
 访问官网
访问官网 Github
Github 论文
论文3D高斯散射实时辐射场渲染
Bernhard Kerbl*, Georgios Kopanas*, Thomas Leimkühler, George Drettakis (*表示贡献相同)
| 网页 | 完整论文 | 视频 | 其他GRAPHDECO出版物 | FUNGRAPH项目页面 |
| T&T+DB COLMAP (650MB) | 预训练模型 (14 GB) | Windows查看器 (60MB) | 评估图像 (7 GB) |
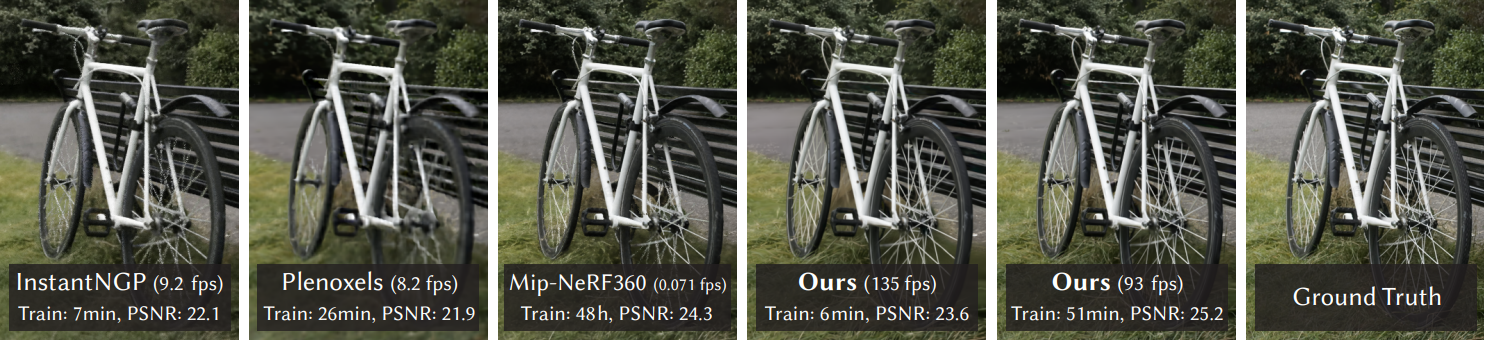
本仓库包含与论文"3D高斯散射实时辐射场渲染"相关的官方作者实现,论文可在此处找到。我们还提供了用于创建论文中报告的误差指标的参考图像,以及最近创建的预训练模型。




摘要:辐射场方法最近彻底改变了使用多张照片或视频捕捉场景的新视角合成。然而,要实现高视觉质量仍需要昂贵的训练和渲染神经网络,而最近的更快方法则不可避免地以质量换取速度。对于无界和完整的场景(而非孤立物体)以及1080p分辨率渲染,目前没有方法能够实现实时显示速率。我们引入三个关键元素,使我们能够实现最先进的视觉质量,同时保持具有竞争力的训练时间,最重要的是允许以1080p分辨率进行高质量实时(≥30 fps)新视角合成。首先,从相机校准过程中产生的稀疏点开始,我们用3D高斯表示场景,保留了连续体积辐射场对场景优化的理想属性,同时避免了空白空间中不必要的计算;其次,我们对3D高斯进行交错优化/密度控制,特别是优化各向异性协方差以实现场景的准确表示;第三,我们开发了一种快速的可见性感知渲染算法,支持各向异性散射,既加速训练又允许实时渲染。我们在几个已建立的数据集上展示了最先进的视觉质量和实时渲染。
BibTeX
@Article{kerbl3Dgaussians,
author = {Kerbl, Bernhard and Kopanas, Georgios and Leimk{\"u}hler, Thomas and Drettakis, George},
title = {3D Gaussian Splatting for Real-Time Radiance Field Rendering},
journal = {ACM Transactions on Graphics},
number = {4},
volume = {42},
month = {July},
year = {2023},
url = {https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/}
}资金和致谢
本研究由ERC高级资助FUNGRAPH No 788065资助。作者感谢Adobe的慷慨捐赠,法国蔚蓝海岸大学的OPAL基础设施以及GENCI–IDRIS提供的HPC资源(Grant 2022-AD011013409)。作者感谢匿名审稿人的宝贵反馈,P. Hedman和A. Tewari校对早期草稿,以及T. Müller、A. Yu和S. Fridovich-Keil在比较方面的帮助。
分步教程
Jonathan Stephens制作了一个出色的分步教程,介绍如何在您的机器上设置高斯散射,以及如何从视频创建可用的数据集。如果下面的说明对您来说太枯燥,请查看这里。
Colab
用户camenduru很友好地提供了一个使用本仓库源代码(截至2023年8月!)的Colab模板,以便快速轻松地访问该方法。请在这里查看。
克隆仓库
该仓库包含子模块,因此请使用以下命令检出:
# SSH
git clone git@github.com:graphdeco-inria/gaussian-splatting.git --recursive
或
# HTTPS
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive
概述
代码库有4个主要组成部分:
- 基于PyTorch的优化器,从SfM输入生成3D高斯模型
- 网络查看器,允许连接并可视化优化过程
- 基于OpenGL的实时查看器,用于实时渲染训练好的模型
- 一个脚本,帮助您将自己的图像转换为可优化的SfM数据集
这些组件在硬件和软件方面有不同的要求。它们已在Windows 10和Ubuntu Linux 22.04上进行了测试。下面各节中提供了设置和运行每个组件的说明。
