
 访问官网
访问官网 Github
Github 文档
文档Crawlab






中文 | 英文
安装 | 运行 | 截图 | 架构 | 集成 | 比较 | 社区与赞助 | 更新日志 | 免责声明
基于Golang的分布式网络爬虫管理平台,支持多种语言包括Python、NodeJS、Go、Java、PHP以及各种网络爬虫框架如Scrapy、Puppeteer、Selenium。
安装
你可以参照安装指南。
快速开始
请打开命令行界面并执行以下命令。确保你已经预先安装了docker-compose。
git clone https://github.com/crawlab-team/examples
cd examples/docker/basic
docker-compose up -d
接下来,你可以查看docker-compose.yml(包含详细配置参数)和文档以获取更多信息。
运行
Docker
请使用docker-compose一键启动。这样,你甚至不需要配置MongoDB数据库。创建一个名为docker-compose.yml的文件并输入以下代码。
version: '3.3'
services:
master:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_master
environment:
CRAWLAB_NODE_MASTER: "Y"
CRAWLAB_MONGO_HOST: "mongo"
volumes:
- "./.crawlab/master:/root/.crawlab"
ports:
- "8080:8080"
depends_on:
- mongo
worker01:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_worker01
environment:
CRAWLAB_NODE_MASTER: "N"
CRAWLAB_GRPC_ADDRESS: "master"
CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer"
volumes:
- "./.crawlab/worker01:/root/.crawlab"
depends_on:
- master
worker02:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_worker02
environment:
CRAWLAB_NODE_MASTER: "N"
CRAWLAB_GRPC_ADDRESS: "master"
CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer"
volumes:
- "./.crawlab/worker02:/root/.crawlab"
depends_on:
- master
mongo:
image: mongo:4.2
container_name: crawlab_example_mongo
restart: always
然后执行以下命令,Crawlab主节点和工作节点 + MongoDB将启动。打开浏览器并输入http://localhost:8080查看用户界面。
docker-compose up -d
关于Docker部署的详细信息,请参阅相关文档。
截图
登录

