
 访问官网
访问官网 Github
Github 文档
文档
![]()
![]()
从云存储快速、准确地流式传输训练数据
[网站] - [入门指南] - [文档] - [我们正在招聘!]





👋 欢迎
我们开发 StreamingDataset 的目的是为了让从云存储训练大型数据集变得尽可能快速、经济和可扩展。
它专为多节点、分布式大型模型训练而设计——最大化正确性保证、性能和易用性。现在,无论您的训练数据位于何处,您都可以高效地进行训练。只需在需要时流式传输所需的数据即可。要了解我们为什么要构建 StreamingDataset,请阅读我们的公告博客。
StreamingDataset 兼容任何数据类型,包括图像、文本、视频和多模态数据。
它支持主要的云存储提供商(AWS、OCI、GCS、Azure、Databricks,以及任何兼容 S3 的对象存储,如 Cloudflare R2、Coreweave、Backblaze b2 等),并设计为可直接替代 PyTorch IterableDataset 类,StreamingDataset 可无缝集成到您现有的训练工作流程中。

🚀 入门
💾 安装
可以使用 pip 安装 Streaming:
pip install mosaicml-streaming
🏁 快速开始
1. 准备数据
将原始数据集转换为我们支持的流式格式之一:
- MDS(Mosaic Data Shard)格式,可以编码和解码任何 Python 对象
- CSV / TSV
- JSONL
import numpy as np
from PIL import Image
from streaming import MDSWriter
# 存储压缩输出文件的本地或远程目录
data_dir = 'path-to-dataset'
# 将输入字段映射到其数据类型的字典
columns = {
'image': 'jpeg',
'class': 'int'
}
# 分片压缩(如果有)
compression = 'zstd'
# 使用 MDSWriter 将样本保存为分片
with MDSWriter(out=data_dir, columns=columns, compression=compression) as out:
for i in range(10000):
sample = {
'image': Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)),
'class': np.random.randint(10),
}
out.write(sample)
2. 将数据上传到云存储
将流式数据集上传到您选择的云存储(AWS、OCI 或 GCP)。以下是使用 AWS CLI 将目录上传到 S3 存储桶的示例。
$ aws s3 cp --recursive path-to-dataset s3://my-bucket/path-to-dataset
3. 构建 StreamingDataset 和 DataLoader
from torch.utils.data import DataLoader
from streaming import StreamingDataset
# 存储完整数据集的远程路径
remote = 's3://my-bucket/path-to-dataset'
# 运行期间缓存数据集的本地工作目录
local = '/tmp/path-to-dataset'
# 创建流式数据集
dataset = StreamingDataset(local=local, remote=remote, shuffle=True)
# 让我们看看样本 #1337 中有什么...
sample = dataset[1337]
img = sample['image']
cls = sample['class']
# 创建 PyTorch DataLoader
dataloader = DataLoader(dataset)
📚 接下来做什么?
入门指南、示例、API 参考和其他有用信息可以在我们的文档中找到。
我们有针对以下数据集的端到端训练模型教程:
我们还为以下流行数据集提供了起始代码,可以在 streaming 目录中找到:
| 数据集 | 任务 | 读取 | 写入 |
|---|---|---|---|
| LAION-400M | 文本和图像 | 读取 | 写入 |
| WebVid | 文本和视频 | 读取 | 写入 |
| C4 | 文本 | 读取 | 写入 |
| EnWiki | 文本 | 读取 | 写入 |
| Pile | 文本 | 读取 | 写入 |
| ADE20K | 图像分割 | 读取 | 写入 |
| CIFAR10 | 图像分类 | 读取 | 写入 |
| COCO | 图像分类 | 读取 | 写入 |
| ImageNet | 图像分类 | 读取 | 写入 |
开始训练这些数据集:
- 使用
convert目录中的相应脚本将原始数据转换为 .mds 格式。
例如:
$ python -m streaming.multimodal.convert.webvid --in <CSV 文件> --out <MDS 输出目录>
- 导入数据集类以开始训练模型。
from streaming.multimodal import StreamingInsideWebVid
dataset = StreamingInsideWebVid(local=local, remote=remote, shuffle=True)
🔑 主要特性
无缝数据混合
使用 Stream 轻松进行数据集混合实验。可以通过相对(比例)或绝对(重复或样本项)方式控制数据集采样。在流式传输过程中,不同的数据集会实时进行流式传输、打乱和混合。
# 混合 C4、GitHub 代码和内部数据集
streams = [
Stream(remote='s3://datasets/c4', proportion=0.4),
Stream(remote='s3://datasets/github', proportion=0.1),
Stream(remote='gcs://datasets/my_internal', proportion=0.5),
]
dataset = StreamingDataset(
streams=streams,
samples_per_epoch=1e8,
)
真正的确定性
我们解决方案的独特特性:无论 GPU、节点或 CPU 工作进程的数量如何,样本顺序都保持不变。这使得以下操作更加容易:
- 重现和调试训练运行和损失峰值
- 加载在 64 个 GPU 上训练的检查点,并在 8 个 GPU 上进行可重现的调试
请看下图 — 在 1、8、16、32 或 64 个 GPU 上训练模型会产生完全相同的损失曲线(在浮点数学的限制范围内!)