新功能 [请定期查看!]
我们将很快添加几个新功能。与此同时,Orange已经友好地添加了OpenXR支持用于VR查看。请稍后再来,我们将添加其他功能,其中包括基于最近3DGS后续论文的功能。
优化器
优化器在Python环境中使用PyTorch和CUDA扩展来生成训练好的模型。
硬件要求
- 支持CUDA的GPU,计算能力7.0+
- 24 GB显存(用于训练达到论文评估质量)
- 请参阅常见问题解答了解较小显存配置
软件要求
- Conda(推荐用于简便设置)
- 用于PyTorch扩展的C++编译器(我们在Windows上使用Visual Studio 2019)
- 用于PyTorch扩展的CUDA SDK 11,在Visual Studio之后安装(我们使用11.8,已知11.6存在问题)
- C++编译器和CUDA SDK必须兼容
设置
本地设置
我们默认提供的安装方法基于Conda包和环境管理:
SET DISTUTILS_USE_SDK=1 # 仅限Windows
conda env create --file environment.yml
conda activate gaussian_splatting
请注意,此过程假设您已安装CUDA SDK 11,而非12。如需修改,请参见下文。
提示:使用Conda下载包和创建新环境可能需要大量磁盘空间。默认情况下,Conda将使用主系统硬盘。您可以通过指定不同的包下载位置和其他驱动器上的环境来避免这种情况:
conda config --add pkgs_dirs <驱动器>/<包路径>
conda env create --file environment.yml --prefix <驱动器>/<环境路径>/gaussian_splatting
conda activate <驱动器>/<环境路径>/gaussian_splatting
修改
如果您有足够的磁盘空间,我们建议使用我们的环境文件来设置与我们相同的训练环境。如果您想进行修改,请注意主要版本的更改可能会影响我们方法的结果。然而,我们(有限的)实验表明,该代码库在更新的环境中(Python 3.8、PyTorch 2.0.0、CUDA 12)运行良好。请确保创建一个PyTorch及其CUDA运行时版本匹配的环境,并且安装的CUDA SDK与PyTorch的CUDA版本没有重大版本差异。
已知问题
一些用户在Windows上构建子模块时遇到问题(cl.exe: 未找到文件或类似问题)。请考虑使用常见问题解答中的解决方法。
运行
要运行优化器,只需使用
python train.py -s <COLMAP或NeRF合成数据集的路径>
train.py的命令行参数
--source_path / -s
包含COLMAP或合成NeRF数据集的源目录路径。
--model_path / -m
训练模型应存储的路径(默认为output/<随机>)。
--images / -i
COLMAP图像的替代子目录(默认为images)。
--eval
添加此标志以使用MipNeRF360风格的训练/测试分割进行评估。
--resolution / -r
指定训练前加载图像的分辨率。如果提供1, 2, 4或8,分别使用原始、1/2、1/4或1/8分辨率。对于所有其他值,将宽度缩放到给定数字,同时保持图像纵横比。如果未设置且输入图像宽度超过1.6K像素,输入将自动缩放到此目标。
--data_device
指定放置源图像数据的位置,默认为cuda,如果在大型/高分辨率数据集上训练,建议使用cpu,将减少显存消耗,但略微减慢训练速度。感谢HrsPythonix。
--white_background / -w
添加此标志以使用白色背景而不是黑色(默认),例如,用于评估NeRF合成数据集。
--sh_degree
要使用的球谐函数阶数(不大于3)。默认为3。
--convert_SHs_python
标志,使管道使用PyTorch而不是我们的方法计算SHs的前向和后向。
--convert_cov3D_python
标志,使管道使用PyTorch而不是我们的方法计算3D协方差的前向和后向。
--debug
如果遇到错误,启用调试模式。如果光栅化器失败,将创建一个dump文件,您可以在问题中转发给我们,以便我们查看。
--debug_from
调试很慢。您可以指定一个迭代(从0开始)后,上述调试变为活动状态。
