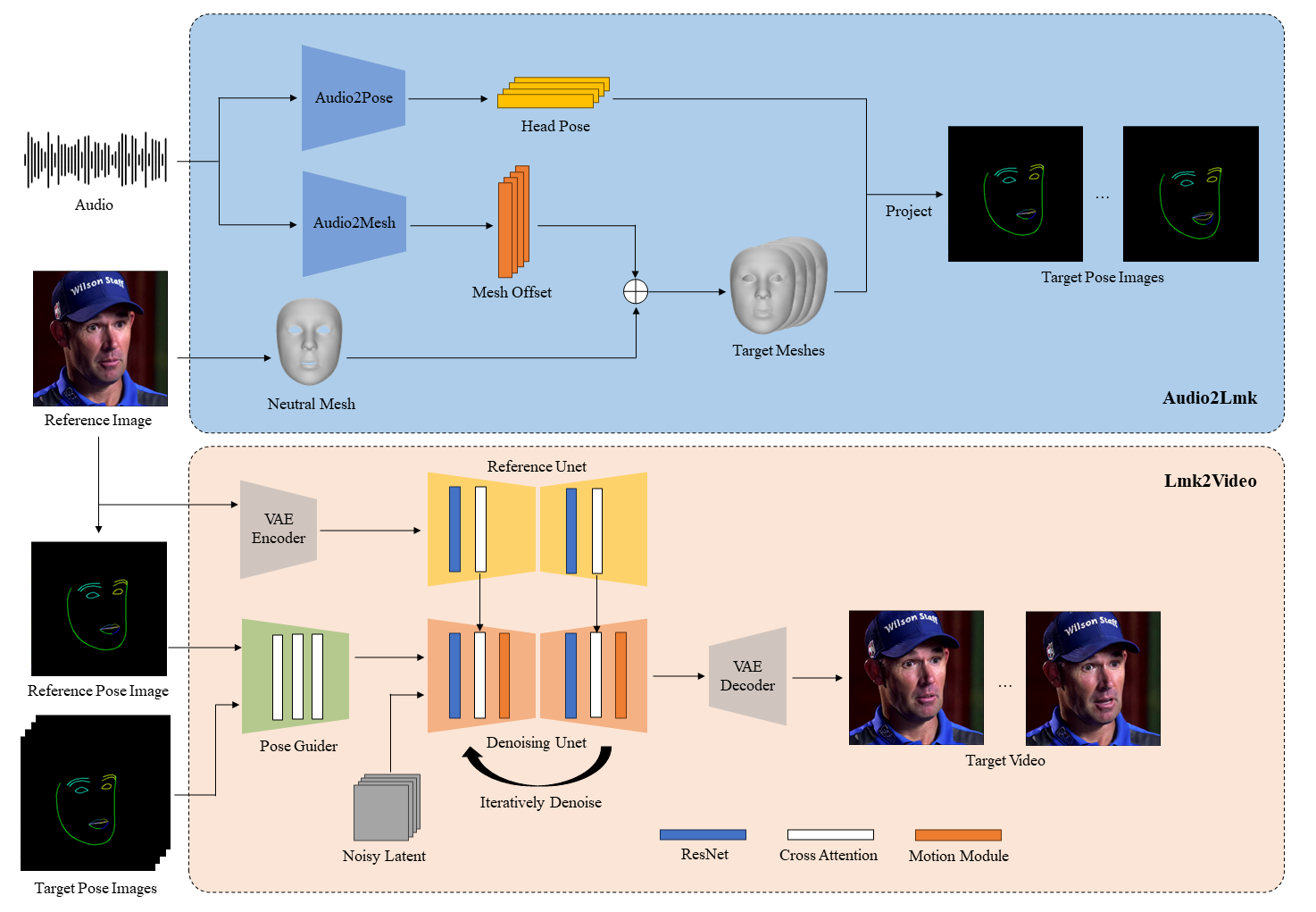
我们在此提出AniPortrait,这是一个新颖的框架,用于生成由音频和参考人像图像驱动的高质量动画。您还可以提供视频来实现面部重演。
流程
更新 / 待办事项
-
✅ [2024/03/27] 我们的论文现已在arXiv上发布。
-
✅ [2024/03/27] 更新代码以生成pose_temp.npy用于头部姿势控制。
-
✅ [2024/04/02] 更新了vid2vid的新姿势重定向策略。现在我们支持参考图像和源视频之间的实质性姿势差异。
-
✅ [2024/04/03] 我们在HuggingFace Spaces上发布了Gradio 演示(感谢HF团队提供免费GPU支持)!
