
 Github
Github 文档
文档 论文
论文SCOPE-RL: 用于离线强化学习、离线策略评估和选择的Python库







目录 (点击展开)
文档可在此处获取
稳定版本可在PyPI获取
幻灯片可在此处获取
日本语版本请点击这里
概述
SCOPE-RL是一个开源Python软件,用于实现**离线强化学习(offline RL)**的端到端流程,包括数据收集、离线策略学习、离线策略性能评估和策略选择。我们的软件包含一系列模块,用于实现合成数据集生成、数据集预处理、离线策略评估(OPE)估计器和离线策略选择(OPS)方法。
该软件还与d3rlpy兼容,后者实现了一系列在线和离线RL方法。SCOPE-RL可以在任何具有OpenAI Gym和Gymnasium类接口的环境中进行简单、透明和可靠的离线RL研究实验。它还有助于在各种自定义数据集和真实世界数据集上实现离线RL。
特别是,SCOPE-RL能够促进和便利与以下研究主题相关的评估和算法比较:
-
离线强化学习:离线RL旨在仅使用由行为策略收集的离线日志数据来学习新策略。SCOPE-RL支持使用由各种行为策略和环境收集的自定义数据集进行灵活的实验。
-
离线策略评估:OPE旨在仅使用离线日志数据评估反事实策略的性能。SCOPE-RL支持许多OPE估计器,并简化了评估和比较OPE估计器的实验流程。此外,我们还实现了高级OPE方法,如基于状态-动作密度估计和累积分布估计的估计器。
-
离线策略选择:OPS旨在使用离线日志数据从多个候选策略池中识别表现最佳的策略。SCOPE-RL支持一些基本的OPS方法,并提供几个指标来评估OPS的准确性。
这个软件的灵感来自Open Bandit Pipeline,后者是一个用于上下文赌臂问题中OPE的库。然而,SCOPE-RL还实现了一套OPE估计器和工具,以便于进行上下文赌臂设置的OPE实验,以及RL的OPE实验。
实现

使用SCOPE-RL的离线RL和OPE的端到端工作流程
SCOPE-RL主要由以下三个模块组成。
- dataset模块:该模块提供工具,用于在OpenAI Gym和Gymnasium类接口之上从任何环境生成合成数据。它还提供工具来预处理日志数据。
- policy模块:该模块为d3rlpy提供一个包装器类,以实现灵活的数据收集。
- ope模块:该模块提供一个通用抽象类来实现OPE估计器。它还提供一些有用的工具来执行OPS。
行为策略 (点击展开)
- 离散
- Epsilon贪心
- Softmax
- 连续
- 高斯
- 截断高斯
OPE估计器 (点击展开)
- 期望回报估计 - 基本估计器 - 直接方法(拟合Q值评估) - 轨迹重要性采样 - 每步重要性采样 - 双重稳健 - 自归一化轨迹重要性采样 - 自归一化每步重要性采样 - 自归一化双重稳健 - 状态边际估计器 - 状态-动作边际估计器 - 双重强化学习 - 权重和价值学习方法 - 增广拉格朗日方法(BestDICE、DualDICE、GradientDICE、GenDICE、MQL/MWL) - 极小极大Q学习和权重学习(MQL/MWL) - 置信区间估计 - 自助法 - Hoeffding不等式 - (经验)Bernstein不等式 - Student's t-检验 - 累积分布函数估计 - 直接方法(拟合Q值评估) - 轨迹重要性采样 - 轨迹双重稳健 - 自归一化轨迹重要性采样 - 自归一化轨迹双重稳健OPS标准(点击展开)
- 策略价值
- 策略价值下界
- 下四分位数
- 条件风险价值(CVaR)
OPS的评估指标(点击展开)
- 均方误差
- Spearman等级相关系数
- 遗憾
- 第一类和第二类错误率
- 前k个策略的{最佳/最差/平均/标准差}性能
- 前k个策略的安全违规率
- SharpeRatio@k
请注意,除了上述OPE和OPS方法外,研究人员还可以通过SCOPE-RL中实现的通用抽象类轻松实现和比较自己的估计器。此外,从业者可以将上述方法应用于他们的实际数据,以评估和选择适合自身实际情况的反事实策略。