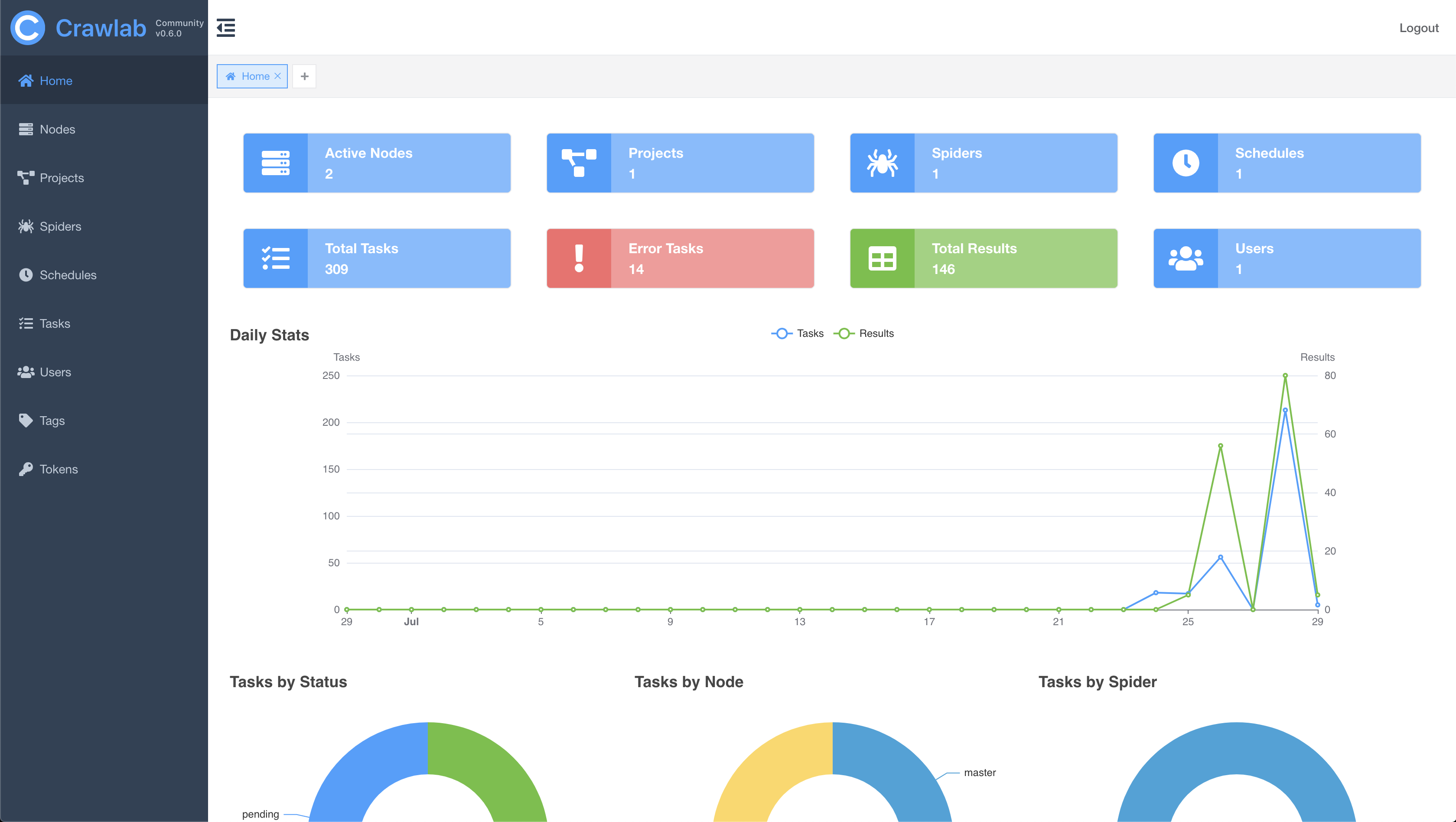
主页

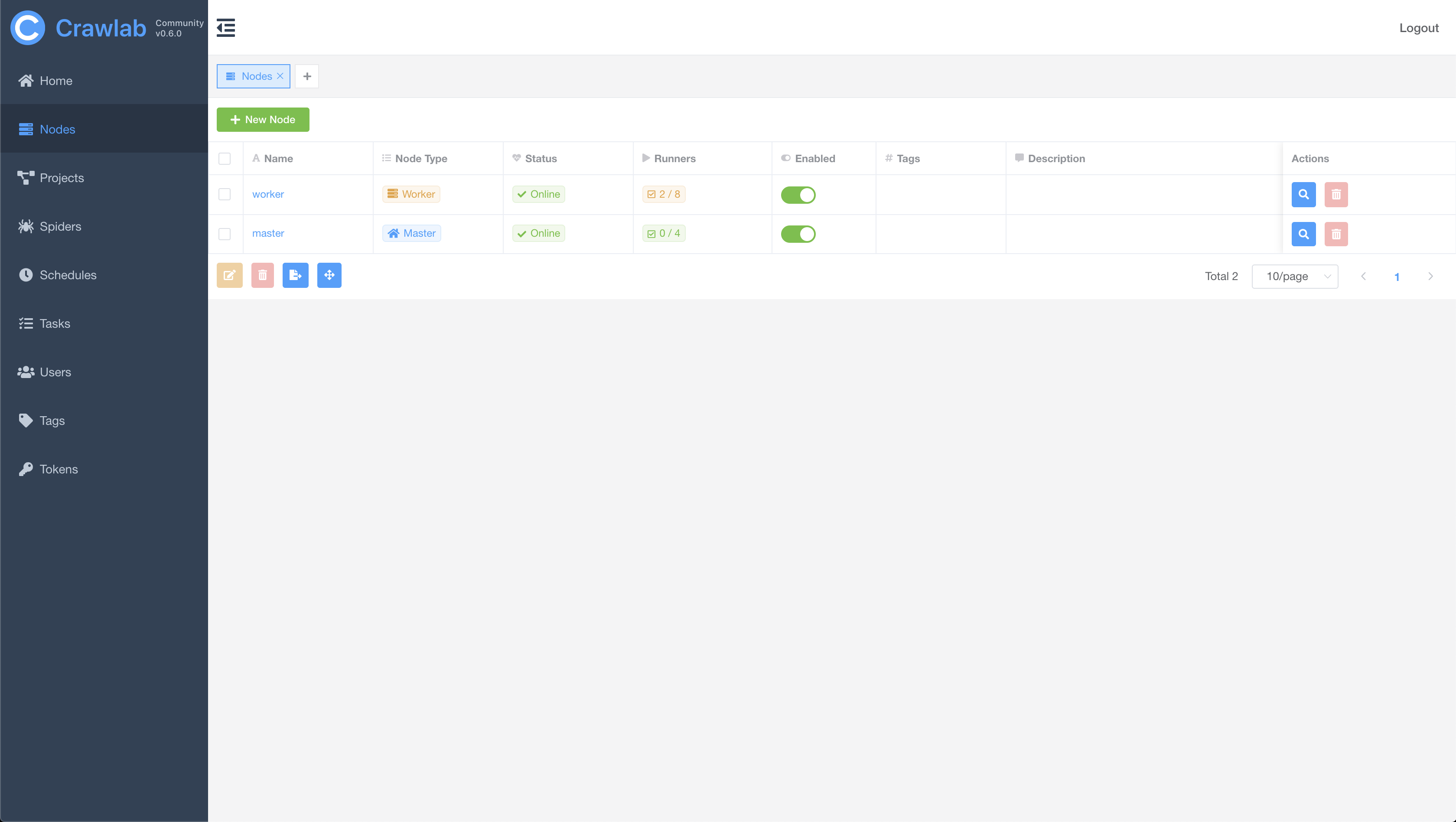
节点列表

爬虫列表

爬虫概览

爬虫文件

任务日志

任务结果

定时任务

架构
Crawlab的架构由一个主节点、工作节点、SeaweedFS(一个分布式文件系统)和MongoDB数据库组成。
 前端应用与主节点交互,主节点与其他组件如MongoDB、SeaweedFS和工作节点通信。主节点和工作节点通过gRPC(一个RPC框架)相互通信。任务由主节点中的任务调度器模块调度,并由工作节点中的任务处理器模块接收,然后在任务运行器中执行这些任务。任务运行器实际上是运行爬虫或爬虫程序的进程,也可以通过gRPC(集成在SDK中)向其他数据源(如MongoDB)发送数据。
前端应用与主节点交互,主节点与其他组件如MongoDB、SeaweedFS和工作节点通信。主节点和工作节点通过gRPC(一个RPC框架)相互通信。任务由主节点中的任务调度器模块调度,并由工作节点中的任务处理器模块接收,然后在任务运行器中执行这些任务。任务运行器实际上是运行爬虫或爬虫程序的进程,也可以通过gRPC(集成在SDK中)向其他数据源(如MongoDB)发送数据。
主节点
主节点是Crawlab架构的核心。它是Crawlab的中央控制系统。
主节点提供以下服务:
- 任务调度;
- 工作节点管理和通信;
- 爬虫部署;
- 前端和API服务;
- 任务执行(你可以将主节点视为一个工作节点)
主节点与前端应用通信,并向工作节点发送爬取任务。同时,主节点将爬虫上传(部署)到分布式文件系统SeaweedFS,以供工作节点同步。
工作节点
工作节点的主要功能是执行爬取任务并存储结果和日志,并通过gRPC与主节点通信。通过增加工作节点的数量,Crawlab可以水平扩展,不同的爬取任务可以分配给不同的节点执行。
MongoDB
MongoDB是Crawlab的操作数据库。它存储节点、爬虫、任务、调度等数据。任务队列也存储在MongoDB中。
SeaweedFS
SeaweedFS是由Chris Lu开发的开源分布式文件系统。它可以在分布式系统中稳健地存储和共享文件。在Crawlab中,SeaweedFS主要作为文件同步系统和存储任务日志文件的地方。
前端
前端应用基于Element-Plus构建,这是一个流行的基于Vue 3的UI框架。它与主节点上托管的API交互,并间接控制工作节点。
与其他框架的集成
Crawlab SDK提供了一些helper方法,使您更容易将爬虫集成到Crawlab中,例如保存结果。
Scrapy
在Scrapy项目的settings.py中,找到名为ITEM_PIPELINES的变量(一个dict变量)。添加以下内容。
ITEM_PIPELINES = {