-
✅ [2024/04/07] 更新了帧插值模块以加速推理过程。现在您可以在推理命令中添加-acc以获得更快的视频生成。
-
✅ [2024/04/21] 我们已发布audio2pose模型和音频到视频的预训练权重。请更新代码并下载权重文件以体验。
各种生成的视频
自驱动
面部重演
视频来源:鹿火CAVY from bilibili
音频驱动
安装
构建环境
我们推荐Python版本 >=3.10 和CUDA版本 =11.7。然后按如下方式构建环境:
pip install -r requirements.txt
下载权重
所有权重应放置在 ./pretrained_weights 目录下。您可以按以下方式手动下载权重:
-
下载我们训练的权重,其中包括以下部分:
denoising_unet.pth、reference_unet.pth、pose_guider.pth、motion_module.pth、audio2mesh.pt、audio2pose.pt和film_net_fp16.pt。您也可以从 wisemodel 下载。 -
下载基础模型和其他组件的预训练权重:
最后,这些权重应按如下方式组织:
./pretrained_weights/
|-- image_encoder
| |-- config.json
| `-- pytorch_model.bin
|-- sd-vae-ft-mse
| |-- config.json
| |-- diffusion_pytorch_model.bin
| `-- diffusion_pytorch_model.safetensors
|-- stable-diffusion-v1-5
| |-- feature_extractor
| | `-- preprocessor_config.json
| |-- model_index.json
| |-- unet
| | |-- config.json
| | `-- diffusion_pytorch_model.bin
| `-- v1-inference.yaml
|-- wav2vec2-base-960h
| |-- config.json
| |-- feature_extractor_config.json
| |-- preprocessor_config.json
| |-- pytorch_model.bin
| |-- README.md
| |-- special_tokens_map.json
| |-- tokenizer_config.json
| `-- vocab.json
|-- audio2mesh.pt
|-- audio2pose.pt
|-- denoising_unet.pth
|-- film_net_fp16.pt
|-- motion_module.pth
|-- pose_guider.pth
`-- reference_unet.pth
注意:如果您已经安装了一些预训练模型,比如 StableDiffusion V1.5,您可以在配置文件中指定它们的路径(例如 ./config/prompts/animation.yaml)。
Gradio Web界面
您可以通过以下命令尝试我们的网页演示。我们还在Hugging Face Spaces提供在线演示。
python -m scripts.app
推理
请注意,您可以在命令中设置 -L 为所需生成的帧数,例如 -L 300。
加速方法:如果生成视频需要很长时间,您可以下载 film_net_fp16.pt 并将其放在 ./pretrained_weights 目录下。然后在命令中添加 -acc。
以下是运行推理脚本的命令行指令:
自驱动
python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 512 -acc
您可以参考 animation.yaml 的格式来添加您自己的参考图像或姿势视频。要将原始视频转换为姿势视频(关键点序列),您可以运行以下命令:
python -m scripts.vid2pose --video_path pose_video_path.mp4
人脸重演
python -m scripts.vid2vid --config ./configs/prompts/animation_facereenac.yaml -W 512 -H 512 -acc
在 animation_facereenac.yaml 中添加源人脸视频和参考图像。
音频驱动
python -m scripts.audio2vid --config ./configs/prompts/animation_audio.yaml -W 512 -H 512 -acc
在 animation_audio.yaml 中添加音频和参考图像。
删除 ./configs/prompts/animation_audio.yaml 中的 pose_temp 可以启用 audio2pose 模型。
您还可以使用此命令生成用于头部姿势控制的 pose_temp.npy:
python -m scripts.generate_ref_pose --ref_video ./configs/inference/head_pose_temp/pose_ref_video.mp4 --save_path ./configs/inference/head_pose_temp/pose.npy
训练
数据准备
从原始视频中提取关键点并编写训练json文件(这里以处理VFHQ为例):
python -m scripts.preprocess_dataset --input_dir VFHQ_PATH --output_dir SAVE_PATH --training_json JSON_PATH
更新训练配置文件中的行:
data:
json_path: JSON_PATH
第一阶段
运行命令:
accelerate launch train_stage_1.py --config ./configs/train/stage1.yaml
第二阶段
将预训练的运动模块权重 mm_sd_v15_v2.ckpt(下载链接)放在 ./pretrained_weights 下。
在配置文件 stage2.yaml 中指定第一阶段的训练权重,例如:
stage1_ckpt_dir: './exp_output/stage1'
stage1_ckpt_step: 30000
运行命令:
accelerate launch train_stage_2.py --config ./configs/train/stage2.yaml
致谢
我们首先感谢 EMO 的作者,我们的演示中部分图像和音频来自EMO。此外,我们要感谢 Moore-AnimateAnyone、majic-animate、animatediff 和 Open-AnimateAnyone 仓库的贡献者,感谢他们的开放研究和探索。
引用
@misc{wei2024aniportrait,
title={AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animations},
author={Huawei Wei and Zejun Yang and Zhisheng Wang},
year={2024},
eprint={2403.17694},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











