
 访问官网
访问官网 Github
Github 论文
论文RLcycle



RLcycle(发音为"recycle")是一个强化学习(RL)代理框架。RLcycle提供现成的RL代理,以及可重用的组件,便于快速原型开发。
目前,RLcycle提供:
- DQN及其增强版本,分布式:C51、分位数回归、Rainbow-DQN。
- 用于参数空间噪声的噪声网络
- A2C(数据并行)和A3C(梯度并行)。
- DDPG,包括Lillicrap等人(2015)和Fujimoto等人(2018)的版本。
- 具有自动熵系数调整的软演员评论家算法。
- 所有离线策略算法的优先经验回放和n步更新。
RLcycle使用:
请参阅下文了解RLcycle的介绍和使用指南、性能基准测试以及未来计划。
贡献
如果你有任何问题或建议,欢迎提出问题或通过cjy2129 [at] columbia [dot] edu联系我们!
入门指南
安装方法:
conda create --name myenv python=3.6.9 pip
conda activate myenv
git clone https://github.com/cyoon1729/RLcycle.git
cd RLcycle
pip install -U -r requirements.txt
pip install -e .
0. 快速了解Hydra管理配置
让我们首先看看Hydra可以做的许多有用的事情之一:"""从yaml文件实例化类"""
# 在 ./examples/rectangle.yaml 中
shape:
class: examples.shapes.Rectangle
params:
height: 5
width: 4
使用hydra按照上述yaml文件初始化shapes.Rectangle:
"""从yaml文件实例化类"""
# 在 ./examples/shapes.py 中
class Rectangle:
def __init__(self, width: float, height: float):
self.width = width
self.height = height
def get_area(self):
return width * height
# 在 ./examples/main.py 中
import hydra
from omegaconf import DictConfig
@hydra.main(config_path="./examples/rectangle.yaml")
def main(cfg: DictConfig):
shape = hydra.utils.instantiate(layer_info)
print(shape.__class__.__name__) # 'Rectangle'
print(shape.get_area()) # 20
if __main__ == "__main__":
main()
如果你想了解更多关于Hydra的信息,请查看<a href=https://hydra.cc/>他们的文档!
1. 运行实验
运行run_agent.py文件,并按以下方式指定实验配置:
python run_agent.py configs=atari/rainbow_dqn
或者,你可以在metaconfig.yaml中指定配置(yaml)文件。
# 在 ./metaconfig.yaml 中
defaults:
- configs=atari/rainbow_dqn
要修改实验参数或超参数,你可以添加如下标志:
python run_agent.py configs=atari/rainbow_dqn configs.experiment_info.env.name=AlienNoFrameskip-v4
python run_agent.py configs=atari/rainbow_dqn configs.hyper_params.batch_size=64
python run_agent.py configs=pybullet/sac configs.hyper_params.batch_size=64
2. 为RLcycle构建配置
以`atari/rainbow_dqn.yaml`为例:experiment_info:
experiment_name: Rainbow DQN
agent: rlcycle.dqn_base.agent.DQNBaseAgent
learner: rlcycle.dqn_base.learner.DQNLearner
loss: rlcycle.dqn_base.loss.CategoricalLoss
action_selector: rlcycle.dqn_base.action_selector.CategoricalActionSelector
device: cuda
log_wandb: True
# 环境信息
env:
name: "PongNoFrameskip-v4"
is_atari: True
is_discrete: True
frame_stack: True
# 实验默认参数:
total_num_episodes: 5000
test_interval: 100 # 每50个回合测试一次
test_num: 5 # 测试阶段的回合数
render_train: False # 训练期间渲染所有回合步骤
render_test: True # 渲染测试
defaults:
- hyper_params: rainbow