SCOPE-RL的OPE/OPS模块的显著特点总结如下。
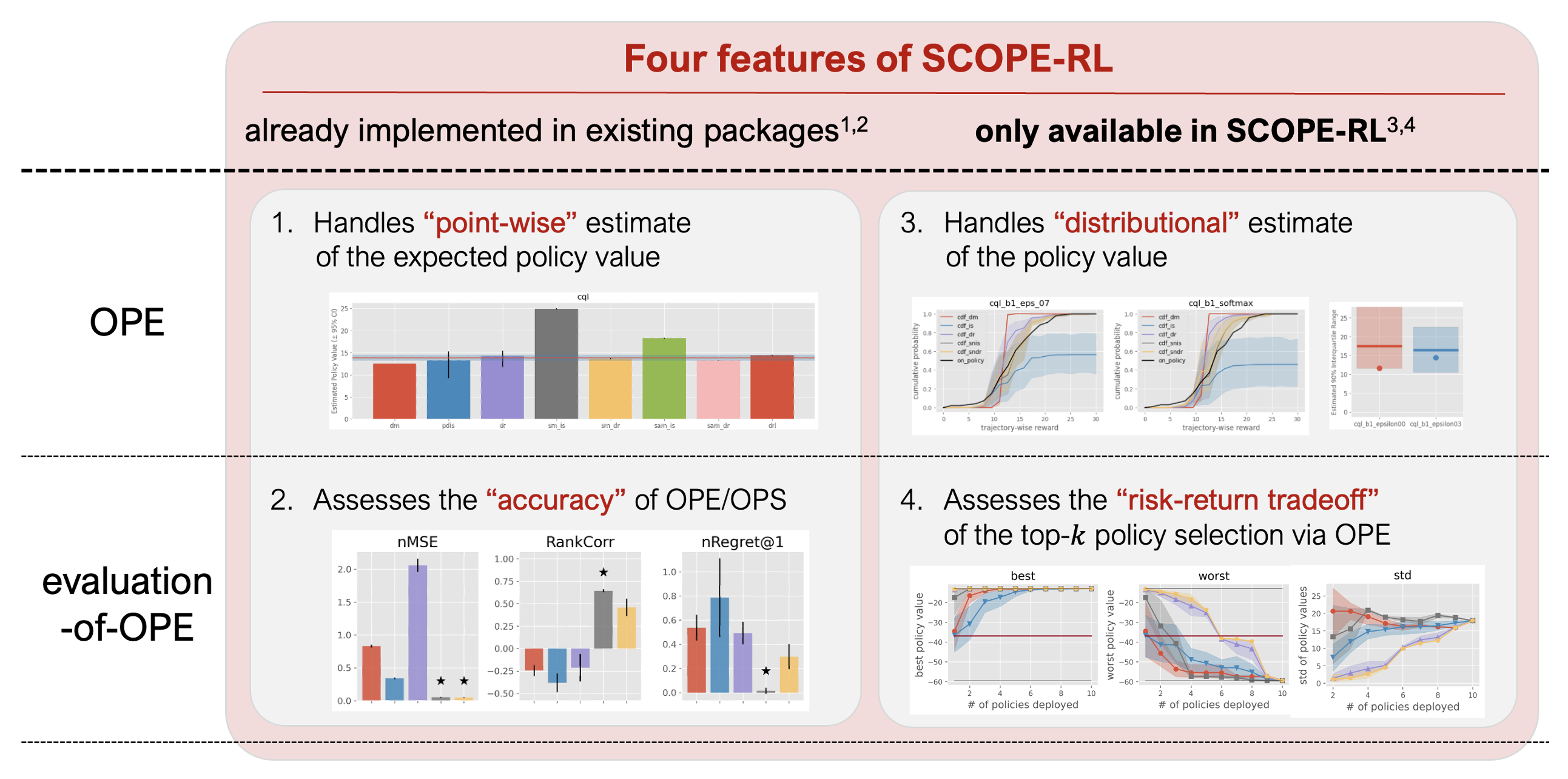
SCOPE-RL的OPE/OPS实现的四个显著特点
为了提供模拟实际设置的自定义实验示例,我们还提供了RTBGym和RecGym,这是用于实时竞价(RTB)和推荐系统的RL环境。
安装
你可以使用Python的包管理器pip来安装SCOPE-RL。
pip install scope-rl
你也可以从源代码安装SCOPE-RL。
git clone https://github.com/hakuhodo-technologies/scope-rl
cd scope-rl
python setup.py install
SCOPE-RL支持Python 3.9或更新版本。有关其他要求,请参阅requirements.txt。当遇到一些依赖冲突时,请同时参考问题#17。
使用方法
这里,我们提供了一个示例工作流程,展示如何使用SCOPE-RL在RTBGym上执行离线RL、OPE和OPS。
合成数据集生成和数据预处理
让我们从生成一些用于执行离线RL的合成日志数据开始。
# 在RTBGym环境中实现数据收集程序
# 导入SCOPE-RL模块
from scope_rl.dataset import SyntheticDataset
from scope_rl.policy import EpsilonGreedyHead
# 导入d3rlpy算法
from d3rlpy.algos import DoubleDQNConfig
from d3rlpy.dataset import create_fifo_replay_buffer
from d3rlpy.algos import ConstantEpsilonGreedy
# 导入rtbgym和gym
import rtbgym
import gym
import torch
# 随机状态
random_state = 12345
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# (0) 设置环境
env = gym.make("RTBEnv-discrete-v0")
# (1) 在在线环境中学习基准策略(使用d3rlpy)
# 初始化算法
ddqn = DoubleDQNConfig().create(device=device)
# 训练在线策略
# 这大约需要5分钟计算时间
ddqn.fit_online(
env,
buffer=create_fifo_replay_buffer(limit=10000, env=env),
explorer=ConstantEpsilonGreedy(epsilon=0.3),
n_steps=100000,
n_steps_per_epoch=1000,
update_start_step=1000,
)
# (2) 生成日志数据集
# 将ddqn策略转换为随机行为策略
behavior_policy = EpsilonGreedyHead(
ddqn,
n_actions=env.action_space.n,
epsilon=0.3,
name="ddqn_epsilon_0.3",
random_state=random_state,
)
# 初始化数据集类
dataset = SyntheticDataset(
env=env,
max_episode_steps=env.step_per_episode,
)
# 行为策略收集一些日志数据
train_logged_dataset = dataset.obtain_episodes(
behavior_policies=behavior_policy,
n_trajectories=10000,
