
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文JudgeLM: 经过微调的大语言模型可作为可扩展的评判器
概述
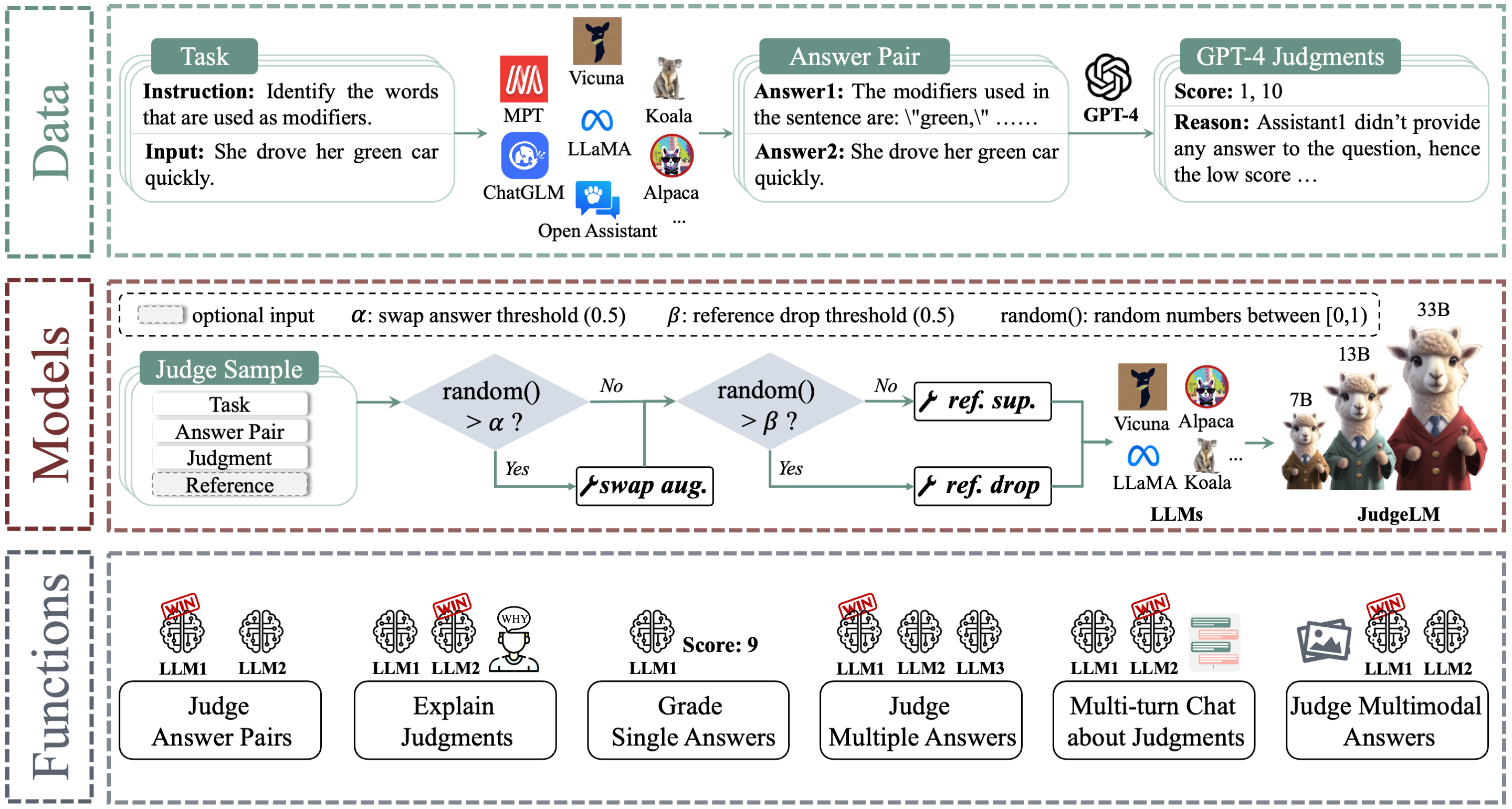
摘要
在开放式场景中评估大语言模型(LLMs)具有挑战性,因为现有的基准和指标无法全面衡量它们。为解决这个问题,我们提出通过微调LLMs作为可扩展的评判器(JudgeLM),以在开放式基准中高效有效地评估LLMs。我们首先提出了一个全面的、大规模的、高质量的数据集,包含用于微调高性能评判器的任务种子、LLMs生成的答案和GPT-4生成的判断,以及一个用于评估评判器的新基准。我们训练了不同规模的JudgeLM,从7B、13B到33B参数,并对其能力和行为进行了系统分析。然后,我们分析了将LLM微调为评判器的关键偏差,并将其视为位置偏差、知识偏差和格式偏差。为解决这些问题,JudgeLM引入了一系列技术,包括交换增强、参考支持和参考丢弃,这些技术显著提高了评判器的性能。JudgeLM在现有的PandaLM基准和我们提出的新基准上都获得了最先进的评判器性能。我们的JudgeLM效率很高,JudgeLM-7B只需3分钟就可以用8个A100 GPU评判5K个样本。JudgeLM与教师评判器达成了高度一致,一致性超过90%,甚至超过了人与人之间的一致性。JudgeLM还展示了扩展能力,可以作为单一答案、多模态模型、多个答案和多轮对话的评判器。JudgeLM是一个用于训练、服务和评估可扩展大语言模型评判器的开放平台。
- JudgeLM是一个可扩展的语言模型评判器,旨在评估开放式场景中的LLMs。它实现了超过90%的一致性,超过了人与人之间的一致性。
- JudgeLM数据集包含10万个用于训练的评判样本和5千个用于验证的评判样本。所有评判样本都有GPT-4生成的高质量判断。
JudgeLM的核心特性包括:
- 用于训练和评估最先进LLM评判器的代码。
- 处理扩展任务的广泛能力。(例如,单一答案、多模态模型、多个答案和多轮对话的评判)
- 具有Web用户界面的分布式多模型服务系统。
新闻
- [2023年10月] 我们发布了JudgeLM:经过微调的大语言模型可作为可扩展的评判器。查看论文。