- models: duelingC51
在experiment_info下,我们有运行RL实验的基本参数:我们想要使用的类(代理、学习器、损失函数),以及gym环境和实验配置。
defaults指向rlcycle/configs/atari/hyper_params/rainbow.yaml获取超参数,以及rlcycle/configs/atari/models/duelingC51.yaml获取模型配置。仔细查看这些文件,我们可以看到:
超参数:
批量大小: 64
重放缓冲区大小: 100000
使用PER: False
PER alpha值: 0.5
PER beta值: 0.4
PER beta最大值: 1.0
PER beta总步数: 300000
# 探索配置
epsilon: 1.0 # epsilon-贪婪探索
最小epsilon值: 0.0 # 探索的最小epsilon值
最大探索帧数: 100000 # epsilon在最多步数内达到最小值
# 其他
更新起始点: 40000 # 当缓冲区存储经验数达到时开始更新步数
gamma: 0.99
tau: 0.005
Q正则化系数: 0.0
梯度裁剪: 10.0
n步: 3
训练频率: 4
# 优化器
学习率: 0.0000625 # 0.0003
权重衰减: 0.0
adam_epsilon: 0.00015
这是一个相当标准的强化学习实验超参数组织方式,以及
模型:
类: rlcycle.common.models.value.DuelingCategoricalDQN
参数:
模型配置:
状态维度: 未定义
动作维度: 未定义
原子数: 51
最小值: -10
最大值: 10
使用卷积: True
使用噪声: True
卷积特征:
特征1:
类: rlcycle.common.models.layers.Conv2DLayer
参数:
输入大小: 4
输出大小: 32
卷积核大小: 8
步长: 4
激活函数: relu
特征2:
类: rlcycle.common.models.layers.Conv2DLayer
参数:
输入大小: 32
输出大小: 64
卷积核大小: 4
步长: 2
激活函数: relu
特征3:
类: rlcycle.common.models.layers.Conv2DLayer
参数:
输入大小: 64
输出大小: 64
卷积核大小: 3
步长: 1
激活函数: relu
优势:
全连接1:
类: rlcycle.common.models.layers.FactorizedNoisyLinearLayer
参数:
输入大小: 未定义
输出大小: 512
后置激活函数: relu
全连接2:
类: rlcycle.common.models.layers.FactorizedNoisyLinearLayer
参数:
输入大小: 512
输出大小: 未定义
后置激活函数: identity
价值:
全连接1:
类: rlcycle.common.models.layers.FactorizedNoisyLinearLayer
参数:
输入大小: 未定义
输出大小: 512
后置激活函数: identity
全连接2:
类: rlcycle.common.models.layers.FactorizedNoisyLinearLayer
参数:
输入大小: 512
输出大小: 1
后置激活函数: identity
这里我们定义了模型及其每一层的参数。注意,值为"未定义"的字段将在相应的Python对象内部定义。对于更简单的模型yaml配置文件,请查看rlcycle/configs/atari/models/dqn.yaml。
额外内容(值得了解):RLcycle如何实例化组件(模型、学习器、智能体等)
RLcycle中的大多数组件都是通过hydra.utils.instantiate实例化的,如上一节所示。
示例:
- 模型:
"""在 ./configs/lunarlander/models/dqn.yaml 中"""
模型:
类: rlcycle.common.models.value.DQNModel
参数:
模型配置:
状态维度: 未定义
动作维度: 未定义
全连接:
输入:
类: rlcycle.common.models.layers.LinearLayer
参数:
输入大小: 未定义
输出大小: 128
后置激活函数: relu
隐藏:
隐藏1:
类: rlcycle.common.models.layers.LinearLayer
参数:
输入大小: 128
输出大小: 128
后置激活函数: relu
隐藏2:
类: rlcycle.common.models.layers.LinearLayer
参数:
输入大小: 128
输出大小: 128
后置激活函数: relu
输出:
类: rlcycle.common.models.layers.LinearLayer
参数:
输入大小: 128
输出大小: 未定义
后置激活函数: identity
构建上述模型:
"""在 ./rlcycle/build.py 中"""
def build_model(model_cfg: DictConfig, device: torch.device):
"""通过hydra.utils.instantiate()从DictConfigs构建模型"""
model = hydra.utils.instantiate(model_cfg)
return model.to(device)
- 学习器:
# 在 ./rlcycle/dqn_base/agent.py 中
#....