random_state=random_state,
)
test_logged_dataset = dataset.obtain_episodes(
behavior_policies=behavior_policy,
n_trajectories=10000,
random_state=random_state + 1,
)
离线强化学习
现在我们准备使用d3rlpy从日志数据中学习新的策略(评估策略)。
# 使用SCOPE-RL和d3rlpy实现离线RL程序
# 导入d3rlpy算法
from d3rlpy.dataset import MDPDataset
from d3rlpy.algos import DiscreteCQLConfig
# (3) 从离线日志数据中学习新策略(使用d3rlpy)
# 将日志数据集转换为d3rlpy的数据集格式
offlinerl_dataset = MDPDataset(
observations=train_logged_dataset["state"],
actions=train_logged_dataset["action"],
rewards=train_logged_dataset["reward"],
terminals=train_logged_dataset["done"],
)
# 初始化算法
cql = DiscreteCQLConfig().create(device=device)
# 训练离线策略
cql.fit(
offlinerl_dataset,
n_steps=10000,
)
基本离线策略评估
然后,我们使用行为策略收集的离线日志数据来评估几种评估策略(ddqn、cql和随机)的性能。具体来说,我们比较了各种OPE估计器的估计结果,包括直接方法(DM)、轨迹重要性采样(TIS)、每步重要性采样(PDIS)和双重稳健(DR)。
# 使用SCOPE-RL实现基本的OPE程序
# 导入SCOPE-RL模块
from scope_rl.ope import CreateOPEInput
from scope_rl.ope import OffPolicyEvaluation as OPE
from scope_rl.ope.discrete import DirectMethod as DM
from scope_rl.ope.discrete import TrajectoryWiseImportanceSampling as TIS
from scope_rl.ope.discrete import PerDecisionImportanceSampling as PDIS
from scope_rl.ope.discrete import DoublyRobust as DR
# (4) 以离线方式评估学习到的策略
# 我们比较 ddqn、cql 和随机策略
cql_ = EpsilonGreedyHead(
base_policy=cql,
n_actions=env.action_space.n,
name="cql",
epsilon=0.0,
random_state=random_state,
)
ddqn_ = EpsilonGreedyHead(
base_policy=ddqn,
n_actions=env.action_space.n,
name="ddqn",
epsilon=0.0,
random_state=random_state,
)
random_ = EpsilonGreedyHead(
base_policy=ddqn,
n_actions=env.action_space.n,
name="random",
epsilon=1.0,
random_state=random_state,
)
evaluation_policies = [cql_, ddqn_, random_]
