
 Github
Github 文档
文档🦙 llama-agents 🤖
llama-agents是一个异步优先的框架,用于构建、迭代和产品化多代理系统,包括多代理通信、分布式工具执行、人机协作等功能!
在llama-agents中,每个代理被视为一个服务,不断处理传入的任务。每个代理从消息队列中拉取和发布消息。
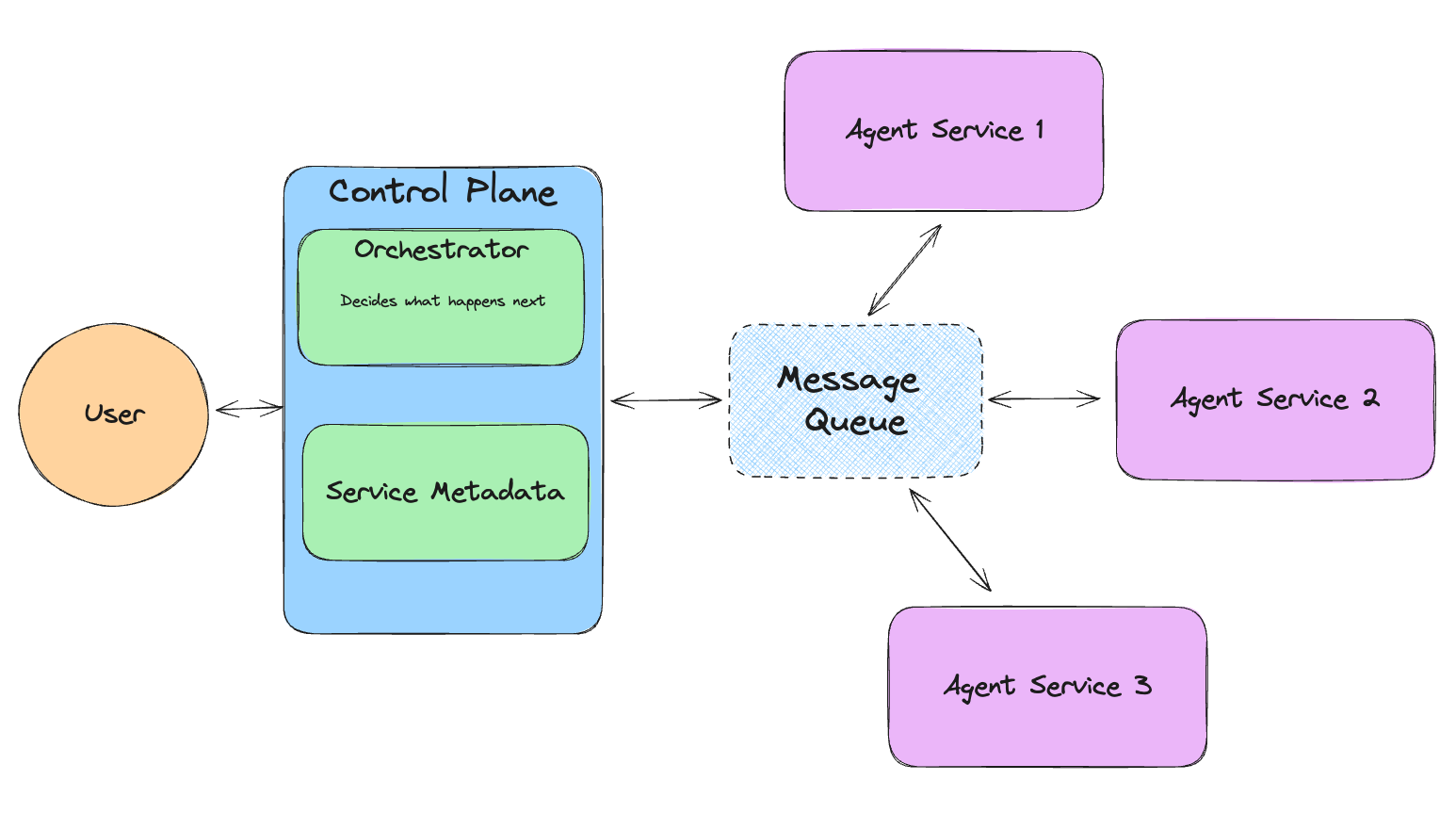
llama-agents系统的顶层是控制平面。控制平面跟踪正在进行的任务,网络中的服务,并使用编排器决定哪个服务应该处理任务的下一步。
整个系统布局如下图所示。
安装
可以使用pip安装llama-agents,主要依赖于llama-index-core:
pip install llama-agents
如果你还没有安装llama-index,要跟随这些示例,你还需要安装:
pip install llama-index-agent-openai llama-index-embeddings-openai
入门
最快的入门方式是使用现有的代理(或多个代理)并将其包装到启动器中。
下面的示例展示了一个使用llama-index中两个代理的简单例子。
首先,让我们为我们的llama-agents系统设置一些代理和初始组件:
from llama_agents import (
AgentService,
AgentOrchestrator,
ControlPlaneServer,
SimpleMessageQueue,
)
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
from llama_index.llms.openai import OpenAI
# 创建一个代理
def get_the_secret_fact() -> str:
"""返回秘密事实。"""
return "秘密事实是:小羊驼被称为'Cria'。"
tool = FunctionTool.from_defaults(fn=get_the_secret_fact)
agent1 = ReActAgent.from_tools([tool], llm=OpenAI())
agent2 = ReActAgent.from_tools([], llm=OpenAI())
# 创建我们的多代理框架组件
message_queue = SimpleMessageQueue(port=8000)
control_plane = ControlPlaneServer(
message_queue=message_queue,
orchestrator=AgentOrchestrator(llm=OpenAI(model="gpt-4-turbo")),
port=8001,
)
agent_server_1 = AgentService(
agent=agent1,
message_queue=message_queue,
description="用于获取秘密事实。",
service_name="secret_fact_agent",
port=8002,
)
agent_server_2 = AgentService(
agent=agent2,