self.learner = build_learner(
self.experiment_info, self.hyper_params, self.model_cfg
)
# ...
# 在 ./rlcycle/build.py 中
def build_learner(
experiment_info: DictConfig, hyper_params: DictConfig, model: DictConfig
):
"""通过hydra.utils.instantiate()从DictConfigs构建学习器"""
learner_cfg = DictConfig(dict())
learner_cfg["class"] = experiment_info.learner
learner_cfg["params"] = dict(
experiment_info=experiment_info,
hyper_params=hyper_params,
model_cfg=model
)
learner = hydra.utils.instantiate(learner_cfg)
return learner
- 智能体:
# 在 ./tests/test_dqn.py 中
@hydra.main(config_path="../configs/lunarlander/dqn.yaml", strict=False)
def main(cfg: DictConfig):
agent = build_agent(**cfg)
agent.train()
# 在 ./rlcycle.build.py 中
def build_agent(
experiment_info: DictConfig, hyper_params: DictConfig, model: DictConfig
):
"""通过hydra.utils.instantiate()从DictConfigs构建智能体"""
agent_cfg = DictConfig(dict())
agent_cfg["class"] = experiment_info.agent
agent_cfg["params"] = dict(
experiment_info=experiment_info,
hyper_params=hyper_params,
model_cfg=model
)
agent = hydra.utils.instantiate(agent_cfg)
return agent
这应该有助于您开始在RLcycle中构建和运行智能体!
基准测试
超参数并未经过严格调优;大多数遵循原始论文中提出的参数,但进行了一些修改以解决内存使用问题。 点击下方下拉菜单!
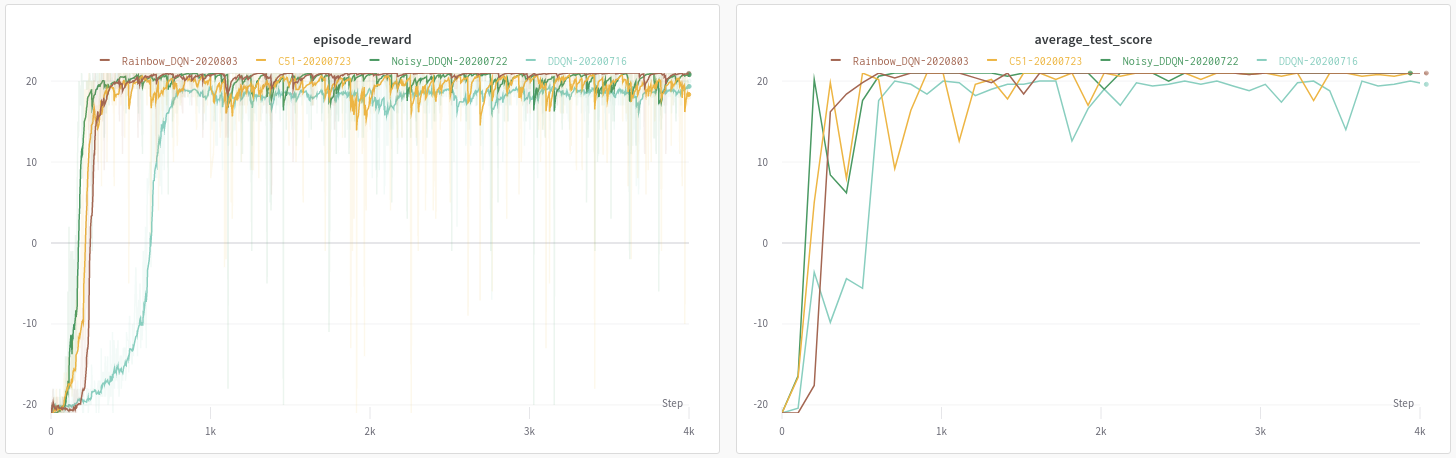
Atari BreakoutNoFrameskip-v4 (即将就绪)
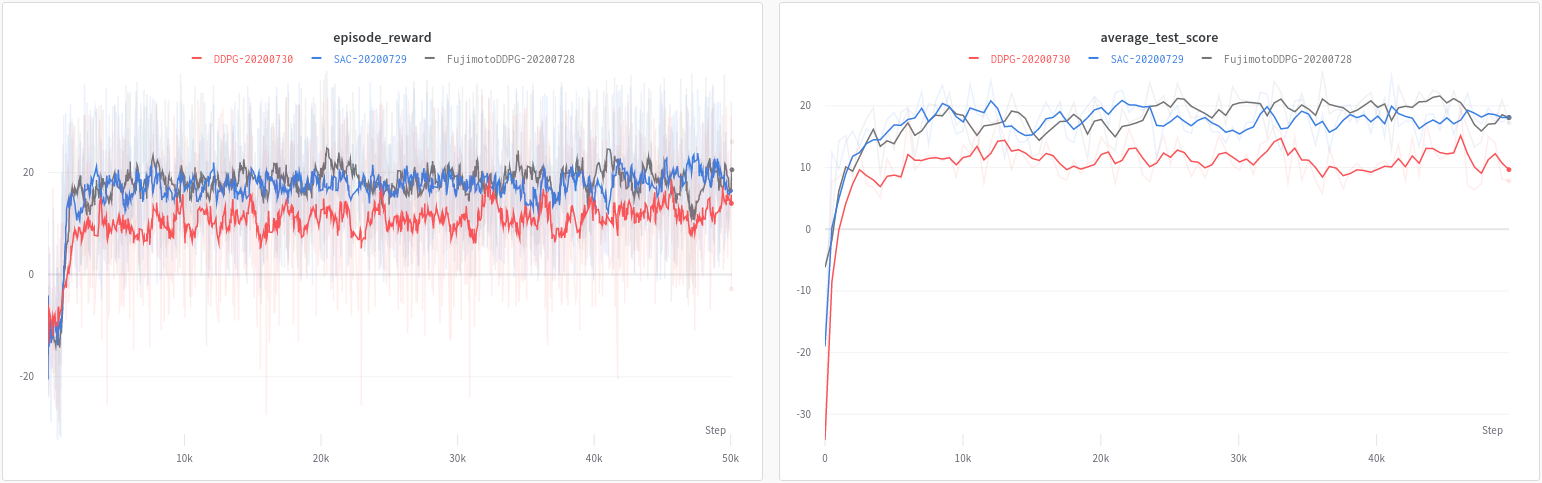
PyBullet HalfCheetah-v2 (即将就绪)
未来计划
以下是我希望在RLcycle中加入的一些内容:
- TRPO和PPO (中等优先级)
- IQN (低优先级)
- 与我的分布式强化学习框架distributedRL兼容。(即所有离线策略算法的Ape-X)。(高优先级)
参考文献
代码库
- 特别感谢@Medipixel!我在这里做出的许多设计选择都基于我在那里实习期间通过他们的开源强化学习框架学到的内容。
- Higgsfield的RL-Adventure 系列。
论文
- "通过深度强化学习实现人类水平的控制。" Mnih等,2015年。
- "深度强化学习的对抗网络架构。" Wang等,2015年。
- "优先经验回放。" Schaul等,2015年。
- "用于探索的噪声网络。" Fortunato等,2017年。
- "强化学习的分布视角。" Bellemare等,2017年。
- "Rainbow:结合深度强化学习的改进。" Hessel等,2017年。
- "基于分位数回归的分布式强化学习。" Dabney等,2017年。
- "深度强化学习的异步方法。" Mnih等,2016年
- "使用深度强化学习进行连续控制。" Lillicrap等,2015年。
- "解决演员-评论家方法中的函数近似误差。" Fujimoto等,2018年
- "软演员-评论家:具有随机演员的离线策略最大熵深度强化学习。" Haarnoja等,2018年
- "软演员-评论家算法及其应用。" Haarnoja等,2019年"