# 创建 OPE 类的输入
prep = CreateOPEInput(
env=env,
)
input_dict = prep.obtain_whole_inputs(
logged_dataset=test_logged_dataset,
evaluation_policies=evaluation_policies,
require_value_prediction=True,
n_trajectories_on_policy_evaluation=100,
random_state=random_state,
)
# 初始化 OPE 类
ope = OPE(
logged_dataset=test_logged_dataset,
ope_estimators=[DM(), TIS(), PDIS(), DR()],
)
# 执行 OPE 并可视化结果
ope.visualize_off_policy_estimates(
input_dict,
random_state=random_state,
sharey=True,
)

OPE 估计器估计的策略值
更正式的 RTBGym 示例实现可在 ./examples/quickstart/rtb/ 找到。RecGym 的示例也可在 ./examples/quickstart/rec/ 找到。
高级离线策略评估
除了预期性能外,我们还可以估计评估策略的各种统计数据,包括方差和条件风险值(CVaR),这是通过估计评估策略下奖励的累积分布函数(CDF)来实现的。
# 使用 SCOPE-RL 实现累积分布估计程序
# 导入 SCOPE-RL 模块
from scope_rl.ope import CumulativeDistributionOPE
from scope_rl.ope.discrete import CumulativeDistributionDM as CD_DM
from scope_rl.ope.discrete import CumulativeDistributionTIS as CD_IS
from scope_rl.ope.discrete import CumulativeDistributionTDR as CD_DR
from scope_rl.ope.discrete import CumulativeDistributionSNTIS as CD_SNIS
from scope_rl.ope.discrete import CumulativeDistributionSNTDR as CD_SNDR
# (4) 以离线方式评估评估策略下奖励的累积分布函数
# 我们比较上一节(即基本 OPE 程序的第(3)部分)中定义的 ddqn、cql 和随机策略
# 初始化 OPE 类
cd_ope = CumulativeDistributionOPE(
logged_dataset=test_logged_dataset,
ope_estimators=[
CD_DM(estimator_name="cd_dm"),
CD_IS(estimator_name="cd_is"),
CD_DR(estimator_name="cd_dr"),
CD_SNIS(estimator_name="cd_snis"),
CD_SNDR(estimator_name="cd_sndr"),
],
)
# 估计方差
variance_dict = cd_ope.estimate_variance(input_dict)
# 估计 CVaR
cvar_dict = cd_ope.estimate_conditional_value_at_risk(input_dict, alphas=0.3)
# 估计并可视化策略性能的累积分布函数
cd_ope.visualize_cumulative_distribution_function(input_dict, n_cols=4)

OPE 估计器估计的累积分布函数