--iterations
要训练的总迭代次数,默认为30_000。
--ip
启动GUI服务器的IP,默认为127.0.0.1。
--port
用于GUI服务器的端口,默认为6009。
--test_iterations
训练脚本计算测试集上L1和PSNR的空格分隔迭代,默认为7000 30000。
--save_iterations
训练脚本保存高斯模型的空格分隔迭代,默认为7000 30000 <iterations>。
--checkpoint_iterations
存储检查点以便稍后继续的空格分隔迭代,保存在模型目录中。
--start_checkpoint
继续训练的已保存检查点路径。
--quiet
标志,省略写入标准输出管道的任何文本。
--feature_lr
球谐函数特征学习率,默认为0.0025。
--opacity_lr
不透明度学习率,默认为0.05。
--scaling_lr
缩放学习率,默认为0.005。
--rotation_lr
旋转学习率,默认为0.001。
--position_lr_max_steps
位置学习率从初始到最终的步数(从0开始)。默认为30_000。
--position_lr_init
初始3D位置学习率,默认为0.00016。
--position_lr_final
最终3D位置学习率,默认为0.0000016。
--position_lr_delay_mult
位置学习率乘数(参见Plenoxels),默认为0.01。
--densify_from_iter
开始密集化的迭代,默认为500。
--densify_until_iter
停止密集化的迭代,默认为15_000。
--densify_grad_threshold
基于2D位置梯度决定是否应密集化点的限制,默认为0.0002。
--densification_interval
密集化频率,默认为100(每100次迭代)。
--opacity_reset_interval
重置不透明度的频率,默认为3_000。
--lambda_dssim
SSIM对总损失的影响,从0到1,默认为0.2。
--percent_dense
点必须超过的场景范围百分比(0-1)才能被强制密集化,默认为0.01。
请注意,与MipNeRF360类似,我们针对1-1.6K像素范围内的图像分辨率。为方便起见,可以传入任意大小的输入,如果宽度超过1600像素,将自动调整大小。我们建议保持此行为,但您可以通过设置-r 1来强制训练使用您的高分辨率图像。
MipNeRF360场景由论文作者在此处托管。您可以在这里找到我们用于Tanks&Temples和Deep Blending的SfM数据集。如果您没有提供输出模型目录(-m),训练好的模型将被写入output目录下随机命名的唯一文件夹中。此时,可以使用实时查看器查看训练好的模型(详见下文)。
评估
默认情况下,训练模型使用数据集中的所有可用图像。要在保留测试集进行评估的同时进行训练,请使用--eval标志。这样,您可以渲染训练/测试集并生成误差指标,如下所示:
python train.py -s <COLMAP或NeRF Synthetic数据集路径> --eval # 使用训练/测试集分割进行训练
python render.py -m <训练好的模型路径> # 生成渲染图
python metrics.py -m <训练好的模型路径> # 计算渲染图的误差指标
如果您想评估我们的预训练模型,您需要下载相应的源数据集,并使用额外的--source_path/-s标志向render.py指明它们的位置。注意:预训练模型是使用发布的代码库创建的。此代码库已经过清理并包含了错误修复,因此您评估它们得到的指标将与论文中的不同。
python render.py -m <预训练模型路径> -s <COLMAP数据集路径>
python metrics.py -m <预训练模型路径>
render.py的命令行参数
--model_path / -m
要为其创建渲染的已训练模型目录的路径。
--skip_train
跳过渲染训练集的标志。
--skip_test
跳过渲染测试集的标志。
--quiet
省略写入标准输出管道的任何文本的标志。
以下参数将根据训练时使用的内容自动从模型路径中读取。但是,您可以通过在命令行上显式提供它们来覆盖它们。
--source_path / -s