'crawlab.scrapy.pipelines.CrawlabPipeline': 888,
}
然后,启动Scrapy爬虫。完成后,您应该能在任务详情 -> 数据中看到爬取的结果。
通用Python爬虫
请在您的爬虫文件中添加以下内容以保存结果。
# 导入结果保存方法
from crawlab import save_item
# 这是一个结果记录,必须是字典类型
result = {'name': 'crawlab'}
# 调用结果保存方法
save_item(result)
然后,启动爬虫。完成后,您应该能在任务详情 -> 数据中看到爬取的结果。
其他框架/语言
爬取任务实际上是通过shell命令执行的。任务ID将以名为CRAWLAB_TASK_ID的环境变量的形式传递给爬取任务进程。通过这种方式,数据可以与任务关联。
与其他框架的比较
已经存在一些爬虫管理框架。那么为什么要使用Crawlab呢?
原因是大多数现有平台都依赖于Scrapyd,这将选择限制在Python和Scrapy之内。当然,Scrapy是一个很棒的网络爬虫框架,但它不能做所有事情。
Crawlab易于使用,足够通用以适应任何语言和任何框架的爬虫。它还有一个漂亮的前端界面,让用户更容易管理爬虫。
| 框架 | 技术 | 优点 | 缺点 | Github统计 |
|---|---|---|---|---|
| Crawlab | Golang + Vue | 不限于Scrapy,适用于所有编程语言和框架。漂亮的UI界面。天然支持分布式爬虫。支持爬虫管理、任务管理、定时任务、结果导出、分析、通知、可配置爬虫、在线代码编辑器等。 | 尚不支持爬虫版本控制 |   |
| ScrapydWeb | Python Flask + Vue | 漂亮的UI界面,内置Scrapy日志解析器,任务执行的统计和图表,支持节点管理、定时任务、邮件通知、移动端。功能齐全的爬虫管理平台。 | 不支持Scrapy以外的爬虫。由于Python Flask后端,性能有限。 |   |
| Gerapy | Python Django + Vue | Gerapy由网络爬虫大师Germey Cui构建。安装和部署简单。漂亮的UI界面。支持节点管理、代码编辑、可配置爬取规则等。 | 同样不支持Scrapy以外的爬虫。根据用户反馈,v1.0中存在许多bug。期待v2.0的改进 |   |
| SpiderKeeper | Python Flask | 开源的Scrapyhub。简洁的UI界面。支持定时任务。 | 可能过于简化,不支持分页,不支持节点管理,不支持Scrapy以外的爬虫。 |   |
贡献者






JetBrains 支持

社区
如果您觉得Crawlab能够有益于您的日常工作或公司,请添加作者的微信账号,注明"Crawlab"以进入讨论群。












{kind=link}
{kind=link}
{kind=link}