更多详细示例,请参考 quickstart/rtb/rtb_synthetic_discrete_advanced.ipynb。
离线策略选择和 OPE/OPS 评估
我们还可以基于 OPE 结果,使用 OPS 类从一组候选策略中选择表现最佳的策略。同时,还可以使用各种指标(如均方误差、排序相关性、遗憾和 I 类及 II 类错误率)来评估 OPE/OPS 的可靠性。
# 基于 OPE 结果进行离线策略选择
# 导入 SCOPE-RL 模块
from scope_rl.ope import OffPolicySelection
# (5) 进行离线策略选择
# 初始化 OPS 类
ops = OffPolicySelection(
ope=ope,
cumulative_distribution_ope=cd_ope,
)
# 根据(基本)OPE 估计的策略值对候选策略进行排序
ranking_dict = ops.select_by_policy_value(input_dict)
# 根据累积分布 OPE 估计的策略值对候选策略进行排序
ranking_dict_ = ops.select_by_policy_value_via_cumulative_distribution_ope(input_dict)
# 可视化前 k 个部署结果
ops.visualize_topk_policy_value_selected_by_standard_ope(
input_dict=input_dict,
compared_estimators=["dm", "tis", "pdis", "dr"],
relative_safety_criteria=1.0,
)
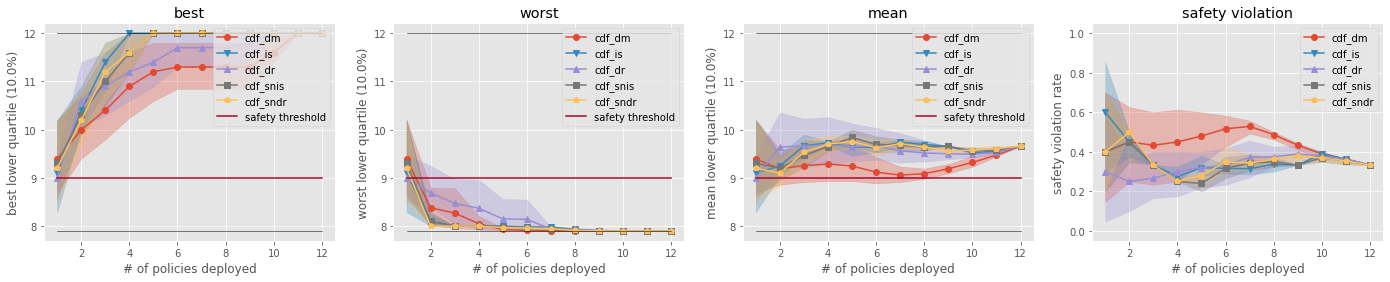
策略值 10% 下四分位数的前 k 个统计数据比较
# (6) 评估 OPS/OPE 结果
# 根据估计的下四分位数对候选策略进行排序并评估选择结果
ranking_df, metric_df = ops.select_by_lower_quartile(
input_dict,
alpha=0.3,
return_metrics=True,
return_by_dataframe=True,
)
# 使用真实指标可视化 OPS 结果
ops.visualize_conditional_value_at_risk_for_validation(
input_dict,
alpha=0.3,
share_axes=True,
)

策略值估计方差与真实方差的验证
更多示例,请参考 quickstart/rtb/rtb_synthetic_discrete_advanced.ipynb 了解离散动作,以及 quickstart/rtb/rtb_synthetic_continuous_advanced.ipynb 了解连续动作。
引用
如果您在工作中使用了我们的软件,请引用我们的论文:
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
[arXiv] [幻灯片]
Bibtex:
@article{kiyohara2023scope,
author = {Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nataka, Kazuhide and Saito, Yuta},
title = {SCOPE-RL: 一个用于离线强化学习和离线策略评估的Python库},
journal={arXiv preprint arXiv:2311.18206},
year={2023},
}
如果您在研究中使用了我们提出的"SharpeRatio@k"指标,请引用我们的论文:
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito.