message_queue=message_queue,
description="用于获取随机无聊事实。",
service_name="dumb_fact_agent",
port=8003,
)
本地/笔记本流程
接下来,在笔记本中工作或为了更快的迭代,我们可以在单次运行设置中启动我们的llama-agents系统,其中一条消息会在网络中传播并返回。
from llama_agents import LocalLauncher
import nest_asyncio
# 在笔记本中运行时需要
nest_asyncio.apply()
# 启动它
launcher = LocalLauncher(
[agent_server_1, agent_server_2],
control_plane,
message_queue,
)
result = launcher.launch_single("什么是秘密事实?")
print(f"结果:{result}")
[!注意]
launcher.launch_single创建了一个新的asyncio事件循环。由于Jupyter笔记本已经有一个运行中的事件循环,我们需要使用nest_asyncio来允许在现有循环中创建新的事件循环。
与任何代理系统一样,考虑你使用的LLM的可靠性很重要。通常,支持函数调用的API(OpenAI、Anthropic、Mistral等)是最可靠的。
服务器流程
一旦你对你的系统满意,我们可以将所有服务作为独立进程启动,从而实现更高的吞吐量和可扩展性。
默认情况下,所有任务结果都发布到特定的"human"队列,所以我们还定义了一个消费者来处理这个结果。(未来,这个最终队列将是可配置的!)
要测试这个,你可以在脚本中使用服务器启动器:
from llama_agents import ServerLauncher, CallableMessageConsumer
# 额外的人类消费者
def handle_result(message) -> None:
print(f"获得结果:", message.data)
human_consumer = CallableMessageConsumer(
handler=handle_result, message_type="human"
)
# 定义启动器
launcher = ServerLauncher(
[agent_server_1, agent_server_2],
control_plane,
message_queue,
additional_consumers=[human_consumer],
)
# 启动它!
launcher.launch_servers()
现在,由于一切都是服务器,你需要API请求来与之交互。最简单的方法是使用我们的客户端和控制平面URL:
from llama_agents import LlamaAgentsClient, AsyncLlamaAgentsClient
client = LlamaAgentsClient("<控制平面URL>") # 例如 http://127.0.0.1:8001
task_id = client.create_task("什么是秘密事实?")
# <等待几秒钟>
# 返回TaskResult或如果未完成则返回None
result = client.get_task_result(task_id)
除了使用客户端或原始curl请求,你还可以使用内置的CLI工具来监控和与你的服务交互。
在另一个终端中,你可以运行:
llama-agents monitor --control-plane-url http://127.0.0.1:8001
示例
你可以在我们的示例文件夹中找到大量示例:
- Agentic RAG + 工具服务
- 使用本地启动器的Agentic协调器
- 使用服务器启动器的Agentic协调器
- 带人工干预的Agentic协调器
- 使用工具服务的Agentic协调器
- 使用本地启动器的管道协调器
- 带人工干预的管道协调器
- 使用代理服务器作为工具的管道协调器
- 使用查询重写RAG的管道协调器
llama-agents系统的组成部分
在llama-agents中,有几个关键组件构成了整个系统
消息队列-- 消息队列作为所有服务和控制平面的队列。它有向指定队列发布方法的方法,并将消息委派给消费者。控制平面-- 控制平面是llama-agents系统的中央网关。它跟踪当前任务以及注册到系统的服务。它还包含协调器。协调器-- 该模块处理传入的任务并决定将其发送到哪个服务,以及如何处理来自服务的结果。协调器可以是代理式的(由LLM做出决策),显式的(由查询管道定义流程),两者的混合,或完全自定义的。服务-- 服务是实际工作发生的地方。服务接受一些传入的任务和上下文,处理它,并发布结果。工具服务是一种特殊的服务,用于分担代理工具的计算。代理可以配备一个元工具来调用工具服务。
llama-agents中的低级API
到目前为止,你已经看到了如何定义组件以及如何启动它们。然而,在大多数生产用例中,你需要手动启动服务,以及定义自己的消费者!
所以,这里是一个关于这方面的快速指南!
启动
首先,你需要启动所有内容。这可以在单个脚本中完成,或者你可以使用多个脚本分别启动每个服务,或在不同的机器上启动,甚至在docker镜像中启动。
在这个例子中,我们假设从单个脚本启动。
import asyncio
# 启动消息队列
queue_task = asyncio.create_task(message_queue.launch_server())
# 等待消息队列准备就绪
await asyncio.sleep(1)
# 启动控制平面
control_plane_task = asyncio.create_task(self.control_plane.launch_server())
# 等待控制平面准备就绪
await asyncio.sleep(1)
# 将控制平面注册为消费者,返回一个start_consuming_callable
start_consuming_callable = await self.control_plane.register_to_message_queue()
start_consuming_callables = [start_consuming_callable]
# 注册服务
control_plane_url = (
f"http://{self.control_plane.host}:{self.control_plane.port}"
)
service_tasks = []
for service in self.services:
# 首先启动服务
service_tasks.append(asyncio.create_task(service.launch_server()))
# 将服务注册到消息队列
start_consuming_callable = await service.register_to_message_queue()
start_consuming_callables.append(start_consuming_callable)
# 将服务注册到控制平面
await service.register_to_control_plane(control_plane_url)
# 开始消费!
start_consuming_tasks = []
for start_consuming_callable in start_consuming_callables:
task = asyncio.create_task(start_consuming_callable())
start_consuming_tasks.append(task)
完成后,你可能想为任务结果定义一个消费者。
默认情况下,任务的结果会发布到human消息队列。
from llama_agents import (
CallableMessageConsumer,
RemoteMessageConsumer,
QueueMessage,
)
import asyncio
def handle_result(message: QueueMessage) -> None:
print(message.data)
human_consumer = CallableMessageConsumer(
handler=handle_result, message_type="human"
)
async def register_and_start_consuming():
start_consuming_callable = await message_queue.register_consumer(
human_consumer
)
await start_consuming_callable()
if __name__ == "__main__":
asyncio.run(register_and_start_consuming())
# 或者,你可以将消息发送到任何URL
# human_consumer = RemoteMessageConsumer(url="某个目标url")
# message_queue.register_consumer(human_consumer)
或者,如果你不想定义消费者,你可以直接使用monitor来观察你的系统结果
llama-agents monitor --control-plane-url http://127.0.0.1:8001











