
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文LoraHub:通过动态LoRA组合实现高效跨任务泛化
这是我们论文LoraHub:通过动态LoRA组合实现高效跨任务泛化的官方代码仓库,包含代码和预训练模型。
🔥 最新动态
- [2024-7-18]:我们的论文被COLM 2024接收!
- [2023-9-13]:现在可以通过
pip install lorahub轻松安装。有关接口使用说明,请参阅example.py文件 - [2023-8-29]:我们发布了完整的复现代码reproduce_bbh.py。请查看该脚本以复现我们的结果!
- [2023-8-03]:已集成到Replicate,查看演示!
- [2023-7-27]:我们发布了代码和演示。快来体验吧!
- [2023-7-26]:我们发布了论文。
🏴 概述
低秩适应(LoRA)是一种在新任务上微调大型语言模型的技术。我们提出了LoraHub,一个允许组合多个在不同任务上训练的LoRA模块的框架。目标是仅使用少量示例就能在未见任务上取得良好性能,无需额外参数或训练。我们希望建立一个市场,用户可以在其中共享他们训练好的LoRA模块,从而促进这些模块在新任务中的应用。

该图展示了零样本学习、少样本上下文学习和少样本lorahub学习(我们的方法)。请注意,组合过程是针对每个任务而非每个示例进行的。我们的方法实现了与零样本学习相似的推理吞吐量,同时在BIG-Bench Hard (BBH)基准测试上接近上下文学习的性能。实验结果显示,在少样本场景下,我们的方法相比零样本学习具有更高的效率,同时与上下文学习(ICL)的性能相近。
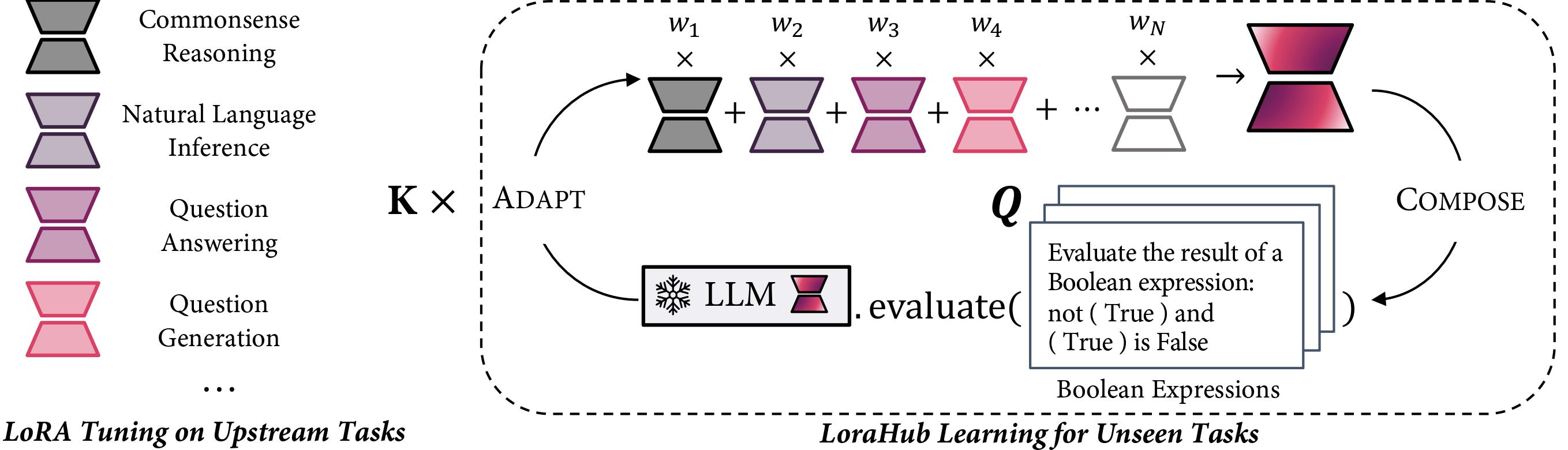
该图展示了LoraHub学习的流程。我们的方法包括两个阶段:组合阶段和适应阶段。在组合阶段,现有的LoRA模块被整合成一个统一的模块,使用一组权重(表示为w)作为系数。在适应阶段,合并后的LoRA模块在未见任务的少量示例上进行评估。随后,应用无梯度算法来优化w。经过K次迭代后,产生一个高度适应的LoRA模块,可与LLM结合以执行目标任务。
⚡️ 快速开始
你可以使用以下命令安装lorahub:
pip install lorahub
然后你可以通过简单调用lorahub_learning函数来使用lorahub学习:
from lorahub.algorithm import lorahub_learning, lorahub_inference
from lorahub.constant import LORA_MODULE_NAMES
import random
def get_examples_for_learning():
"""
获取一些示例来学习组合给定的LoRA模块
"""
return [
{"input":
"从上下文推断日期。\n\nQ: Jane正在庆祝2012年1月的最后一天。明天的日期是多少(格式为MM/DD/YYYY)?\n选项:\n(A) 02/02/2012\n(B) 02/15/2012\n(C) 01/25/2012\n(D) 04/22/2012\n(E) 02/01/2012\n(F) 02/11/2012\nA:", "output": "(E)"}
]
def get_lora_module_list():
"""
你可以有自定义的筛选策略来选择用于组合的模块。这里我们随机选择20个模块。
"""
random.seed(42)
return random.sample(LORA_MODULE_NAMES, 20)
# 获取要用于组合的模块列表
modules = get_lora_module_list()
print("modules:", modules)
# 构建输入列表和输出列表
example_inputs, examples_outputs = [], []
for example in get_examples_for_learning():
example_inputs.append(example["input"])
examples_outputs.append(example["output"])
# 执行LoRAHub学习
module_weights, model, tokenizer = lorahub_learning(lora_module_list=modules,
example_inputs=example_inputs,
example_outputs=examples_outputs,
max_inference_step=40,
batch_size=1)
print("module_weights:", module_weights)
lorahub_learning函数的接口设计如下:
lorahub_learning(lora_module_list: List[str], # LoRA候选模块列表
example_inputs: List[str],
example_outputs: List[str],
max_inference_step: int,
model_name_or_path=None, # 如果未给出,我们将使用LoRA配置中的model_name_or_path
batch_size=None,
get_loss=default_get_loss, # 获取优化目标的函数,默认使用损失(可以更改为准确率或相似度等)
get_regular=default_l1_regularization, # 获取权重正则化项的函数,默认使用0.05*|w_i|
seed=42)
完整示例可以在example.py中找到。
🌲 项目结构
lorahub源代码的组织结构如下:
|-- lorahub
-- algorithm.py # lorahub学习和推理的主要代码
-- constant.py # LoRA候选模块名称
|-- example.py # 用于演示目的的使用代码
🏰 资源
LoRA候选
我们的方法需要一系列在先前任务上训练的LoRA模块。为了与Flan保持一致,我们采用了用于指导Flan-T5的任务,通过以下命令整合了近196个不同的任务及其相应的指令:
git clone https://huggingface.co/datasets/lorahub/flanv2
随后,我们创建了几个LoRA模块作为可能的候选。这些LoRA模块可以在https://huggingface.co/models?search=lorahub 上访问。
💬 引用
如果我们的工作对你有用,请考虑引用我们的论文:
@misc{huang2023lorahub,
title={LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition},
author={Chengsong Huang and Qian Liu and Bill Yuchen Lin and Tianyu Pang and Chao Du and Min Lin},
year={2023},
eprint={2307.13269},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