评估和基准测试离线策略评估的风险收益权衡
[arXiv] [幻灯片]
Bibtex:
@article{kiyohara2023towards,
author = {Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nataka, Kazuhide and Saito, Yuta},
title = {评估和基准测试离线策略评估的风险收益权衡},
journal={arXiv preprint arXiv:2311.18207},
year={2023},
}
Google群组
如果您对SCOPE-RL感兴趣,请通过以下Google群组关注其更新: https://groups.google.com/g/scope-rl
贡献
我们非常欢迎对SCOPE-RL的任何贡献! 请参阅CONTRIBUTING.md了解如何为项目做出贡献的一般指南。
许可证
本项目采用Apache 2.0许可证 - 详情请见LICENSE文件。
项目团队
- Haruka Kiyohara(主要贡献者;康奈尔大学)
- Ren Kishimoto(东京工业大学)
- Kosuke Kawakami(株式会社博报堂科技)
- Ken Kobayashi(东京工业大学)
- Kazuhide Nakata(东京工业大学)
- Yuta Saito(康奈尔大学)
联系方式
如果您对论文和软件有任何疑问,请随时联系:hk844@cornell.edu
参考文献
论文(点击展开)
-
Alina Beygelzimer和John Langford。用于部分标签学习的偏移树。发表于第15届ACM SIGKDD国际知识发现与数据挖掘会议论文集,129-138页,2009年。
-
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang和Wojciech Zaremba。OpenAI Gym。arXiv预印本arXiv:1606.01540,2016年。
-
Yash Chandak, Scott Niekum, Bruno Castro da Silva, Erik Learned-Miller, Emma Brunskill和Philip S. Thomas。通用离线策略评估。发表于神经信息处理系统进展,2021年。
-
Miroslav Dudík, Dumitru Erhan, John Langford和Lihong Li。双重稳健的策略评估和优化。发表于统计科学,485-511页,2014年。
-
Justin Fu, Mohammad Norouzi, Ofir Nachum, George Tucker, Ziyu Wang, Alexander Novikov, Mengjiao Yang, Michael R. Zhang, Yutian Chen, Aviral Kumar, Cosmin Paduraru, Sergey Levine和Tom Le Paine。深度离线策略评估的基准。发表于国际学习表示会议,2021年。
-
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel和Sergey Levine。软演员-评论家:具有随机演员的离线策略最大熵深度强化学习。发表于第35届国际机器学习会议论文集,1861-1870页,2018年。
-
Josiah P. Hanna, Peter Stone和Scott Niekum。基于模型的自举:离线策略评估的置信区间。发表于第31届AAAI人工智能会议论文集,2017年。
-
Hado van Hasselt, Arthur Guez和David Silver。使用双Q学习的深度强化学习。发表于AAAI人工智能会议论文集,2094-2100页,2015年。
-
Audrey Huang, Liu Leqi, Zachary C. Lipton和Kamyar Azizzadenesheli。上下文赌臂中的离线风险评估。发表于神经信息处理系统进展,2021年。
-
Audrey Huang, Liu Leqi, Zachary C. Lipton和Kamyar Azizzadenesheli。马尔可夫决策过程的离线风险评估。发表于第25届国际人工智能与统计学会议论文集,5022-5050页,2022年。
-
Nan Jiang和Lihong Li。强化学习的双重稳健离线策略价值评估。发表于第33届国际机器学习会议论文集,652-661页,2016年。
-
Nathan Kallus和Masatoshi Uehara。强化学习的内在高效、稳定和有界的离线策略评估。发表于神经信息处理系统进展,3325-3334页,2019年。
-
Nathan Kallus和Masatoshi Uehara。马尔可夫决策过程中高效离线策略评估的双重强化学习。发表于机器学习研究杂志,第167卷,2020年。
-
Nathan Kallus和Angela Zhou。连续处理的策略评估和优化。发表于第21届国际人工智能与统计学会议论文集,1243-1251页,2019年。
-
Aviral Kumar, Aurick Zhou, George Tucker和Sergey Levine。离线强化学习的保守Q学习。发表于神经信息处理系统进展,1179-1191页,2020年。
-
Vladislav Kurenkov和Sergey Kolesnikov。展示您的离线强化学习工作:在线评估预算很重要。发表于第39届国际机器学习会议论文集,11729-11752页,2022年。
-
Hoang Le、Cameron Voloshin 和 Yisong Yue。约束条件下的批量策略学习。发表于《第36届国际机器学习会议论文集》,3703-3712页,2019年。
