
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文
GigaGAN - Pytorch
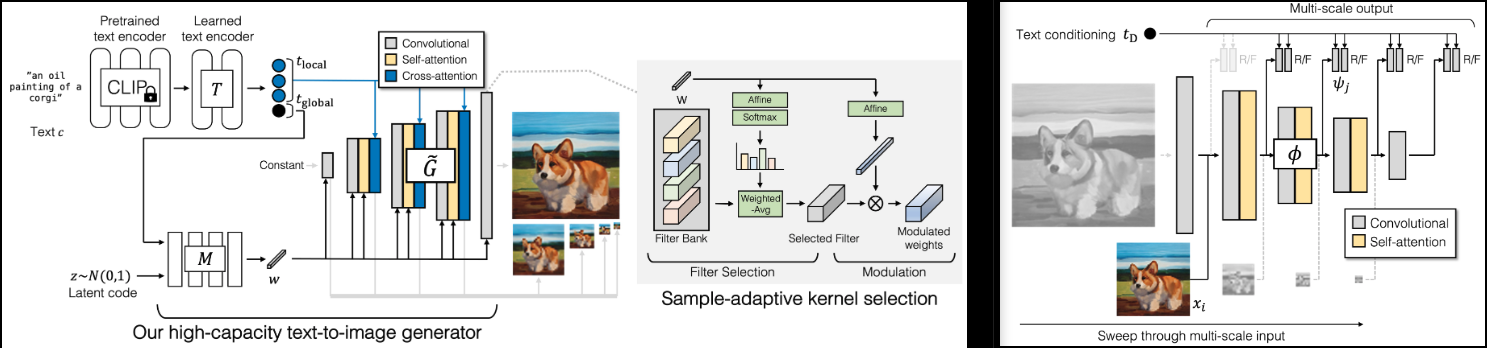
实现 GigaGAN (项目页面),Adobe 最新的 SOTA GAN。
我还会添加一些来自轻量级 gan的发现,以加快收敛(跳层激励)和更好的稳定性(判别器中的辅助重建损失)
它还将包含 1k - 4k 上采样器的代码,这是我认为这篇论文的亮点。
如果您有兴趣与 LAION 社区一起帮助复制,请加入  。
。
感谢
-
感谢 StabilityAI 和 🤗 Huggingface 的慷慨赞助,以及我的其他赞助商们,使我能够独立开源人工智能。
-
感谢 🤗 Huggingface 的 accelerate 库
-
感谢 OpenClip 的所有维护者,他们的 SOTA 开源对比学习文本-图像模型
-
感谢 Xavier 的非常有帮助的代码审查,以及关于如何构建判别器中的尺度不变性进行的讨论!
-
感谢 @CerebralSeed 提出生成器和上采样器初始采样代码的拉取请求!
-
感谢 Keerth 的代码审查和指出与论文的一些差异!
安装
$ pip install gigagan-pytorch
使用方法
简单的无条件 GAN,供初学者使用
import torch
from gigagan_pytorch import (
GigaGAN,
ImageDataset
)
gan = GigaGAN(
generator = dict(
dim_capacity = 8,
style_network = dict(
dim = 64,
depth = 4
),
image_size = 256,
dim_max = 512,
num_skip_layers_excite = 4,
unconditional = True
),
discriminator = dict(
dim_capacity = 16,
dim_max = 512,
image_size = 256,
num_skip_layers_excite = 4,
unconditional = True
),
amp = True
).cuda()
# 数据集
dataset = ImageDataset(
folder = '/path/to/your/data',
image_size = 256
)
dataloader = dataset.get_dataloader(batch_size = 1)
# 在训练前必须为 GAN 设置数据加载器
gan.set_dataloader(dataloader)
# 交替训练判别器和生成器
# 在这个例子中训练 100 步,批量大小 1,梯度累积 8 次
gan(
steps = 100,
grad_accum_every = 8
)
# 经过大量训练后
images = gan.generate(batch_size = 4) # (4, 3, 256, 256)
对于无条件 Unet 上采样器
import torch
from gigagan_pytorch import (
GigaGAN,
ImageDataset
)
gan = GigaGAN(
train_upsampler = True, # 将其设置为 True
generator = dict(
style_network = dict(
dim = 64,
depth = 4
),
dim = 32,
image_size = 256,
input_image_size = 64,
unconditional = True
),
discriminator = dict(
dim_capacity = 16,
dim_max = 512,
image_size = 256,
num_skip_layers_excite = 4,
multiscale_input_resolutions = (128,),
unconditional = True
),
amp = True
).cuda()
dataset = ImageDataset(
folder = '/path/to/your/data',
image_size = 256
)
dataloader = dataset.get_dataloader(batch_size = 1)
gan.set_dataloader(dataloader)
# 交替训练判别器和生成器
# 在这个例子中训练 100 步,批量大小 1,梯度累积 8 次
gan(
steps = 100,
grad_accum_every = 8
)
# 经过大量训练后
lowres = torch.randn(1, 3, 64, 64).cuda()
images = gan.generate(lowres) # (1, 3, 256, 256)
损失
G- 生成器MSG- 多尺度生成器D- 判别器MSD- 多尺度判别器GP- 梯度惩罚SSL- 判别器中的辅助重建(来自轻量级 GAN)VD- 视觉辅助判别器VG- 视觉辅助生成器CL- 生成器对比损失MAL- 匹配感知损失
一个健康的运行应该使 G、MSG、D、MSD 的值保持在0到10之间,并且通常保持相当稳定。如果在 1k 训练步后这些值仍然保持在三位数,那就说明出了问题。生成器和判别器的值偶尔下降为负数是可以的,但它应该恢复到上述范围内。
GP 和 SSL 应该朝0推动。GP可能会偶尔飙升;我喜欢把这想象成网络经历了一些顿悟