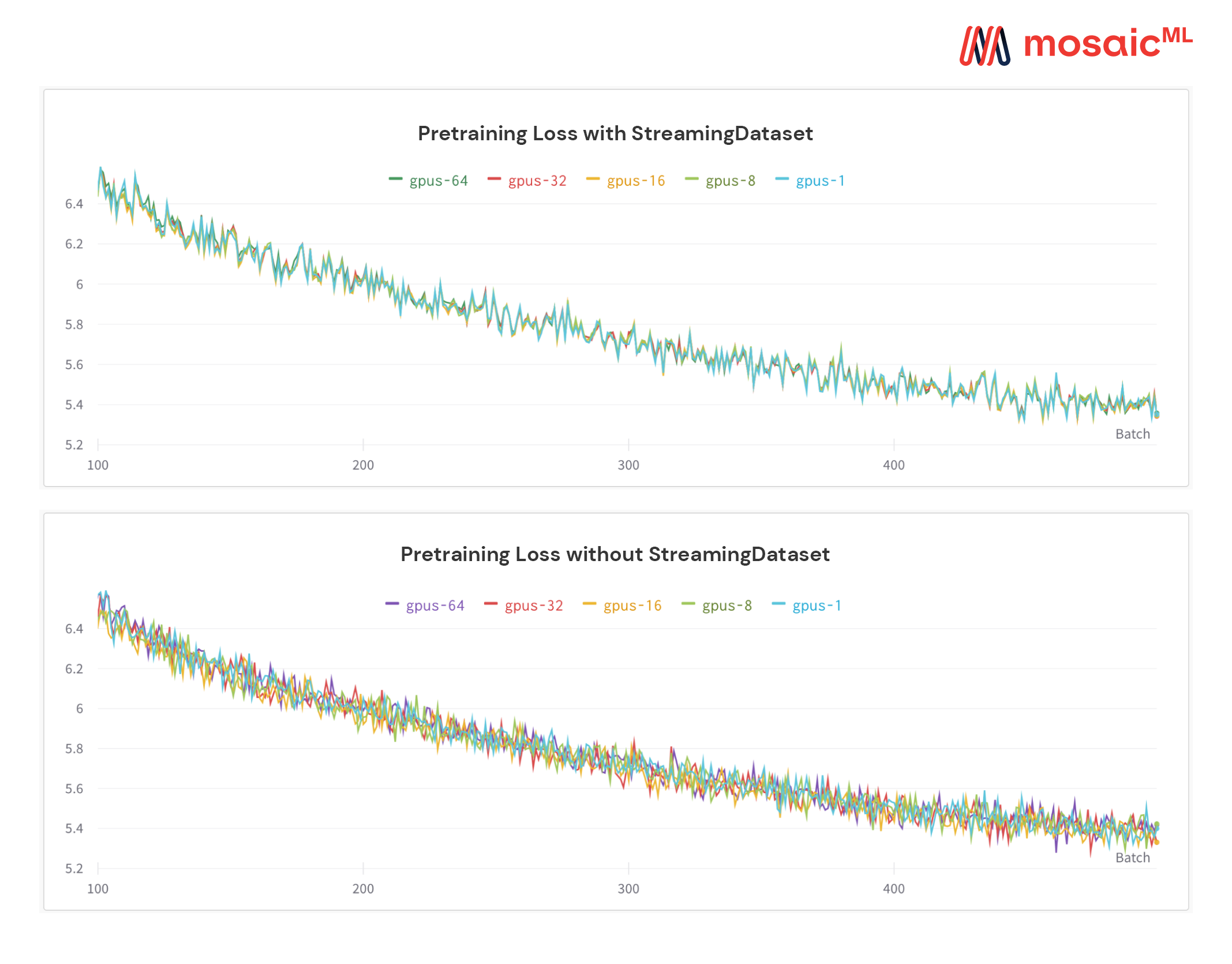
即时中期恢复
在硬件故障或损失峰值后等待数据加载器恢复可能既昂贵又令人烦恼。得益于我们的确定性样本排序,StreamingDataset 让您能够在长时间训练运行中的中期快速恢复,只需几秒钟而非几小时。 相比现有解决方案,最小化恢复延迟可以节省数千美元的出口费用和闲置 GPU 计算时间。
高吞吐量
我们的 MDS 格式将多余的工作削减到最低,与其他方案相比,在数据加载器成为瓶颈的工作负载中实现了超低的样本延迟和更高的吞吐量。
| 工具 | 吞吐量 |
|---|---|
| StreamingDataset | 约 19000 图像/秒 |
| ImageFolder | 约 18000 图像/秒 |
| WebDataset | 约 16000 图像/秒 |
结果来自 ImageNet + ResNet-50 训练,在第一个 epoch 后数据被缓存,收集了 5 次重复实验的数据。
相同的收敛性
得益于我们的随机打乱算法,使用 StreamingDataset 的模型收敛效果与使用本地磁盘一样好。
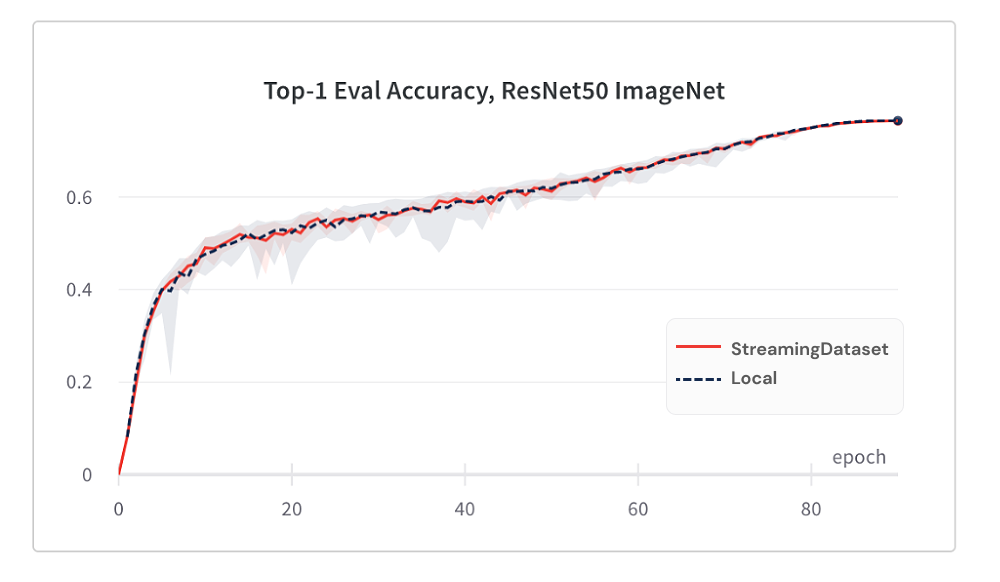
以下是 ImageNet + ResNet-50 训练的结果,收集了 5 次重复实验的数据。
| 工具 | Top-1 准确率 |
|---|---|
| StreamingDataset | 76.51% ± 0.09 |
| ImageFolder | 76.57% ± 0.10 |
| WebDataset | 76.23% ± 0.17 |
StreamingDataset 在分配给一个节点的所有样本中进行随机打乱,而其他解决方案只在更小的池(单个进程内)中打乱样本。在更大范围内打乱可以更好地分散相邻样本。此外,我们的随机打乱算法最大限度地减少了丢弃的样本。我们发现这两个随机打乱特性对模型收敛都有优势。
随机访问
在需要时访问所需的数据。
即使样本尚未下载,您也可以通过 dataset[i] 访问样本 i。下载将立即开始,结果会在完成后返回 - 类似于 PyTorch 的 map 式数据集,样本按顺序编号并可以任意顺序访问。
dataset = StreamingDataset(...)
sample = dataset[19543]
无可整除要求
StreamingDataset 可以轻松迭代任意数量的样本。您不必永久删除样本以使数据集可被固定的设备数量整除。相反,每个 epoch 会重复不同的样本选择(不丢弃任何样本),以确保每个设备处理相同数量的样本。
