
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文
ProPainter: 改进视频修复的传播和Transformer


⭐ 如果ProPainter对您的项目有帮助,请给这个仓库点个星。谢谢!🤗
:open_book: 更多视觉效果,请查看我们的项目主页
更新
- 2023.11.09: 已整合到 :man_artist: OpenXLab。尝试在线演示!
- 2023.11.09: 已整合到 :hugs: Hugging Face。尝试在线演示!
- 2023.09.24: 我们正式移除了水印去除演示,以防止我们的工作被不当用于非道德目的。
- 2023.09.21: 增加了内存高效推理功能。查看我们的GPU内存需求。🚀
- 2023.09.07: 我们的代码和模型已公开可用。🐳
- 2023.09.01: 创建此仓库。
待办事项
- 制作Colab演示。
-
制作交互式Gradio演示。 -
更新内存高效推理功能。
结果
👨🏻🎨 物体移除

|

|
🎨 视频补全

|

|

|

|
概述
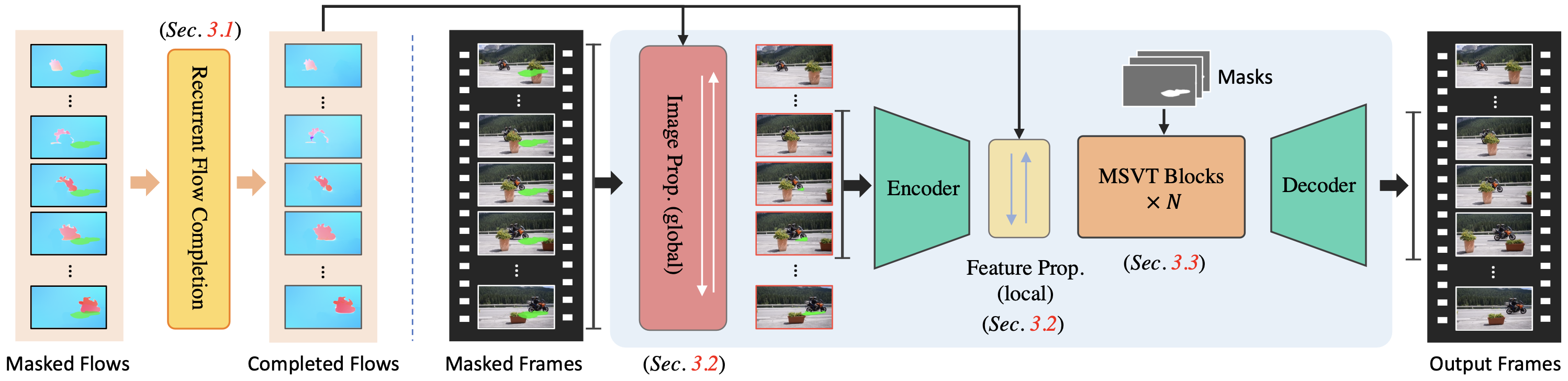
依赖和安装
-
克隆仓库
git clone https://github.com/sczhou/ProPainter.git -
创建Conda环境并安装依赖
# 创建新的anaconda环境 conda create -n propainter python=3.8 -y conda activate propainter # 安装Python依赖 pip3 install -r requirements.txt- CUDA >= 9.2
- PyTorch >= 1.7.1
- Torchvision >= 0.8.2
- 其他所需包在
requirements.txt中
开始使用
准备预训练模型
从Releases V0.1.0下载我们的预训练模型到weights文件夹。(所有预训练模型也可以在首次推理时自动下载。)
目录结构将安排如下:
weights
|- ProPainter.pth
|- recurrent_flow_completion.pth
|- raft-things.pth
|- i3d_rgb_imagenet.pt (用于评估VFID指标)
|- README.md
🏂 快速测试
我们在inputs文件夹中提供了一些示例。
运行以下命令来尝试:
# 第一个示例(物体移除)
python inference_propainter.py --video inputs/object_removal/bmx-trees --mask inputs/object_removal/bmx-trees_mask
# 第二个示例(视频补全)
python inference_propainter.py --video inputs/video_completion/running_car.mp4 --mask inputs/video_completion/mask_square.png --height 240 --width 432
结果将保存在results文件夹中。
要测试您自己的视频,请准备输入的mp4视频(或拆分帧)和逐帧掩码。
如果您想指定处理的视频分辨率或避免内存不足,可以设置--width和--height的视频大小:
# 处理576x320的视频;设置--fp16以在推理时使用fp16(半精度)。
python inference_propainter.py --video inputs/video_completion/running_car.mp4 --mask inputs/video_completion/mask_square.png --height 320 --width 576 --fp16
🚀 内存高效推理
视频修复通常需要大量的GPU内存。在这里,我们提供了各种功能,有助于内存高效推理,有效避免内存不足(OOM)错误。您可以使用以下选项进一步减少内存使用:
- 通过减少
--neighbor_length(默认10)来减少局部邻居的数量。 - 通过增加
--ref_stride(默认10)来减少全局参考的数量。 - 设置
--resize_ratio(默认1.0)来调整处理视频的大小。 - 通过指定
--width和--height来设置较小的视频尺寸。 - 设置
--fp16在推理时使用fp16(半精度)。 - 减少子视频的帧数
--subvideo_length(默认80),这有效地解耦了GPU内存成本和视频长度。
以下显示了不同子视频长度使用fp32/fp16精度的估计GPU内存需求:
| 分辨率 | 50 帧 | 80 帧 |
|---|---|---|
| 1280 x 720 | 28G / 19G | OOM / 25G |