目录
安装:从源代码
- 克隆此仓库并进入JudgeLM文件夹
git clone https://github.com/baaivision/JudgeLM
cd JudgeLM
- 安装包
conda create -n judgelm python=3.10.10 -y
conda activate judgelm
pip3 install --upgrade pip
pip3 install -e .
pip install flash-attn==2.0.4 --no-build-isolation
模型权重
JudgeLM基于LLaMA,应在LLaMA的模型许可下使用。
| 模型 | 是否有参考? | 一致性↑ | 精确度↑ | 召回率↑ | F1↑ | 一致性↑ |
|---|---|---|---|---|---|---|
| JudgeLM-7B | ❎ | 81.11 | 69.67 | 78.39 | 72.21 | 83.57 |
| JudgeLM-7B | ✅ | 84.08 | 75.92 | 82.55 | 78.28 | 84.46 |
| JudgeLM-13B | ❎ | 84.33 | 73.69 | 80.51 | 76.17 | 85.01 |
| JudgeLM-13B | ✅ | 85.47 | 77.71 | 82.90 | 79.77 | 87.23 |
| JudgeLM-33B 🔥 | ❎ | 89.03 | 80.97 | 84.76 | 82.64 | 91.36 |
| JudgeLM-33B 🔥 | ✅ | 89.32 | 84.00 | 86.21 | 84.98 | 92.37 |
评估
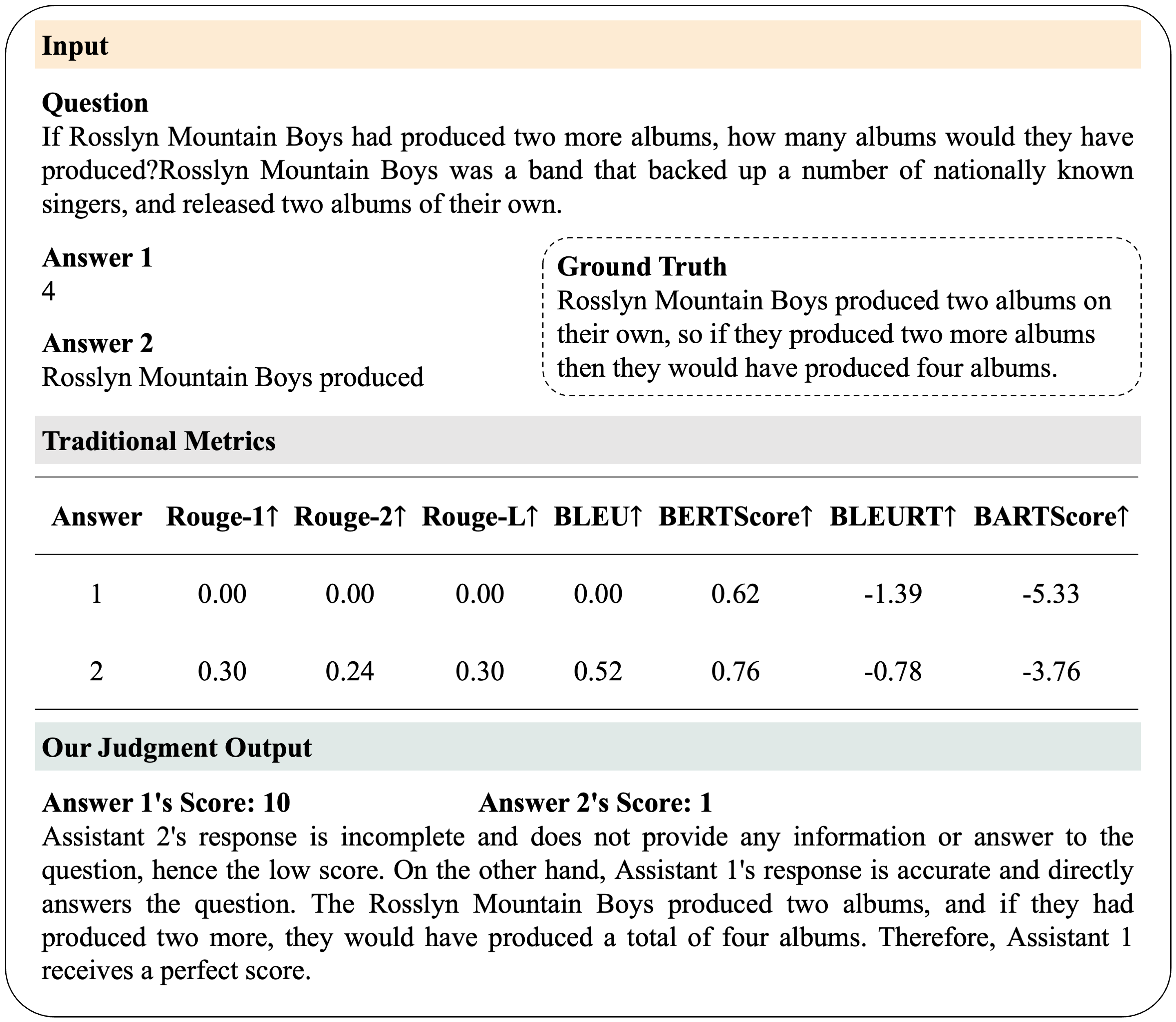

JudgeLM可以评判LLMs的开放式答案,以及多模态模型。 请参阅 judgelm/llm_judge 中的 JudgeLM 运行说明。
使用网页图形界面提供服务
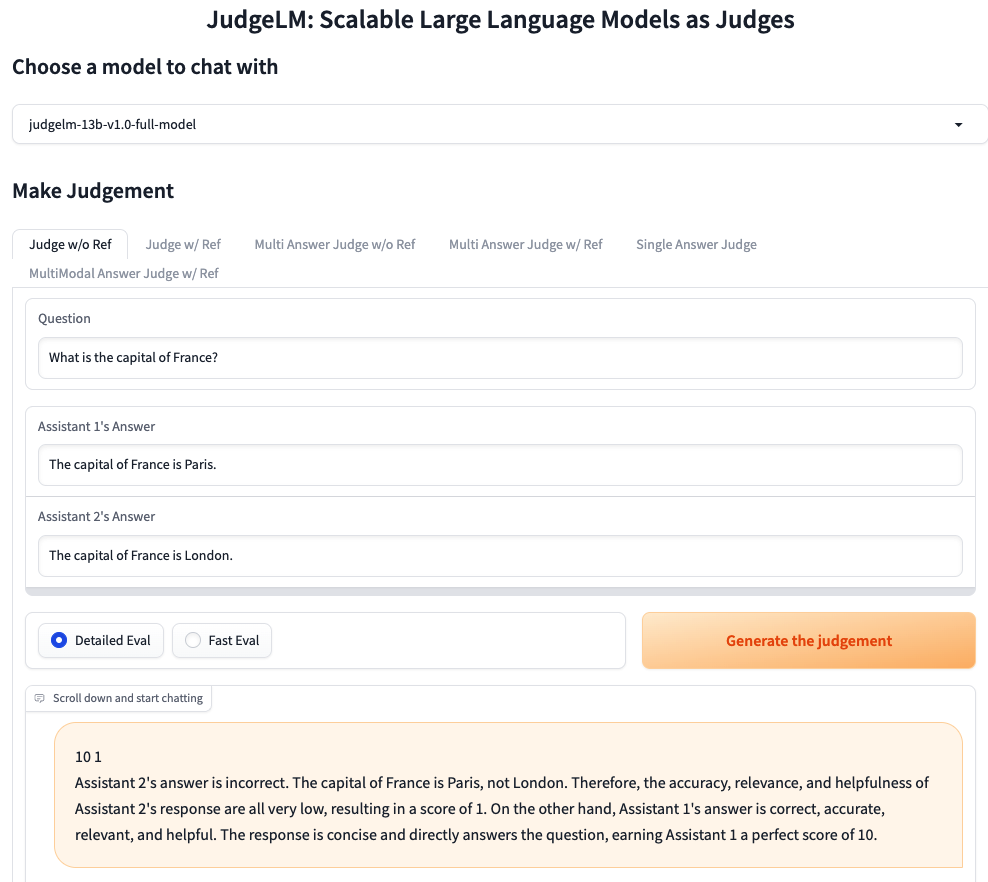
我们使用 gradio 为用户提供网络服务器和界面,以评估大语言模型在开放式任务中的表现。 可以在这里试用演示。
