
 访问官网
访问官网 Github
Github 文档
文档Android 语音活动检测 (VAD)
Android VAD 库旨在实时处理音频,并在包含语音和噪音混合的音频样本中识别人类语音的存在。VAD 功能离线运行,直接在移动设备上执行所有处理任务。
该仓库提供三种不同的语音活动检测模型:
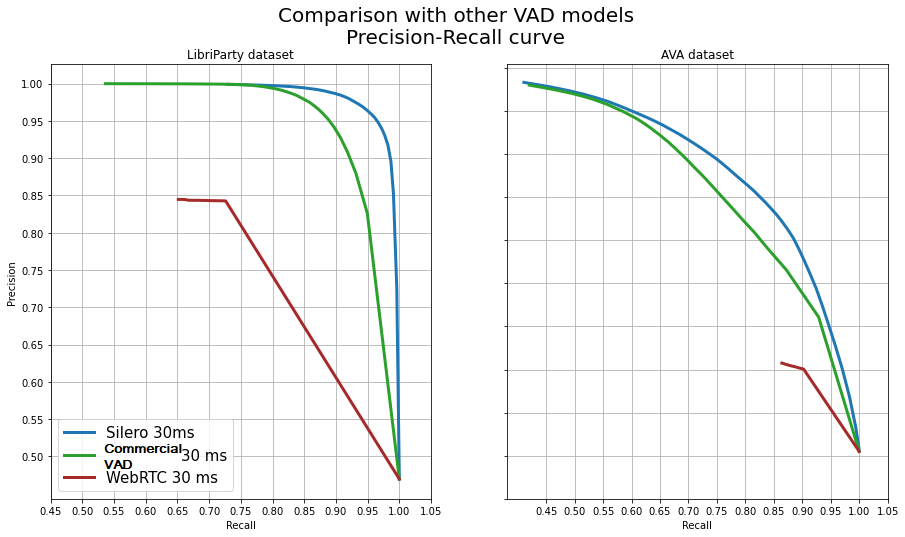
WebRTC VAD [1] 基于高斯混合模型 (GMM),以其在区分噪音和静音方面的卓越速度和效果而闻名。然而,在区分语音和背景噪音时,它的准确性可能相对较低。
Silero VAD [2] 基于深度神经网络 (DNN),并使用 ONNX Runtime Mobile 执行。它提供了出色的准确性,处理时间非常接近 WebRTC VAD。
Yamnet VAD [3] 基于深度神经网络 (DNN),采用 Mobilenet_v1 深度可分离卷积架构。执行时使用 Tensorflow Lite 运行时。Yamnet VAD 可以预测 521 种音频事件类别(如语音、音乐、动物声音等)。它在 AudioSet-YouTube 语料库上进行训练。
WebRTC VAD 轻量级(仅 158 KB)并提供卓越的音频处理速度,但与 DNN 模型相比,其准确性可能较低。在需要小型快速库且可以牺牲准确性的情况下,WebRTC VAD 可能非常有价值。在高准确性至关重要的情况下,Silero VAD 和 Yamnet VAD 等模型更为可取。有关 DNN 和 GMM 之间更详细的见解和全面比较,请参阅以下比较 Silero VAD vs WebRTC VAD。
WebRTC VAD
参数
WebRTC VAD 库仅接受 16 位单声道 PCM 音频流,可以使用以下采样率、帧大小和模式。
|
|
WebRTC VAD 推荐参数:
- 采样率(必需) - 16KHz - 音频输入的采样率。
- 帧大小(必需) - 320 - 音频输入的帧大小。
- 模式(必需) - 非常激进 - VAD 模型的置信度模式。
- 静音持续时间(可选) - 300ms - 静音段的最小持续时间(毫秒)。
- 语音持续时间(可选) - 50ms - 语音段的最小持续时间(毫秒)。
使用方法
WebRTC VAD 可以识别短音频帧中的语音,并为每个帧返回结果。通过利用 silenceDurationMs 和 speechDurationMs 等参数,您可以增强 VAD 的功能,使其能够检测较长的语音同时最小化句子之间停顿时的误报结果。
Java 示例:
VadWebRTC vad = Vad.builder()
.setSampleRate(SampleRate.SAMPLE_RATE_16K)
.setFrameSize(FrameSize.FRAME_SIZE_320)
.setMode(Mode.VERY_AGGRESSIVE)
.setSilenceDurationMs(300)
.setSpeechDurationMs(50)
.build();
boolean isSpeech = vad.isSpeech(audioData);
vad.close();
Kotlin示例:
```kotlin
VadWebRTC(
sampleRate = SampleRate.SAMPLE_RATE_16K,
frameSize = FrameSize.FRAME_SIZE_320,
mode = Mode.VERY_AGGRESSIVE,
silenceDurationMs = 300,
speechDurationMs = 50
).use { vad ->
val isSpeech = vad.isSpeech(audioData)
}
检测音频文件中的语音的示例:
VadWebRTC(
sampleRate = SampleRate.SAMPLE_RATE_16K,
frameSize = FrameSize.FRAME_SIZE_320,
mode = Mode.VERY_AGGRESSIVE,
silenceDurationMs = 600,
speechDurationMs = 50
).use { vad ->
val chunkSize = vad.frameSize.value * 2
requireContext().assets.open("hello.wav").buffered().use { input ->
val audioHeader = ByteArray(44).apply { input.read(this) }
var speechData = byteArrayOf()
while (input.available() > 0) {
val frameChunk = ByteArray(chunkSize).apply { input.read(this) }
if (vad.isSpeech(frameChunk)) {
speechData += frameChunk
} else {
if (speechData.isNotEmpty()) {
val speechFile = File("/folder/", "${nanoTime()}.wav")
FileOutputStream(speechFile).use { output ->
output.write(audioHeader)
output.write(speechData)
}
speechData = byteArrayOf()
}
}
}
}
}
Silero VAD
参数
Silero VAD库仅接受16位单声道PCM音频流,可以使用以下采样率、帧大小和模式。
|
|
Silero VAD的推荐参数:
- Context (必需) - 需要Context来从Android文件系统读取模型文件。
- Sample Rate (必需) - 16KHz - 音频输入的采样率。
- Frame Size (必需) - 512 - 音频输入的帧大小。
- Mode (必需) - NORMAL - VAD模型的置信度模式。
- Silence Duration (可选) - 300ms - 静音片段的最小持续时间(毫秒)。