包含COLMAP或Synthetic NeRF数据集的源目录路径。
--images / -i
COLMAP图像的替代子目录(默认为images)。
--eval
添加此标志以使用MipNeRF360风格的训练/测试集分割进行评估。
--resolution / -r
在训练前更改加载图像的分辨率。如果提供1、2、4或8,分别使用原始、1/2、1/4或1/8分辨率。对于所有其他值,将宽度重新缩放为给定的数字,同时保持图像纵横比。默认为1。
--white_background / -w
添加此标志以使用白色背景而不是黑色(默认),例如,用于评估NeRF Synthetic数据集。
--convert_SHs_python
使管道使用从PyTorch计算的SHs而不是我们的SHs进行渲染的标志。
--convert_cov3D_python
使管道使用从PyTorch计算的3D协方差而不是我们的3D协方差进行渲染的标志。
metrics.py的命令行参数
--model_paths / -m
应计算指标的模型路径的空格分隔列表。
我们还提供了full_eval.py脚本。该脚本指定了我们评估中使用的例程,并演示了一些额外参数的使用,例如,--images (-i)用于定义COLMAP数据集中的替代图像目录。如果您已下载并解压所有训练数据,可以像这样运行它:
python full_eval.py -m360 <mipnerf360文件夹> -tat <tanks and temples文件夹> -db <deep blending文件夹>
在当前版本中,这个过程在我们的参考机器(包含一个A6000)上大约需要7小时。如果您想对我们的预训练模型进行完整评估,可以指定它们的下载位置并跳过训练。
python full_eval.py -o <预训练模型目录> --skip_training -m360 <mipnerf360文件夹> -tat <tanks and temples文件夹> -db <deep blending文件夹>
如果您想在我们论文的评估图像上计算指标,也可以跳过渲染。在这种情况下,无需提供源数据集。您可以一次计算多个图像集的指标。
python full_eval.py -m <评估图像目录>/garden ... --skip_training --skip_rendering
full_eval.py的命令行参数
--skip_training
跳过训练阶段的标志。
--skip_rendering
跳过渲染阶段的标志。
--skip_metrics
跳过指标计算阶段的标志。
--output_path
放置渲染图和结果的目录,默认为./eval,如果评估预训练模型则设置为预训练模型位置。
--mipnerf360 / -m360
MipNeRF360源数据集的路径,如果训练或渲染则需要。
--tanksandtemples / -tat
Tanks&Temples源数据集的路径,如果训练或渲染则需要。
--deepblending / -db
Deep Blending源数据集的路径,如果训练或渲染则需要。
交互式查看器
我们为我们的方法提供了两个交互式查看器:远程和实时。我们的查看解决方案基于SIBR框架,该框架由GRAPHDECO小组为多个新视角合成项目开发。
硬件要求
- 支持OpenGL 4.5的GPU和驱动程序(或最新的MESA软件)
- 建议4 GB显存
- 支持CUDA的GPU,计算能力7.0+(仅用于实时查看器)
软件要求
- Visual Studio或g++,不是Clang(我们在Windows上使用Visual Studio 2019)
- CUDA SDK 11,在Visual Studio之后安装(我们使用11.8)
- CMake(最新版本,我们使用3.24)
- 7zip(仅在Windows上)
预构建的Windows二进制文件
我们在这里提供了Windows预构建二进制文件。我们建议在Windows上使用它们以实现高效设置,因为SIBR的构建涉及几个必须即时下载和编译的外部依赖项。
从源代码安装
如果您使用子模块克隆(例如,使用--recursive),查看器的源代码位于SIBR_viewers中。网络查看器在SIBR框架内运行,用于基于图像的渲染应用程序。
Windows
CMake应该能够处理您的依赖项。
cd SIBR_viewers
cmake -Bbuild .
