
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文

Rho-1: 并非所有词元都是您所需要的
[📜 Arxiv] • [💬 HF论文] • [🤗 模型] • [🐱 GitHub]
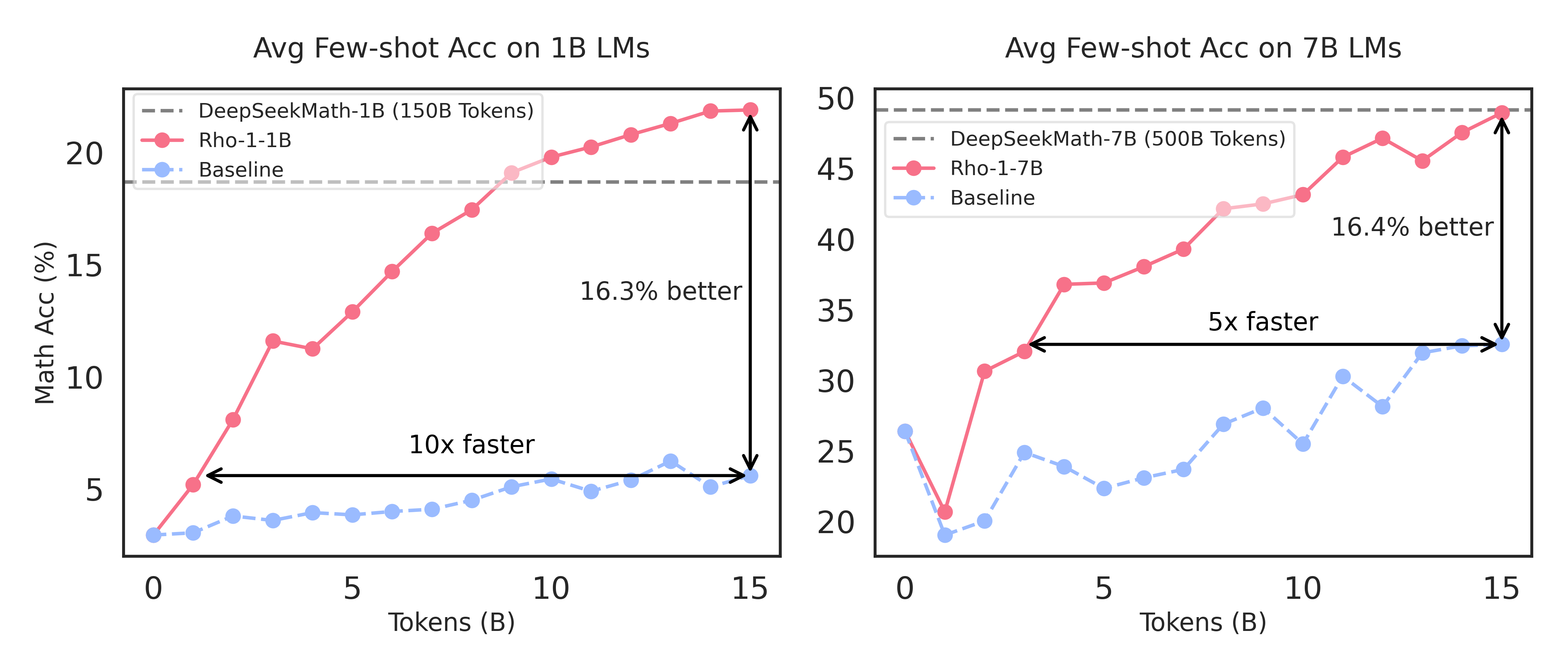
图1:Rho-1采用选择性语言建模(SLM)进行预训练。SLM将GSM8k和MATH的平均少样本准确率提高了16%以上,实现基线性能的速度快5-10倍。
🔥 新闻
- [2024/04/12] 🔥🔥🔥 Rho-Math-v0.1模型在🤗 HuggingFace上发布!