多 GPU 训练
GigaGAN 类现在配有 🤗 Accelerator。您可以使用 accelerate CLI 轻松完成两步多 GPU 训练
在项目的根目录下,训练脚本所在的位置,运行
$ accelerate config
然后,在同一目录下
$ accelerate launch train.py
待办事项
-
确保它可以无条件训练
-
阅读相关论文并完成所有 3 个辅助损失
- 匹配感知损失
- clip 损失
- 视觉辅助判别器损失
- 在判别器的任意阶段添加重建损失(轻量级 gan)
- 弄清随机投影如何在投影 gan 中使用
- 视觉辅助判别器需要从 CLIP 中提取 N 层
- 弄清楚是丢弃 CLS 标记并重塑为图像尺寸用于卷积,还是坚持使用注意力并用自适应层归一化进行调节 - 还要在无条件情况下关闭视觉辅助 gan
-
unet 上采样器
- 添加自适应卷积
- 修改 unet 的后期输出 RGB 残差,并将 RGB 传递给判别器。使判别器对传入的 RGB 具有鲁棒性
- 对 unet 进行像素洗牌上采样
-
对多尺度输入和输出进行代码审查,因为论文有点模糊
-
添加上采样网络架构
-
确保无条件工作于基础生成器和上采样器
-
确保文本条件训练工作于基础生成器和上采样器
-
通过随机采样补丁使重建更高效
-
确保生成器和判别器也能接受预编码的 CLIP 文本编码
-
审查辅助损失
- 为生成器添加对比损失
- 添加视觉辅助损失
- 为视觉辅助判别器添加梯度惩罚 - 可选
- 添加匹配感知损失 - 弄清旋转文本条件是否足以用于错配(无需从数据加载器中抽取额外批次)
- 确保与匹配感知损失一起工作的梯度累积
- 匹配感知损失运行且稳定
- 视觉辅助训练
-
添加一些可微分增强技术,这是旧 GAN 时代的已验证技巧
- 移除任何自动 RGB 处理的魔法,并显式传递它 - 为判别器提供处理真实图像到正确多尺度的函数
- 首先添加水平翻转
-
将所有调制投影移动到 adaptive conv2d 类中
-
添加加速
- 单机工作
- 混合精度工作(确保梯度惩罚正确缩放),注意手动缩放器的保存和重新加载,从 imagen-pytorch 借用
- 确保多 GPU 对于单机工作
- 让别人尝试多台机器
-
clip 应该对所有模块都是可选的,并由
GigaGAN管理,用一次处理的文本 -> 文本嵌入 -
添加选择多尺度维度的随机子集的能力,以提高效率
-
从 lightweight|stylegan2-pytorch 移植 CLI
-
挂接 laion 数据集以进行文本-图像
引用
@misc{https://doi.org/10.48550/arxiv.2303.05511,
url = {https://arxiv.org/abs/2303.05511},
author = {Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung},
title = {Scaling up GANs for Text-to-Image Synthesis},
publisher = {arXiv},
year = {2023},
copyright = {arXiv.org perpetual, non-exclusive license}
}
@article{Liu2021TowardsFA,
title = {Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis},
author = {Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal},
journal = {ArXiv},
year = {2021},
volume = {abs/2101.04775}
}
@inproceedings{dao2022flashattention,
title = {Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author = {Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
booktitle = {Advances in Neural Information Processing Systems},
year = {2022}
}
@inproceedings{Karras2020ada,
title = {Training Generative Adversarial Networks with Limited Data},
author = {Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila},
booktitle = {Proc. NeurIPS},
year = {2020}
}
@article{Xu2024VideoGigaGANTD,
title = {VideoGigaGAN: Towards Detail-rich Video Super-Resolution},
author = {Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu},
journal = {ArXiv},
year = {2024},
volume = {abs/2404.12388},
url ={https://api.semanticscholar.org/CorpusID:269214195}
}











