
 Github
Github 文档
文档 论文
论文 本作品采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可。
AudioDec:开源流式高保真神经音频编解码器
亮点
- 适用于48 kHz单声道语音的流式高保真音频编解码器,比特率为12.8 kbps。
- 在**GPU(约6毫秒)和CPU(约10毫秒,4线程)**上解码延迟极低。
- 高效的两阶段训练(使用预训练模型,为新应用训练编码器仅需几小时)
摘要
适用于实时通信等应用的优秀音频编解码器具有三个关键特性:(1) 压缩,即传输信号所需的比特率应尽可能低;(2) 延迟,即编码和解码信号的速度必须足够快,以实现无延迟或仅有最小可察觉延迟的通信;(3) 信号的重建质量。在本研究中,我们提出了一种开源、可流式传输和实时的神经音频编解码器,在这三个方面都取得了出色的表现:它能以仅12 kbps的比特率重建高度自然的48 kHz语音信号,同时在GPU上运行延迟不到6毫秒,在CPU上运行延迟不到10毫秒。我们还展示了一种高效的训练范式,用于开发适用于实际场景的神经音频编解码器。[论文] [演示]
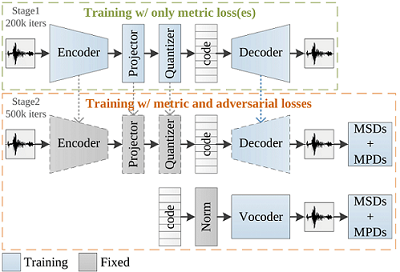
AudioDec的两种模式
- 自动编码器(对称AudioDec,symAD)
1-1. 在前200k次迭代中,仅使用度量损失从头开始训练基于自动编码器的编解码器模型。
1-2. 固定编码器、投影器、量化器和码本,在接下来的500k次迭代中训练解码器和判别器。 - 自动编码器 + 声码器(AD v0,1,2)(推荐!)
2-1. 提取经过训练的编码器提取的代码的统计数据(全局均值和方差)。
2-2. 使用经过训练的编码器和统计数据训练声码器,持续500k次迭代。
新闻
要求
本仓库在Ubuntu 20.04上使用V100进行测试,并使用以下设置。
- Python 3.8+
- Cuda 11.0+
- PyTorch 1.10+
文件夹结构
- bin: 训练、统计提取、测试和流式处理模板的文件夹。
- config: 配置文件(.yaml)的文件夹。
- dataloader: 数据加载的源代码。
- exp: 保存模型的文件夹。
- layers: 基本神经网络层的源代码。
- losses: 损失函数的源代码。
- models: 模型的源代码。
- slurmlogs: 保存slurm日志的文件夹。
- stats: 保存统计数据的文件夹。
- trainer: 训练器的源代码。
- utils: 演示用的工具源代码。
运行实时流式编码/解码演示
- 请下载完整的exp文件夹,并将其放置在AudioDec项目目录中。
- 获取所有I/O设备列表
$ python -m sounddevice
- 运行演示
# 推荐使用LibriTTS模型,因为它对任意麦克风的通道不匹配具有鲁棒性。
# 根据I/O设备列表设置输入输出设备
# 使用GPU
$ python demoStream.py --tx_cuda 0 --rx_cuda 0 --input_device 1 --output_device 4 --model libritts_v1
# 使用CPU
$ python demoStream.py --tx_cuda -1 --rx_cuda -1 --input_device 1 --output_device 4 --model libritts_sym
# 输入和输出音频将被保存为input.wav和output.wav
运行文件编解码演示
- 请下载完整的exp文件夹,并将其放置在AudioDec项目目录中。
- 运行演示
## VCTK 48000Hz模型
$ python demoFile.py --model vctk_v1 -i xxx.wav -o ooo.wav
## LibriTTS 24000Hz模型
$ python demoFile.py --model libritts_v1 -i xxx.wav -o ooo.wav
训练和测试完整的AudioDec流程
- 准备训练/验证/测试语音,并将它们放在三个不同的文件夹中
例如:corpus/train、corpus/dev和corpus/test - 修改以下文件中的路径(例如:/mnt/home/xxx/datasets)
submit_codec_vctk.sh
config/autoencoder/symAD_vctk_48000_hop300.yaml
config/statistic/symAD_vctk_48000_hop300_clean.yaml
config/vocoder/AudioDec_v1_symAD_vctk_48000_hop300_clean.yaml - 在以下文件中分配相应的
analyzer和stats
config/statistic/symAD_vctk_48000_hop300_clean.yaml
config/vocoder/AudioDec_v1_symAD_vctk_48000_hop300_clean.yaml - 按照submit_codec_vctk.sh中的使用说明运行训练和测试
# 阶段0:从头开始训练自动编码器
# 阶段1:提取统计数据
# 阶段2:从头开始训练声码器
# 阶段3:测试(symAE)
# 阶段4:测试(AE + 声码器)
# 运行阶段0-4
$ bash submit_codec.sh --start 0 --stop 4 \
--autoencoder "autoencoder/symAD_vctk_48000_hop300" \
--statistic "stati/symAD_vctk_48000_hop300_clean" \
--vocoder "vocoder/AudioDec_v1_symAD_vctk_48000_hop300_clean"
仅训练和测试自动编码器
- 准备训练/验证/测试语音并修改路径
- 按照submit_autoencoder.sh中的使用说明运行训练和测试
# 从头开始训练自动编码器
$ bash submit_autoencoder.sh --stage 0 \
--tag_name "autoencoder/symAD_vctk_48000_hop300"
# 从之前的迭代恢复自动编码器训练
$ bash submit_autoencoder.sh --stage 1 \
--tag_name "autoencoder/symAD_vctk_48000_hop300" \
--resumepoint 200000
# 测试自动编码器
$ bash submit_autoencoder.sh --stage 2 \