| 720 x 480 | 11G / 7G | 13G / 8G |
| 640 x 480 | 10G / 6G | 12G / 7G |
| 320 x 240 | 3G / 2G | 4G / 3G |
数据集准备
| 数据集 | YouTube-VOS | DAVIS |
|---|---|---|
| 描述 | 用于训练 (3,471) 和评估 (508) | 用于评估 (90中的50个) |
| 图像 | [官方链接] (下载训练和测试的所有帧) | [官方链接] (2017, 480p, TrainVal) |
| 掩码 | [Google Drive] [百度网盘] (用于复现论文结果;由ProPainter论文提供) | |
训练和测试的分割文件位于datasets/<dataset_name>中。对于每个数据集,你应该将JPEGImages放置在datasets/<dataset_name>中。将所有视频帧调整为432x240大小用于训练。解压下载的掩码文件到datasets目录。
datasets目录结构将如下排列:(注意:请仔细检查)
datasets
|- davis
|- JPEGImages_432_240
|- <video_name>
|- 00000.jpg
|- 00001.jpg
|- test_masks
|- <video_name>
|- 00000.png
|- 00001.png
|- train.json
|- test.json
|- youtube-vos
|- JPEGImages_432_240
|- <video_name>
|- 00000.jpg
|- 00001.jpg
|- test_masks
|- <video_name>
|- 00000.png
|- 00001.png
|- train.json
|- test.json
训练
我们的训练配置在train_flowcomp.json(用于循环流补全网络)和train_propainter.json(用于ProPainter)中提供。
运行以下命令之一进行训练:
# 训练循环流补全网络
python train.py -c configs/train_flowcomp.json
# 训练ProPainter
python train.py -c configs/train_propainter.json
你可以运行相同的命令来恢复你的训练。
为了加速训练过程,你可以使用以下命令预先计算训练数据集的光流:
# 计算训练数据集的光流
python scripts/compute_flow.py --root_path <dataset_root> --save_path <save_flow_root> --height 240 --width 432
评估
运行以下命令之一进行评估:
# 评估流补全模型
python scripts/evaluate_flow_completion.py --dataset <dataset_name> --video_root <video_root> --mask_root <mask_root> --save_results
# 评估ProPainter模型
python scripts/evaluate_propainter.py --dataset <dataset_name> --video_root <video_root> --mask_root <mask_root> --save_results
分数和结果也将保存在results_eval文件夹中。
请使用--save_results以便进一步评估时间扭曲误差。
引用
如果你发现我们的仓库对你的研究有用,请考虑引用我们的论文:
@inproceedings{zhou2023propainter,
title={{ProPainter}: Improving Propagation and Transformer for Video Inpainting},
author={Zhou, Shangchen and Li, Chongyi and Chan, Kelvin C.K and Loy, Chen Change},
booktitle={Proceedings of IEEE International Conference on Computer Vision (ICCV)},
year={2023}
}
许可证
本项目采用NTU S-Lab许可证1.0授权。重新分发和使用应遵循此许可证。
联系方式
如果你有任何问题,请随时通过shangchenzhou@gmail.com与我联系。
致谢
本代码基于E2FGVI和STTN。部分代码来自BasicVSR++。感谢他们出色的工作。
特别感谢Yihang Luo为ProPainter构建和维护Gradio演示做出的宝贵贡献。











