
 Github
Github Huggingface
Huggingface 论文
论文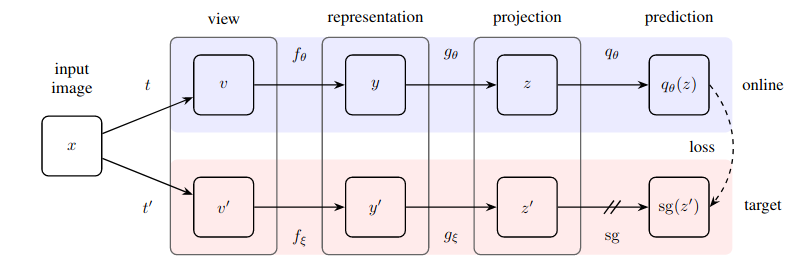
Pytorch实现的Bootstrap Your Own Latent (BYOL)

一种令人惊讶的简单方法的实际实现——一种自监督学习方法,它在无需对比学习和指定负样本对的情况下,达到了新的技术水平(超越SimCLR)。
这个仓库提供了一个模块,可以轻松地包装任何基于图像的神经网络(剩余网络、判别器、策略网络),以立即开始利用未标记的图像数据。
更新 1:现在有新证据表明批量归一化是使这种技术工作得很好的关键
更新 2:一篇新论文成功将批量归一化替换为组归一化和权重标准化,驳斥了BYOL需要批量统计量才能工作
更新 3:终于,我们有了一些分析来说明为什么这能起作用
现在,去拯救你的组织,不用再为标签付费了 :)
安装
$ pip install byol-pytorch
用法
只需插入你的神经网络,指定(1)图像尺寸以及(2)隐藏层的名称(或索引),其输出将用作用于自监督训练的潜在表示。
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models.resnet50(pretrained=True)
learner = BYOL(
resnet,
image_size = 256,
hidden_layer = 'avgpool'
)
opt = torch.optim.Adam(learner.parameters(), lr=3e-4)
def sample_unlabelled_images():
return torch.randn(20, 3, 256, 256)
for _ in range(100):
images = sample_unlabelled_images()
loss = learner(images)
opt.zero_grad()
loss.backward()
opt.step()
learner.update_moving_average() # 更新目标编码器的移动平均
# 保存改进后的网络
torch.save(resnet.state_dict(), './improved-net.pt')
基本上就这些。经过大量训练后,剩余网络现在应能更好地完成其下游监督任务。
BYOL → SimSiam
来自何恺明的新论文表明,BYOL甚至不需要目标编码器是线上编码器的指数移动平均。我决定内置此选项,这样你可以通过将use_momentum标志设置为False轻松使用该变体进行训练。如果你采用此方法,则不再需要调用update_moving_average,如下例所示。
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models.resnet50(pretrained=True)
learner = BYOL(
resnet,
image_size = 256,
hidden_layer = 'avgpool',
use_momentum = False # 关闭目标编码器的动量
)
opt = torch.optim.Adam(learner.parameters(), lr=3e-4)
def sample_unlabelled_images():
return torch.randn(20, 3, 256, 256)
for _ in range(100):
images = sample_unlabelled_images()
loss = learner(images)
opt.zero_grad()
loss.backward()
opt.step()
# 保存改进后的网络
torch.save(resnet.state_dict(), './improved-net.pt')
进阶
虽然超参数已经设置为论文中找到的最佳值,但你可以使用基础包装类的额外关键字参数来更改它们。
learner = BYOL(
resnet,
image_size = 256,
hidden_layer = 'avgpool',
projection_size = 256, # 投影大小
projection_hidden_size = 4096, # 投影和预测的MLP的隐藏维度
moving_average_decay = 0.99 # 目标编码器的移动平均衰减因子,已设置为论文推荐值
)
默认情况下,此库将使用来自SimCLR论文的增强(BYOL论文中也使用了)。但是,如果你想指定自己的增强管道,可以简单地通过augment_fn关键字传递你自己的自定义增强函数。
augment_fn = nn.Sequential(
kornia.augmentation.RandomHorizontalFlip()
)
learner = BYOL(
resnet,
image_size = 256,
hidden_layer = -2,
augment_fn = augment_fn
)
在论文中,他们似乎保证其中一个增强的高斯模糊概率比另一个高。你也可以根据自己的喜好进行调整。
augment_fn = nn.Sequential(
kornia.augmentation.RandomHorizontalFlip()
)
augment_fn2 = nn.Sequential(
kornia.augmentation.RandomHorizontalFlip(),
kornia.filters.GaussianBlur2d((3, 3), (1.5, 1.5))
)
learner = BYOL(
resnet,
image_size = 256,
hidden_layer = -2,
augment_fn = augment_fn,
augment_fn2 = augment_fn2,
)
要获取嵌入或投影,你只需将return_embeddings = True标志传递给BYOL学习实例
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models.resnet50(pretrained=True)
learner = BYOL(
resnet,
image_size = 256,
hidden_layer = 'avgpool'
)
imgs = torch.randn(2, 3, 256, 256)
projection, embedding = learner(imgs, return_embedding = True)
分布式训练
该仓库现在提供了使用🤗 Huggingface Accelerate进行分布式训练的功能。你只需将你自己的Dataset传递给导入的BYOLTrainer
首先使用accelerate CLI设置分布式训练的配置
$ accelerate config
然后按如下所示制作你的训练脚本,比如在./train.py中
from torchvision import models
from byol_pytorch import (
BYOL,
BYOLTrainer,
MockDataset
)
resnet = models.resnet50(pretrained = True)
dataset = MockDataset(256, 10000)
trainer = BYOLTrainer(
resnet,
dataset = dataset,
image_size = 256,
hidden_layer = 'avgpool',
learning_rate = 3e-4,
num_train_steps = 100_000,
batch_size = 16,
checkpoint_every = 1000 # 改进后的模型将定期保存到./checkpoints文件夹
)
trainer()
然后再次使用accelerate CLI启动脚本
$ accelerate launch ./train.py
替代方案
如果你的下游任务涉及分割,请查看以下仓库,该仓库将BYOL扩展到“像素”级学习。
https://github.com/lucidrains/pixel-level-contrastive-learning
引用
@misc{grill2020bootstrap,
title = {Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning},
author = {Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko},
year = {2020},
eprint = {2006.07733},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@misc{chen2020exploring,
title={Exploring Simple Siamese Representation Learning},
author={Xinlei Chen and Kaiming He},
year={2020},
eprint={2011.10566},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