cmake --build build --target install --config RelWithDebInfo
您可以指定不同的配置,例如Debug,如果您在开发过程中需要更多控制。
Ubuntu 22.04
在运行项目设置之前,你需要安装一些依赖项。
# 依赖项
sudo apt install -y libglew-dev libassimp-dev libboost-all-dev libgtk-3-dev libopencv-dev libglfw3-dev libavdevice-dev libavcodec-dev libeigen3-dev libxxf86vm-dev libembree-dev
# 项目设置
cd SIBR_viewers
cmake -Bbuild . -DCMAKE_BUILD_TYPE=Release # 添加 -G Ninja 以加快构建速度
cmake --build build -j24 --target install
Ubuntu 20.04
虽然与Focal Fossa的向后兼容性尚未完全测试,但在执行以下命令后,仍应能够使用CMake构建SIBR:
git checkout fossa_compatibility
SIBR查看器中的导航
SIBR界面提供了多种场景导航方法。默认情况下,你将以FPS导航器开始,可以使用W, A, S, D, Q, E控制相机平移,使用I, K, J, L, U, O控制旋转。或者,你可能想使用轨迹球式导航器(从浮动菜单中选择)。你还可以使用Snap to按钮捕捉到数据集中的相机,或使用Snap to closest找到最近的相机。浮动菜单还允许你更改导航速度。你可以使用Scaling Modifier控制显示的高斯体大小,或显示初始点云。
运行网络查看器
提取或安装查看器后,你可以运行<SIBR安装目录>/bin中编译的SIBR_remoteGaussian_app[_config]应用程序,例如:
./<SIBR安装目录>/bin/SIBR_remoteGaussian_app
网络查看器允许你连接到同一台或不同机器上运行的训练进程。如果你在同一台机器和操作系统上进行训练,则不需要任何命令行参数:优化器会将训练数据的位置传递给网络查看器。默认情况下,优化器和网络查看器将尝试在localhost的6009端口上建立连接。你可以通过为优化器和网络查看器提供匹配的--ip和--port参数来更改此行为。如果由于某种原因,优化器用于查找训练数据的路径无法被网络查看器访问(例如,由于它们在不同的(虚拟)机器上运行),你可以使用-s <源路径>为查看器指定覆盖位置。
网络查看器的主要命令行参数
--path / -s
覆盖模型的源数据集路径的参数。
--ip
用于连接正在运行的训练脚本的IP。
--port
用于连接正在运行的训练脚本的端口。
--rendering-size
接受两个空格分隔的数字,用于定义网络渲染的分辨率,默认宽度为1200。
注意,要强制使用与输入图像不同的宽高比,你还需要使用--force-aspect-ratio。
--load_images
加载源数据集图像以在每个相机的顶视图中显示的标志。
运行实时查看器
提取或安装查看器后,你可以运行<SIBR安装目录>/bin中编译的SIBR_gaussianViewer_app[_config]应用程序,例如:
./<SIBR安装目录>/bin/SIBR_gaussianViewer_app -m <训练模型的路径>
只需提供指向训练模型目录的-m参数即可。或者,你可以使用-s指定训练输入数据的覆盖位置。要使用特定的分辨率而不是自动选择的分辨率,请指定--rendering-size <宽度> <高度>。如果你希望使用精确的分辨率且不介意图像失真,请将其与--force-aspect-ratio结合使用。