--tag_name "autoencoder/symAD_vctk_48000_hop300"
--subset "clean_test"
预训练模型
所有预训练模型可通过exp获取(仅提供生成器)。
| 自动编码器 | 语料库 | 采样率 | 比特率 | 路径 |
|---|---|---|---|---|
| symAD | VCTK | 48 kHz | 24 kbps | exp/autoencoder/symAD_c16_vctk_48000_hop320 |
| symAAD | VCTK | 48 kHz | 12.8 kbps | exp/autoencoder/symAAD_vctk_48000_hop300 |
| symAD | VCTK | 48 kHz | 12.8 kbps | exp/autoencoder/symAD_vctk_48000_hop300 |
| symAD_univ | VCTK | 48 kHz | 12.8 kbps | exp/autoencoder/symADuniv_vctk_48000_hop300 |
| symAD | LibriTTS | 24 kHz | 6.4 kbps | exp/autoencoder/symAD_libritts_24000_hop300 |
| 声码器 | 语料库 | 采样率 | 路径 | |
| --- | --- | --- | --- | |
| AD v0 | VCTK | 48 kHz | exp/vocoder/AudioDec_v0_symAD_vctk_48000_hop300_clean | |
| AD v1 | VCTK | 48 kHz | exp/vocoder/AudioDec_v1_symAD_vctk_48000_hop300_clean | |
| AD v2 | VCTK | 48 kHz | exp/vocoder/AudioDec_v2_symAD_vctk_48000_hop300_clean | |
| AD_univ | VCTK | 48 kHz | exp/vocoder/AudioDec_v3_symADuniv_vctk_48000_hop300_clean | |
| AD v1 | LibriTTS | 24 kHz | exp/vocoder/AudioDec_v1_symAD_libritts_24000_hop300_clean |
额外功能:去噪
- 只需使用噪声-干净音频对更新编码器(保持解码器/声码器不变),就可以轻松实现去噪。
- 准备噪声-干净音频语料库,并按照submit_denoise.sh中的使用说明运行训练和测试
# 更新编码器以进行去噪
$ bash submit_autoencoder.sh --stage 0 \
--tag_name "denoise/symAD_vctk_48000_hop300"
# 去噪
$ bash submit_autoencoder.sh --stage 2 \
--encoder "denoise/symAD_vctk_48000_hop300"
--decoder "vocoder/AudioDec_v1_symAD_vctk_48000_hop300_clean"
--encoder_checkpoint 200000
--decoder_checkpoint 500000
--subset "noisy_test"
# 使用GPU进行流式演示
$ python demoStream.py --tx_cuda 0 --rx_cuda 0 --input_device 1 --output_device 4 --model vctk_denoise
# 使用文件进行编解码演示
$ python demoFile.py -i xxx.wav -o ooo.wav --model vctk_denoise
引用
如果您发现代码有帮助,请引用以下文章。
@INPROCEEDINGS{10096509,
author={Wu, Yi-Chiao and Gebru, Israel D. and Marković, Dejan and Richard, Alexander},
booktitle={ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={{A}udio{D}ec: An Open-Source Streaming High-Fidelity Neural Audio Codec},
year={2023},
doi={10.1109/ICASSP49357.2023.10096509}}
参考文献
AudioDec 仓库基于以下仓库开发。
- kan-bayashi/ParallelWaveGAN
- r9y9/wavenet_vocoder
- jik876/hifi-gan
- lucidrains/vector-quantize-pytorch
- chomeyama/SiFiGAN
许可证
"AudioDec: An Open-source Streaming High-fidelity Neural Audio Codec"的大部分内容均采用CC-BY-NC许可,但项目的某些部分使用单独的许可条款:https://github.com/kan-bayashi/ParallelWaveGAN、https://github.com/lucidrains/vector-quantize-pytorch、https://github.com/jik876/hifi-gan、https://github.com/r9y9/wavenet_vocoder 和 https://github.com/chomeyama/SiFiGAN 均采用MIT许可证。
常见问题解答
- 你们是否比较过AudioDec和Encodec?
请参阅讨论。 - 你们是否比较过AudioDec和其他非神经网络编解码器,如Opus?
由于本文主要关注提供一个具有高效训练范式和模块化架构的完善的可流式神经编解码器实现,我们只将AudioDec与SoundStream进行了比较。 - 你们能否也发布预训练的判别器?
对于许多应用(如去噪),仅更新编码器就能达到与更新整个模型几乎相同的性能。对于涉及解码器更新的应用(如双耳渲染),为该应用设计特定的判别器可能会更好。因此,我们只发布生成器。 - AudioDec能否编码/解码多通道信号?
可以,您可以通过更改配置中的input_channels和output_channels来训练MIMO模型。我在训练MIMO模型时学到的一个经验是,虽然生成器是MIMO的,但将生成器输出信号重塑为单声道后再传递给判别器会显著提高MIMO音频质量。











