
 Github
Github 论文
论文Mirage:一个多层次的张量代数超级优化器
Mirage是一个张量代数超级优化器,可以自动发现深度神经网络的高度优化的张量程序。Mirage自动识别和验证复杂的优化,其中许多需要在GPU计算层次结构的内核、线程块和线程级别进行联合优化。对于输入的深度神经网络,Mirage搜索与给定深度神经网络在功能上等效的潜在张量程序空间,以发现高度优化的候选程序。这种方法使Mirage能够找到优于现有专家设计的新定制内核。
安装
尝试Mirage的最快方法是通过我们预构建的docker镜像。您也可以从源代码安装Mirage。
快速入门
作为一个张量代数超级优化器,Mirage可用于优化任意深度神经网络。我们使用两个示例来展示如何使用Mirage自动生成LLAMA-3-70B中的组查询注意力(GQA)和低秩适配器(LoRA)的CUDA内核。这些由Mirage生成的内核性能优于现有的手动优化内核。
超级优化组查询注意力(GQA)
以下代码片段展示了如何使用Mirage为LLAMA-3-70B中的组查询注意力(GQA)自动生成高度优化的CUDA程序。我们假设模型以半精度服务,并在4个GPU上进行张量模型并行化以适应GPU设备内存。因此,GQA算子计算8个查询头和2个键值头的注意力。
首先,我们定义GQA的计算图,它接受三个输入张量Q、K和V,并生成一个包含注意力结果的输出张量O:
import mirage as mi
graph = mi.new_graph()
Q = graph.new_input(dims=(2, 256, 64), dtype=mi.float16)
K = graph.new_input(dims=(2, 64, 4096), dtype=mi.float16)
V = graph.new_input(dims=(2, 4096, 64), dtype=mi.float16)
A = graph.matmul(Q, K)
E = graph.exp(A)
S = graph.reduction(E, 2)
D = graph.div(E, S)
O = graph.matmul(D, V)
其次,我们将使用mi.superoptimize来超级优化GQA。Mirage将自动搜索与输入图在功能上等效的潜在mugraph空间,以发现高度优化的CUDA程序。MuGraph是Mirage中的一种新的多层次图表示,它在GPU计算层次结构的内核、线程块和线程级别指定计算。Mirage可以自动找到代表当今专家设计的GPU优化(如FlashAttention、FlashDecoding和FlashInfer)的mugraph。此外,Mirage还发现了其他在某些情况下优于这些专家设计实现的mugraph。
new_graphs = mi.superoptimize(graph, griddims=[(2, 16, 1), (2, 16, 4)])
搜索由几个参数配置,其中griddims是您可能需要为您的问题规模重置的参数。这些参数的默认值是为多头、多查询和组查询注意力量身定制的。您可以更新它们以超级优化其他神经网络架构,如低秩适配器、专家混合等。这些参数的更详细定义可在我们的论文中找到。