要解锁全帧率,请在你的机器上和应用程序中禁用垂直同步(菜单 → 显示)。在多GPU系统(例如笔记本电脑)中,你的OpenGL/显示GPU应与CUDA GPU相同(例如,在Windows上设置应用程序的GPU首选项),以获得最佳性能。
除了初始点云和splats外,你还可以选择通过将高斯体渲染为椭球体来从浮动菜单中可视化它们。 SIBR还有许多其他功能,请参阅文档以了解有关查看器、导航选项等的更多详细信息。还有一个顶视图(可从菜单中获得),显示输入相机的位置和原始SfM点云;请注意,启用顶视图时会减慢渲染速度。实时查看器还使用稍微更激进的快速剔除,可以在浮动菜单中切换。如果你遇到任何可以通过关闭快速剔除来解决的问题,请告诉我们。
实时查看器的主要命令行参数
--model-path / -m
训练模型的路径。
--iteration
如果有多个可用状态,指定要加载的状态。默认为最新可用迭代。
--path / -s
覆盖模型的源数据集路径的参数。
--rendering-size
接受两个空格分隔的数字,用于定义实时渲染的分辨率,默认宽度为1200。注意,要强制使用与输入图像不同的宽高比,你还需要使用--force-aspect-ratio。
--load_images
加载源数据集图像以在每个相机的顶视图中显示的标志。
--device
如果有多个可用的CUDA设备,用于光栅化的设备索引,默认为0。
--no_interop
强制禁用CUDA/GL互操作。在可能不按规范行为的系统上使用(例如,使用MESA GL 4.5软件渲染的WSL2)。
处理你自己的场景
我们的COLMAP加载器期望在源路径位置有以下数据集结构:
<位置>
|---images
| |---<图像 0>
| |---<图像 1>
| |---...
|---sparse
|---0
|---cameras.bin
|---images.bin
|---points3D.bin
对于光栅化,相机模型必须是 SIMPLE_PINHOLE 或 PINHOLE 相机。我们提供了一个转换脚本 convert.py,用于从输入图像中提取无失真图像和 SfM 信息。您也可以选择使用 ImageMagick 来调整无失真图像的大小。这种缩放类似于 MipNeRF360,即在相应文件夹中创建原始分辨率的 1/2、1/4 和 1/8 的图像。要使用它们,请首先安装最新版本的 COLMAP(最好是支持 CUDA 的版本)和 ImageMagick。将您想要使用的图像放在 <location>/input 目录中。
<location>
|---input
|---<图像 0>
|---<图像 1>
|---...
如果您的系统路径中已经包含 COLMAP 和 ImageMagick,您可以直接运行:
python convert.py -s <location> [--resize] #如果不调整大小,则不需要 ImageMagick
或者,您可以使用可选参数 --colmap_executable 和 --magick_executable 来指定相应的路径。请注意,在 Windows 上,可执行文件应指向 COLMAP 的 .bat 文件,该文件负责设置执行环境。完成后,<location> 将包含预期的 COLMAP 数据集结构,其中包括无失真、调整大小的输入图像,以及您的原始图像和 distorted 目录中的一些临时(有失真)数据。
如果您有自己的 COLMAP 数据集但没有进行失真校正(例如使用 OPENCV 相机),您可以尝试只运行脚本的最后一部分:将图像放在 input 中,将 COLMAP 信息放在 distorted 子目录中:
<location>
|---input
| |---<图像 0>
| |---<图像 1>
| |---...
|---distorted
|---database.db
|---sparse
|---0
|---...