-
Haanvid Lee、Jongmin Lee、Yunseon Choi、Wonseok Jeon、Byung-Jun Lee、Yung-Kyun Noh 和 Kee-Eung Kim。连续动作情境赌博机中离线策略评估的局部度量学习。发表于《神经信息处理系统进展》,xxxx-xxxx页,2022年。
-
Sergey Levine、Aviral Kumar、George Tucker 和 Justin Fu。离线强化学习:教程、综述及开放问题展望。arXiv 预印本 arXiv:2005.01643,2020年。
-
Qiang Liu、Lihong Li、Ziyang Tang 和 Dengyong Zhou。打破视野诅咒:无限视野离线策略估计。发表于《神经信息处理系统进展》,2018年。
-
Ofir Nachum、Yinlam Chow、Bo Dai 和 Lihong Li。DualDICE:与行为无关的折扣稳态分布校正估计。发表于《神经信息处理系统进展》,2019年。
-
Ofir Nachum、Bo Dai、Ilya Kostrikov、Yinlam Chow、Lihong Li 和 Dale Schuurmans。AlgaeDICE:从任意经验中进行策略梯度。arXiv 预印本 arXiv:1912.02074,2019年。
-
Tom Le Paine、Cosmin Paduraru、Andrea Michi、Caglar Gulcehre、Konrad Zolna、Alexander Novikov、Ziyu Wang 和 Nando de Freitas。离线强化学习的超参数选择。arXiv 预印本 arXiv:2007.09055,2020年。
-
Doina Precup、Richard S. Sutton 和 Satinder P. Singh。离线策略评估的资格迹。发表于《第17届国际机器学习会议论文集》,759-766页,2000年。
-
Rafael Figueiredo Prudencio、Marcos R. O. A. Maximo 和 Esther Luna Colombini。离线强化学习综述:分类、回顾和开放问题。arXiv 预印本 arXiv:2203.01387,2022年。
-
Yuta Saito、Shunsuke Aihara、Megumi Matsutani 和 Yusuke Narita。开放赌博机数据集和流水线:实现真实可复现的离线策略评估。发表于《神经信息处理系统进展》,2021年。
-
Takuma Seno 和 Michita Imai。d3rlpy:一个离线深度强化学习库。arXiv 预印本 arXiv:2111.03788,2021年。
-
Alex Strehl、John Langford、Sham Kakade 和 Lihong Li。从记录的隐式探索数据中学习。发表于《神经信息处理系统进展》,2217-2225页,2010年。
-
Adith Swaminathan 和 Thorsten Joachims。反事实学习的自归一化估计器。发表于《神经信息处理系统进展》,3231-3239页,2015年。
-
Shengpu Tang 和 Jenna Wiens。离线强化学习的模型选择:医疗环境中的实际考虑。发表于《第6届医疗机器学习会议论文集》,2-35页,2021年。
-
Philip S. Thomas 和 Emma Brunskill。强化学习的数据高效离线策略评估。发表于《第33届国际机器学习会议论文集》,2139-2148页,2016年。
-
Philip S. Thomas、Georgios Theocharous 和 Mohammad Ghavamzadeh。高置信度离线策略评估。发表于《第9届AAAI人工智能会议论文集》,2015年。
-
Philip S. Thomas、Georgios Theocharous 和 Mohammad Ghavamzadeh。高置信度策略改进。发表于《第32届国际机器学习会议论文集》,2380-2388页,2015年。
-
Masatoshi Uehara、Jiawei Huang 和 Nan Jiang。离线策略评估的极小极大权重和Q函数学习。发表于《第37届国际机器学习会议论文集》,9659-9668页,2020年。
-
Masatoshi Uehara、Chengchun Shi 和 Nathan Kallus。强化学习中离线策略评估综述。arXiv 预印本 arXiv:2212.06355,2022年。
-
Mengjiao Yang、Ofir Nachum、Bo Dai、Lihong Li 和 Dale Schuurmans。通过正则化拉格朗日方法进行离线策略评估。发表于《神经信息处理系统进展》,6551-6561页,2020年。
-
Christina J. Yuan、Yash Chandak、Stephen Giguere、Philip S. Thomas 和 Scott Niekum。SOPE:离线策略估计器谱。发表于《神经信息处理系统进展》,18958-18969页,2022年。
-
Shangtong Zhang、Bo Liu 和 Shimon Whiteson。GradientDICE:重新思考广义离线稳态值估计。发表于《第37届国际机器学习会议论文集》,11194-11203页,2020年。
-
Ruiyi Zhang、Bo Dai、Lihong Li 和 Dale Schuurmans。GenDICE:广义离线稳态值估计。发表于《国际学习表示会议》,2020年。
项目 本项目主要受到以下三个软件包的强烈启发:











