
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文
深度神经网络从发票文件中提取智能信息。
概要
- 易于使用的用户界面,用于查看 PDF/JPG/PNG 发票并提取信息。
- 使用训练用户界面在您的数据集上训练自定义模型。
- 根据您的方便添加或删除发票字段。
- 只需点击一下按钮即可将提取的信息保存到您的系统中。
:star: 我们感谢您的星标,这对我们有帮助!
InvoiceNet 标志由Sidhant Tibrewal设计。 查看 他的一些美丽设计作品。
免责声明:
目前没有一些通用发票字段的预训练模型,但很快就会提供。 培训 GUI 和数据准备脚本已经提供。
发票文件包含敏感信息,因此收集大量数据集一直很困难。 这使得像我们这样的开发者难以训练大规模的通用模型并将其提供给社区。
如果您有一份可以与我们共享的发票文件数据集,请联系我们 (sarthakmittal2608@gmail.com)。 我们拥有创建第一个公开可用的大规模发票数据集的工具,以及一个用于结构化信息提取的软件平台。
安装
Ubuntu 20.04
InvoiceNet 已在 Ubuntu 20.04 上开发并测试,通过 CUDA 版本: 11.8,cuDNN 版本: 8.9.7,和 Tensorflow v2.13.1。
要在 Ubuntu 上安装 InvoiceNet,请运行以下命令:
git clone https://github.com/naiveHobo/InvoiceNet.git
cd InvoiceNet/
# 运行安装脚本
./install.sh
install.sh 脚本会安装所有依赖项,创建一个虚拟环境,并在虚拟环境中安装 InvoiceNet。
要使用 InvoiceNet,您需要引入安装包的虚拟环境。
# 引入虚拟环境
source env/bin/activate
Windows 10
推荐的方法是在 Anaconda 环境中安装 InvoiceNet 及其依赖项:
git clone https://github.com/naiveHobo/InvoiceNet.git
cd InvoiceNet/
# 创建 conda 环境并激活
conda create --name invoicenet python=3.7
conda activate invoicenet
# 安装 InvoiceNet
pip install .
# 安装 poppler
conda install -c conda-forge poppler
在 Windows 10 上运行 InvoiceNet 之前,还需要单独安装一些依赖项:
数据准备
训练数据必须排列在单个目录中。发票文件应为PDF文件,并且每个发票应有一个对应的同名 JSON 标签文件。您的训练数据格式应如下:
train_data/
invoice1.pdf
invoice1.json
nike-invoice.pdf
nike-invoice.json
12345.pdf
12345.json
...
JSON 标签应具有以下格式:
{
"vendor_name":"Nike",
"invoice_date":"12-01-2017",
"invoice_number":"R0007546449",
"total_amount":"137.51",
... 其他字段
}
要开始数据准备过程,请在 GUI 中点击"Prepare Data"按钮,或按照以下说明在 CLI 中操作。
添加自定义字段
要向 InvoiceNet 添加您自己的字段,请打开 invoicenet/__init__.py。
有 4 种预定义字段类型:
- FIELD_TYPES["general"] :通用字段,如名称、地址、发票编号等。
- FIELD_TYPES["optional"] :可选字段,可能并非所有发票中都存在。
- FIELD_TYPES["amount"] :表示金额的字段。
- FIELD_TYPES["date"] :表示日期的字段。
选择该字段的适当字段类型并添加以下行。
# 在文件末尾添加以下行
# 例如,要添加字段 total_amount
FIELDS["total_amount"] = FIELD_TYPES["amount"]
# 例如,要添加字段 invoice_date
FIELDS["invoice_date"] = FIELD_TYPES["date"]
# 例如,要添加字段 tax_id(可能是可选的)
FIELDS["tax_id"] = FIELD_TYPES["optional"]
# 例如,要添加字段 vendor_name
FIELDS["vendor_name"] = FIELD_TYPES["general"]
使用 GUI
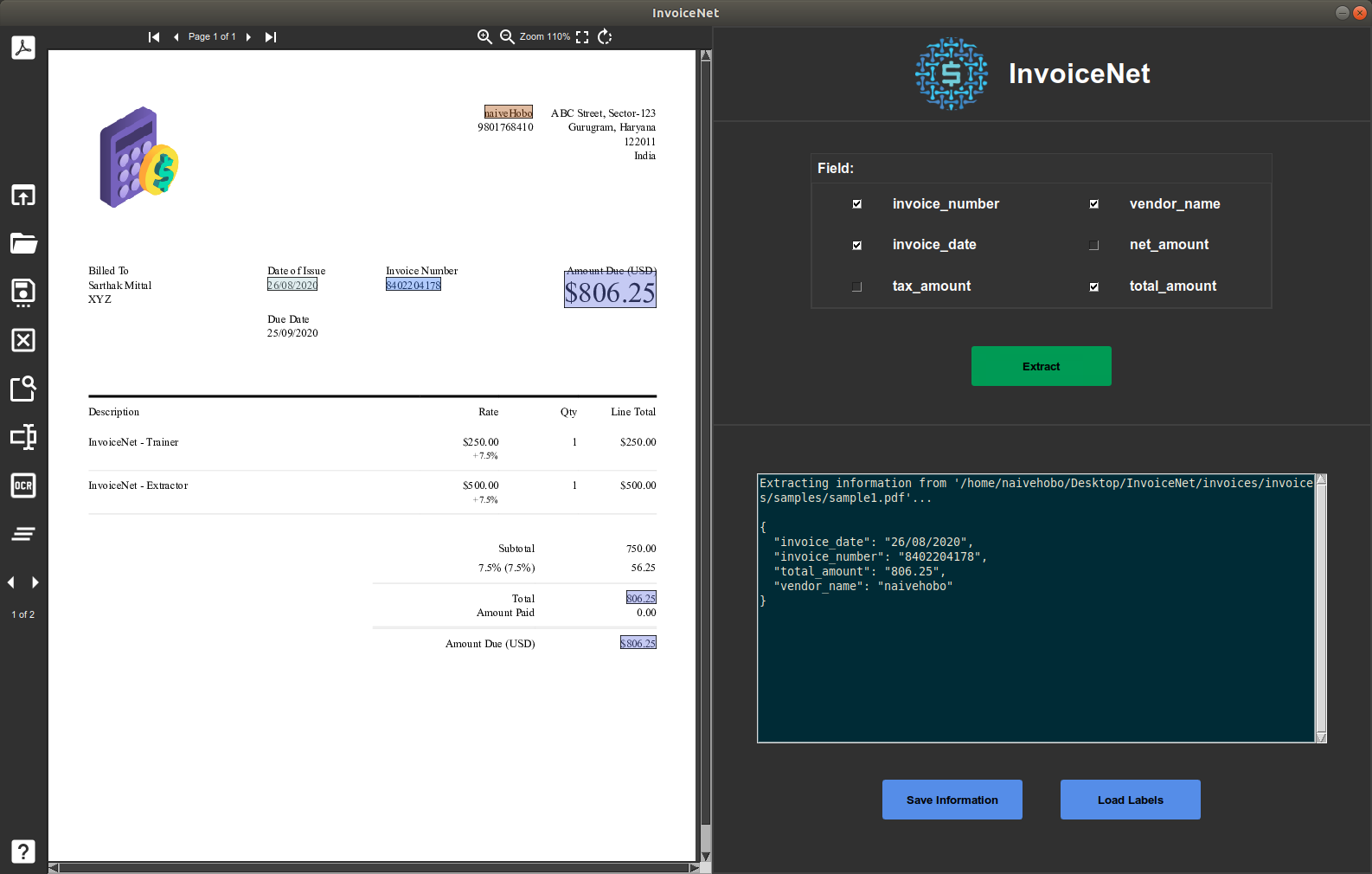
InvoiceNet 为您提供一个 GUI,用于在您的数据上训练模型并使用该训练模型从发票文件中提取信息。
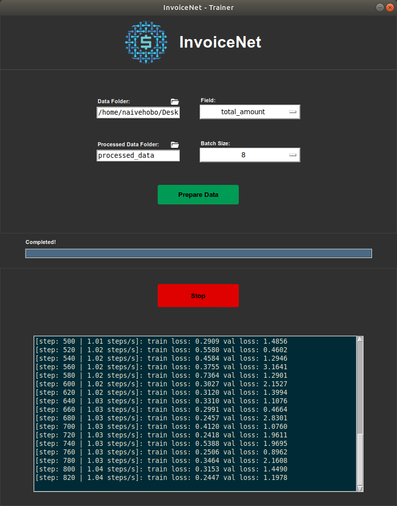
运行以下命令以运行培训 GUI:
python trainer.py
运行以下命令以运行提取器 GUI:
python extractor.py
您需要先准备训练数据。 可以通过将 Data Folder 字段设置为包含训练数据的目录并点击 Prepare Data 按钮来完成。 数据准备完成后,可以点击 Start 按钮开始训练。
使用 CLI
训练
首先通过运行以下命令准备训练数据:
python prepare_data.py --data_dir train_data/
使用以下命令训练 InvoiceNet:
python train.py --field 输入字段 --batch_size 8
# 例如,对于字段 'total_amount'
python train.py --field total_amount --batch_size 8
预测
如果您想使用不同的 ocr,请在运行 predict.py 之前更改 ocr_engine 在此函数中 create_ngrams.py
单份发票
要从单个发票文件中提取一个字段,请运行以下命令:
python predict.py --field 输入字段 --invoice 发票文件路径
# 例如,从发票文件 invoices/1.pdf 中提取字段 total_amount
python predict.py --field total_amount --invoice invoices/1.pdf
多份发票
要使用已训练的 InvoiceNet 模型提取信息,您只需将 PDF 发票文件放在一个目录中,格式如下:
predict_data/
invoice1.pdf
invoice2.pdf
...
通过以下命令运行 InvoiceNet:
python predict.py --field 输入字段 --data_dir predict_data/
# 例如,对于字段 'total_amount'
python predict.py --field total_amount --data_dir predict_data/
参考文献
此实现主要基于 R. Palm 等人的工作,如果在科学出版物中使用,应引用以下内容(或前期的会议论文):
[1] Palm, Rasmus Berg, Florian Laws, and Ole Winther. "Attend, Copy, Parse End-to-end information extraction from documents." 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019.
@inproceedings{palm2019attend,
title={Attend, Copy, Parse End-to-end information extraction from documents},
author={Palm, Rasmus Berg and Laws, Florian and Winther, Ole},
booktitle={2019 International Conference on Document Analysis and Recognition (ICDAR)},
pages={329--336},
year={2019},
organization={IEEE}
}
注意
基于论文 "Cloudscan - A configuration-free invoice analysis system using recurrent neural networks." 的一个较为劣质(也有些许缺陷)的发票处理系统的实现可在此处找到。
[2] Palm, Rasmus Berg, Ole Winther, and Florian Laws. "Cloudscan - A configuration-free invoice analysis system using recurrent neural networks." 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Vol. 1. IEEE, 2017.
@inproceedings{palm2017cloudscan,
title={Cloudscan-a configuration-free invoice analysis system using recurrent neural networks},
author={Palm, Rasmus Berg, Winther, Ole and Laws, Florian},
booktitle={2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR)},
volume={1},
pages={406--413},
year={2017},
organization={IEEE}
}