然后运行:
python convert.py -s <location> --skip_matching [--resize] #如果不调整大小,则不需要 ImageMagick
convert.py 的命令行参数
--no_gpu
避免在 COLMAP 中使用 GPU 的标志。
--skip_matching
表示图像已有 COLMAP 信息的标志。
--source_path / -s
输入的位置。
--camera
用于早期匹配步骤的相机模型,默认为 OPENCV。
--resize
创建输入图像调整大小版本的标志。
--colmap_executable
COLMAP 可执行文件的路径(Windows 上为 .bat)。
--magick_executable
ImageMagick 可执行文件的路径。
OpenXR 支持
OpenXR 在 gaussian_code_release_openxr 分支中受支持。 在该分支中,您可以在此处找到 VR 支持的文档。
常见问题
-
在哪里可以获取数据集,例如
full_eval.py中引用的那些? MipNeRF360 数据集由原论文作者在项目网站上提供。请注意,其中两个数据集无法公开共享,需要直接咨询作者。对于 Tanks&Temples 和 Deep Blending,请使用页面顶部提供的下载链接。或者,您可以从 HuggingFace 访问克隆的数据(状态:2023 年 8 月!) -
如何将此方法用于更大的数据集,比如一个城市区域? 当前方法并非为此设计,但如果有足够的内存,它应该可以工作。然而,该方法在多尺度细节场景(极近特写镜头与远景镜头混合)中可能会遇到困难。这通常出现在驾驶数据集中(近处的汽车,远处的建筑)。对于这类场景,您可以降低
--position_lr_init、--position_lr_final和--scaling_lr(x0.3、x0.1 等)。场景越大,这些值应该越低。下面我们使用默认学习率(左)和--position_lr_init 0.000016 --scaling_lr 0.001(右)。
 |  |
|---|
-
我使用 Windows,无法成功构建子模块,该怎么办? 考虑参考这里优秀的视频教程中的步骤,希望能够帮到您。步骤的顺序很重要!或者,考虑使用链接的 Colab 模板。
-
仍然无法工作。它提示有关
cl.exe的问题。我该怎么办? 用户 Henry Pearce 找到了一个解决方法。您可以尝试将 Visual Studio 路径添加到环境变量中(您的版本号可能不同):C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64然后确保启动一个新的 conda 提示符,并 cd 到您的仓库位置,然后尝试以下操作:
conda activate gaussian_splatting
cd <dir_to_repo>/gaussian-splatting
pip install submodules\diff-gaussian-rasterization
pip install submodules\simple-knn
-
我使用 macOS/Puppy Linux/Greenhat,无法成功构建,该怎么办? 抱歉,我们无法为此 README 中列出的平台之外的平台提供支持。考虑使用链接的 Colab 模板。
-
我没有 24 GB 的显存用于训练,该怎么办? 显存消耗由正在优化的点数决定,这个数量会随时间增加。如果您只想训练到 7000 次迭代,所需显存会显著减少。要完成完整的训练流程并避免内存不足,您可以增加
--densify_grad_threshold、--densification_interval或降低--densify_until_iter的值。但请注意,这会影响结果质量。另外,尝试将--test_iterations设置为-1以避免测试期间的内存峰值。如果--densify_grad_threshold非常高,则不会发生密集化,如果场景本身成功加载,训练应该能够完成。 -
参考质量训练需要 24 GB 显存仍然很多!我们能用更少的显存吗? 是的,很可能可以。根据我们的计算,应该可以使用少得多的内存(约 8GB)。如果我们有时间,我们会尝试实现这一点。如果有 PyTorch 高手想要解决这个问题,我们期待您的拉取请求!
-
如何将可微分高斯光栅化器用于我自己的项目? 很简单,它作为子模块
diff-gaussian-rasterization包含在此仓库中。请随意查看并安装该包。虽然没有详细的文档,但从 Python 端使用它非常简单(参考gaussian_renderer/__init__.py)。 -
等等,但是"<插入功能>"还没有优化,可以做得更好吗? 有很多部分我们甚至还没有时间考虑改进(目前)。你用这个原型获得的性能可能只是在物理可能范围内相当慢的基准线。
-
有些东西坏了,这是怎么回事? 我们努力提供了一个可靠和易懂的基础来利用论文中的方法。我们对代码进行了相当多的重构,但我们测试所有可能使用场景的能力有限。因此,如果网站、代码或性能的某些部分有所欠缺,请创建一个问题报告。如果我们有时间,我们会尽最大努力解决它。