- Rho-Math-1B和Rho-Math-7B在MATH数据集上分别达到15.6%和31.0%的少样本准确率,仅使用3%的预训练词元就与DeepSeekMath相匹配。
- Rho-Math-1B-Interpreter是第一个在MATH上准确率超过40%的1B大语言模型。
- Rho-Math-7B-Interpreter在MATH数据集上达到52%的准确率,仅使用69k样本进行微调。
- [2024/04/11] Rho-1论文和代码库发布。
💡 简介
Rho-1基础模型在预训练中采用选择性语言建模(SLM),有选择地训练与所需分布一致的干净有用的词元。
选择性语言建模(SLM)
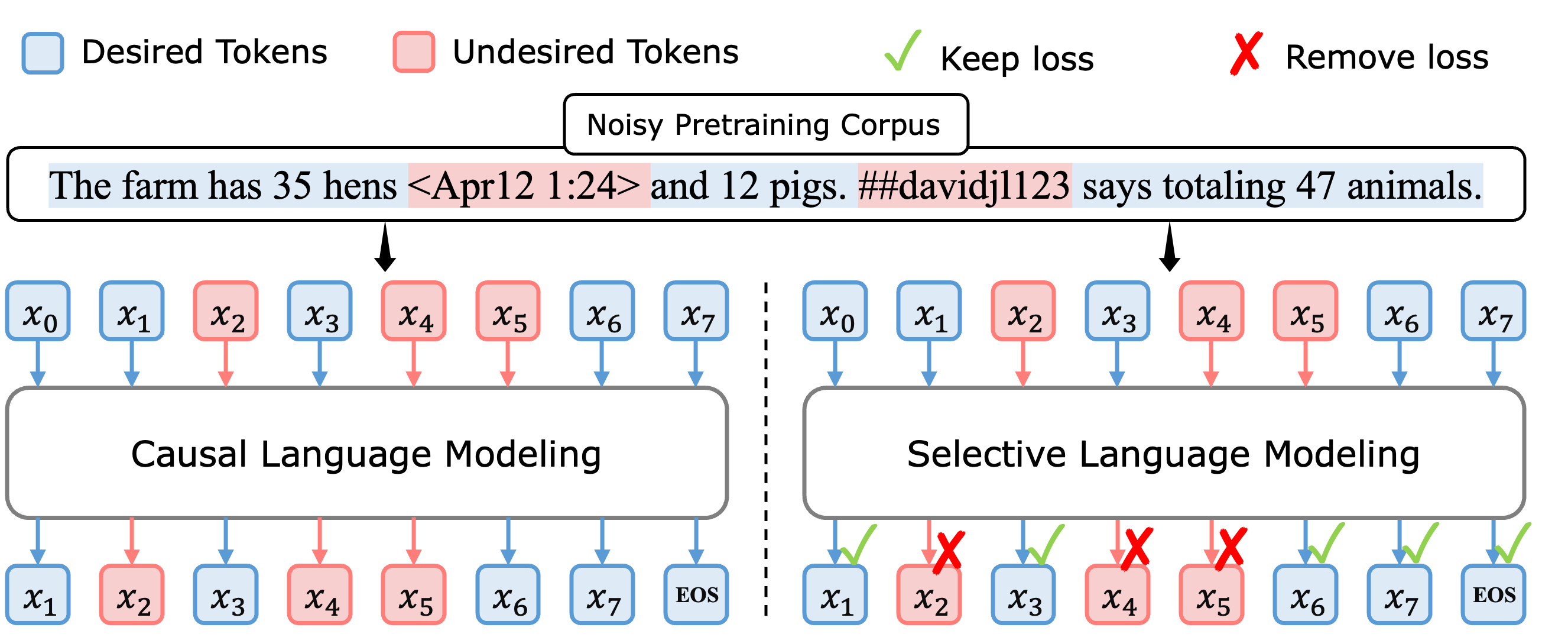
图2:
上图:即使经过广泛过滤的预训练语料库仍包含词元级噪声。
左图:以往的因果语言建模(CLM)对所有词元进行训练。
右图:我们提出的选择性语言建模(SLM)有选择地对那些有用且干净的词元应用损失。

图3:选择性语言建模的流程。
SLM通过在预训练期间专注于有价值、干净的词元来优化语言模型性能。
它包括三个步骤:
(步骤1)首先,在高质量数据上训练参考模型。
(步骤2)然后,使用参考模型对语料库中每个词元的损失进行评分。
(步骤3)最后,有选择地对那些相对于参考损失显示更高超额损失的词元训练语言模型。
评估结果
基础模型(少样本思维链):
| 模型 | 规模 | 数据 | 唯一令牌数 | 训练令牌数 | GSM8K | MATH | MMLU STEM | SAT |
|---|---|---|---|---|---|---|---|---|
| 1-2B 基础模型 | ||||||||
| Qwen1.5 | 1.8B | - | - | - | 36.1 | 6.8 | 31.3 | 40.6 |
| Gemma | 2.0B | - | - | - | 18.8 | 11.4 | 34.4 | 50.0 |
| DeepSeekMath | 1.3B | - | 120B | 150B | 23.8 | 13.6 | 33.1 | 56.3 |
| Rho-Math-1B-v0.1 | 1.1B | OWM | 14B | 30B | 36.2 | 15.6 | 23.3 | 28.1 |
| >= 7B 基础模型 | ||||||||
| Mistral | 7B | - | - | 41.2 | 11.6 | 49.5 | 59.4 | |
| Minerva | 540B | - | 39B | 26B | 58.8 | 33.6 | 63.9 | - |
| LLemma | 34B | PPile | 55B | 50B | 54.2 | 23.0 | 54.7 | 68.8 |
| InternLM2-Math | 20B | - | 31B | 125B | 65.4 | 30.0 | 53.1 | 71.9 |
| DeepSeekMath | 7B | - | 120B | 500B | 64.1 | 34.2 | 56.4 | 84.4 |
| Rho-Math-7B-v0.1 | 7B | OWM | 14B | 10.5B | 66.9 | 31.0 | 54.6 | 84.4 |
工具集成推理(代码解释器):