griddims:指定内核中可能的线程块数量。默认值(对于每个GPU有16个头的多头注意力):(16, 1, 1), (16, 2, 1), (16, 4, 1)。blockdims:指定线程块内可能的线程数量。默认值:(128, 1, 1)。imaps:输入张量的数据维度与griddims之间的潜在映射。默认值(适用于所有注意力变体):(0, -1, -1), (0, 1, -1), (0, 2, -1), (0, -1, 1)。请注意,正数表示输入张量沿该网格维度分区,而-1表示输入张量复制(详见论文)。omaps:输出张量的数据维度与griddims之间的潜在映射。默认值(适用于所有注意力变体):(0, -1, -1), (0, 1, -1), (0, 2, -1), (0, 2, 1)]。语义与imaps类似。fmaps:输入张量的数据维度与线程块的for循环维度之间的潜在映射。默认值:-1, 1, 2。与imaps类似,正数表示输入张量分区,-1表示张量复制。franges:搜索过程中考虑的可能for循环范围。默认值:1, 4, 8, 16。
除了取决于问题规模的griddims外,其他参数的默认值足以发现FlashAttn、FlashDecoding和许多其他为注意力设计的专家实现。
mi.superoptimize函数返回Mirage发现的mugraph列表,这些mugraph在功能上等同于输入程序,并代表其不同的实现。Mirage使用概率等效性验证机制来确保所有发现的mugraph与输入等效。graph.generate_triton_program为每个mugraph生成一个Triton程序。
for i, mugraph in enumerate(new_graphs):
mugraph.generate_triton_program("generated_program_{}.py".format(i))
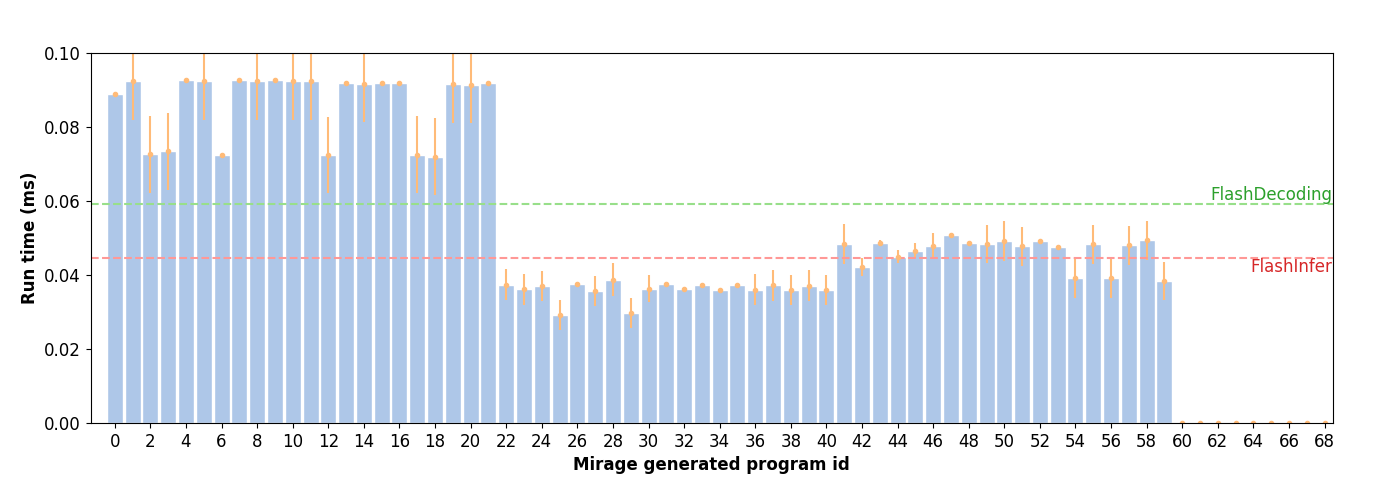
上述搜索过程大约需要4小时,并发现69个用于实现GQA的潜在张量程序。为了绕过搜索并直接检查生成的程序,我们可以从搜索的先前检查点开始,运行
python demo/demo_group_query_attention_spec_decode.py --checkpoint demo/checkpoint_group_query_attn_spec_decode.json
该程序输出69个保存在demo文件夹中的Triton程序。这些程序在NVIDIA A100 GPU上的性能如下所示。请注意,一些生成的程序在线程块内执行小矩阵乘法。这些程序无法直接被当前的Triton编译器支持,因为它要求矩阵乘法的所有维度必须至少为16。Mirage发现的最佳程序比FlashDecoding快2倍,比FlashInfer快1.5倍。
引用
描述Mirage技术的论文可在arxiv上获取。请如下引用Mirage:
@misc{wu2024mirage,
title={A Multi-Level Superoptimizer for Tensor Programs},
author={Mengdi Wu and Xinhao Cheng and Oded Padon and Zhihao Jia},
eprint={2405.05751},
archivePrefix={arXiv},
year={2024},
}
许可证
Mirage使用Apache License 2.0。