- Speech Duration (可选) - 50ms - 语音片段的最小持续时间(毫秒)。
用法
Silero VAD可以识别短音频帧中的语音,为每个帧返回结果。 通过使用silenceDurationMs和speechDurationMs等参数,您可以增强 VAD的能力,能够检测较长的语音,同时最小化句子之间暂停时的误报 结果。
Java示例:
VadSilero vad = Vad.builder()
.setContext(requireContext())
.setSampleRate(SampleRate.SAMPLE_RATE_16K)
.setFrameSize(FrameSize.FRAME_SIZE_512)
.setMode(Mode.NORMAL)
.setSilenceDurationMs(300)
.setSpeechDurationMs(50)
.build();
boolean isSpeech = vad.isSpeech(audioData);
vad.close();
Kotlin示例:
VadSilero(
requireContext(),
sampleRate = SampleRate.SAMPLE_RATE_16K,
frameSize = FrameSize.FRAME_SIZE_512,
mode = Mode.NORMAL,
silenceDurationMs = 300,
speechDurationMs = 50
).use { vad ->
val isSpeech = vad.isSpeech(audioData)
}
Yamnet VAD
参数
Yamnet VAD库仅接受16位单声道PCM音频流,可以使用以下采样率、帧大小和模式。
|
|
使用方法
Yamnet VAD 可以识别小音频帧中的 521 种音频事件类别(如语音、音乐、动物声音等)。 通过使用 silenceDurationMs 和 speechDurationMs 等参数,并指定 声音类别(例如 classifyAudio("Speech", audioData)),你可以增强 VAD 的能力, 使其能够检测到较长的语音,同时最大限度地减少句子之间停顿时的误报。
Java 示例:
VadYamnet vad = Vad.builder()
.setContext(requireContext())
.setSampleRate(SampleRate.SAMPLE_RATE_16K)
.setFrameSize(FrameSize.FRAME_SIZE_243)
.setMode(Mode.NORMAL)
.setSilenceDurationMs(30)
.setSpeechDurationMs(30)
.build();
SoundCategory sc = vad.classifyAudio("Speech", audioData);
if ("Speech".equals(sc.getLabel())) {
System.out.println("检测到语音: " + sc.getScore());
} else {
System.out.println("检测到噪音: " + sc.getScore());
}
vad.close();
Kotlin 示例:
VadYamnet(
requireContext(),
sampleRate = SampleRate.SAMPLE_RATE_16K,
frameSize = FrameSize.FRAME_SIZE_243,
mode = Mode.NORMAL,
silenceDurationMs = 30,
speechDurationMs = 30
).use { vad ->
val sc = vad.classifyAudio("Cat", audioData)
when (sc.label) {
"Cat" -> println("检测到猫叫: " + sc.score)
else -> println("检测到噪音: " + sc.score)
}
}
系统要求
Android API
WebRTC VAD - Android API 16 及以上。
Silero VAD - Android API 21 及以上。
Yamnet VAD - Android API 23 及以上。
JDK
JDK 8 或更高版本。
下载

Gradle 是唯一支持的构建配置,所以只需将依赖项添加到项目的 build.gradle 文件中:
- 在根 build.gradle 文件的 repositories 末尾添加:
allprojects {
repositories {
maven { url 'https://jitpack.io' }
}
}
- 从以下列表中添加一个依赖项:
WebRTC VAD
dependencies {
implementation 'com.github.gkonovalov.android-vad:webrtc:2.0.6'
}
Silero VAD
dependencies {
implementation 'com.github.gkonovalov.android-vad:silero:2.0.6'
}
Yamnet VAD
dependencies {
implementation 'com.github.gkonovalov.android-vad:yamnet:2.0.6'
}
你也可以从 GitHub 的发布页面下载预编译的 AAR 库和 APK 文件。
参考文献
[1] WebRTC VAD - 来自 Google 的语音活动检测器,据报道是目前最好的检测器之一:它快速、 现代且免费。这种算法已被广泛采用,最近成为对延迟敏感场景(如基于网络的交互)的 黄金标准之一。
[2] Silero VAD - 预训练的企业级语音活动检测器、 数字检测器和语言分类器 hello@silero.ai。 [3] Yamnet VAD - YAMNet是一个预训练的深度神经网络,可以基于AudioSet-YouTube语料库预测521个音频事件类别,采用Mobilenet_v1深度可分离卷积架构。
Georgiy Konovalov 2024 (c) MIT许可证