| 模型 | 规模 | SFT数据 | GSM8k | MATH | SVAMP | ASDiv | MAWPS | TabMWP | GSM-Hard | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| gpt4-early (pal) | - | - | 94.2 | 51.8 | 94.8 | 92.6 | 97.7 | 95.9 | 77.6 | 86.4 |
| gpt-4-turbo-2024-04-09 (cot) | - | - | - | 73.4 | - | - | - | - | - | |
| 开源小型模型 | ||||||||||
| MAmmoTH | 70B | MI-260k | 76.9 | 41.8 | 82.4 | - | - | - | - | - |
| ToRA | 7B | ToRA-69k | 68.8 | 40.1 | 68.2 | 73.9 | 88.8 | 42.4 | 54.6 | 62.4 |
| ToRA | 70B | ToRA-69k | 84.3 | 49.7 | 82.7 | 86.8 | 93.8 | 74.0 | 67.2 | 76.9 |
| DeepSeekMath | 7B | ToRA-69k | 79.8 | 52.0 | 80.1 | 87.1 | 93.8 | 85.8 | 63.1 | 77.4 |
| Rho-Math-1B-Interpreter-v0.1 | 1B | ToRA-69k | 59.4 | 40.6 | 60.7 | 74.2 | 88.6 | 26.7 | 48.1 | 56.9 |
| Rho-Math-7B-Interpreter-v0.1 | 7B | ToRA-69k | 81.3 | 51.8 | 80.8 | 85.5 | 94.5 | 70.1 | 63.1 | 75.3 |
🚀 快速开始
评估
cd rho-1/math-evaluation-harness
基础模型少样本评估:
bash scripts/run_eval.sh cot microsoft/rho-math-7b-v0.1
SFT模型(代码解释器)评估:
bash scripts/run_eval.sh tora microsoft/rho-math-7b-interpreter-v0.1
我们复现的输出结果已提供在rho-1/outputs.zip中。
🍀 贡献
本项目欢迎贡献和建议。大多数贡献需要你同意贡献者许可协议(CLA),声明你有权利授予我们使用你的贡献的权利。详情请访问 https://cla.opensource.microsoft.com。
☕️ 引用
如果你觉得这个仓库有帮助,请考虑引用我们的论文:
@misc{lin2024rho1,
title={Rho-1: Not All Tokens Are What You Need},
author={Zhenghao Lin and Zhibin Gou and Yeyun Gong and Xiao Liu and Yelong Shen and Ruochen Xu and Chen Lin and Yujiu Yang and Jian Jiao and Nan Duan and Weizhu Chen},
year={2024},
eprint={2404.07965},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