dataset = StreamingDataset(...)
dl = DataLoader(dataset, num_workers=...)
磁盘使用限制
动态删除最近最少使用的分片,以将磁盘使用量控制在指定限制内。通过设置 StreamingDataset 参数 cache_limit 启用此功能。详情请参阅随机打乱指南。
dataset = StreamingDataset(
cache_limit='100gb',
...
)
🏆 项目展示
以下是一些使用 StreamingDataset 的项目和实验。想要添加您的项目?请发送邮件至 mcomm@databricks.com 或加入我们的社区 Slack。
- BioMedLM:MosaicML 和 Stanford CRFM 开发的生物医学领域专用大型语言模型
- Mosaic Diffusion Models:从头训练 Stable Diffusion 的成本不到 16 万美元
- Mosaic LLMs:不到 50 万美元就能获得 GPT-3 质量
- Mosaic ResNet:使用 Mosaic ResNet 和 Composer 进行极速计算机视觉训练
- Mosaic DeepLabv3:使用 MosaicML Recipes 实现图像分割训练速度提升 5 倍
- …更多内容即将推出!敬请关注!
💫 贡献者
我们欢迎任何贡献、拉取请求或问题。
要开始贡献,请查看我们的贡献指南。
附:我们正在招聘!
如果您喜欢这个项目,请给我们一个星标 ⭐,并查看我们的其他项目:
- Composer - 一个现代化的 PyTorch 库,使可扩展、高效的神经网络训练变得简单
- MosaicML Examples - 快速高精度训练 ML 模型的参考示例 - 包括 GPT / 大型语言模型、Stable Diffusion、BERT、ResNet-50 和 DeepLabV3 的入门代码
- MosaicML Cloud - 我们的训练平台,旨在最小化 LLM、扩散模型和其他大型模型的训练成本 - 具有多云编排、轻松多节点扩展和优化训练时间的底层优化
✍️ 引用
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {\url{<https://github.com/mosaicml/streaming/>}},
}