请参阅 judgelm/serve 中运行 JudgeLM 网络服务器的说明。
微调
数据
JudgeLM-100K 数据集可在 HuggingFace Datasets 获取。
代码和超参数
我们的代码基于 Vicuna,并增加了对答案对评判的支持。 我们使用的超参数与 Vicuna 相似。
| 超参数 | 全局批量大小 | 学习率 | 训练轮数 | 最大长度 | 权重衰减 |
|---|---|---|---|---|---|
| JudgeLM-13B | 128 | 2e-5 | 3 | 2048 | 0 |
使用本地 GPU 微调 JudgeLM-7B
- 您可以使用以下命令在 4 个 A100 (40GB) 上训练 JudgeLM-7B。请将
--model_name_or_path更新为 Vicuna 权重的实际路径,将--data_path更新为 JudgeLM 数据的实际路径。
torchrun --nproc_per_node=4 --master_port=20001 judgelm/train/train_mem.py \
--model_name_or_path="/share/project/lianghuizhu/vicuna-weights-collection-v1.3/vicuna-7b-v1.3" \
--data_path /share/project/lianghuizhu/JudgeLM-Project/JudgeLM/judgelm/data/JudgeLM/judgelm_train_100k.jsonl \
--bf16 True \
--output_dir="/home/zhulianghui/ProjectC_ChatGPT/alpaca/output/judgelm-debug-evaluator" \
--num_train_epochs 3 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 32 \
--evaluation_strategy no \
--save_strategy steps \
--save_steps 1000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--fsdp "full_shard auto_wrap offload" \
--fsdp_transformer_layer_cls_to_wrap "LlamaDecoderLayer" \
--tf32 True \
--model_max_length 2048 \
--gradient_checkpointing True \
--run_name 7B-full-model \
--swap_aug_ratio 0.5 \
--ref_drop_ratio 0.5
提示:
- 如果您使用的是不支持 FlashAttention 的 V100,可以使用 xFormers 中实现的内存高效注意力。安装 xformers 并将上面的
judgelm/train/train_mem.py替换为 judgelm/train/train_xformers.py。 - 如果您遇到由于 "FSDP Warning: When using FSDP, it is efficient and recommended... " 导致的内存不足,请参见这里的解决方案。
- 如果您在模型保存过程中遇到内存不足,请参见这里的解决方案。
致谢 :heart:
本项目基于 Vicuna(博客,代码)、PandaLM(论文,代码)、LLM-Blender(论文,代码)。感谢他们出色的工作。
引用
本仓库中的代码(训练、服务和评估)主要是为以下论文开发或源自该论文。 如果您觉得本仓库有帮助,请引用它。
@article{zhu2023judgelm,
title={JudgeLM: Fine-tuned Large Language Models are Scalable Judges},
author={Lianghui Zhu and Xinggang Wang and Xinlong Wang},
year={2023},
eprint={2310.17631},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











