
 访问官网
访问官网 Github
Github自然语言处理进展追踪
目录
英语
- 自动语音识别
- 组合范畴语法
- 常识推理
- 句法分析
- 指代消解
- 数据到文本生成
- 依存句法分析
- 对话系统
- 领域适应
- 实体链接
- 语法纠错
- 信息抽取
- 意图检测和槽位填充
- 关键词抽取与生成
- 语言建模
- 词形规范化
- 机器翻译
- 缺失元素
- 多任务学习
- 多模态
- 命名实体识别
- 自然语言推理
- 词性标注
- 释义生成
- 问答系统
- 关系预测
- 关系抽取
- 语义文本相似度
- 语义解析
- 语义角色标注
- 情感分析
- 浅层句法分析
- 文本简化
- 立场检测
- 文本摘要
- 分类学习
- 时间处理
- 文本分类
- 词义消歧
越南语
印地语
中文
更多中文任务、数据集和结果,请查看中文自然语言处理网站。
法语
俄语
西班牙语
葡萄牙语
韩语
尼泊尔语
孟加拉语
波斯语
土耳其语
德语
阿拉伯语
本文档旨在追踪自然语言处理(NLP)的进展,并概述最常见NLP任务及其相应数据集的最新技术水平(SOTA)。
它旨在涵盖传统和核心的NLP任务,如依存句法分析和词性标注,以及较新的任务,如阅读理解和自然语言推理。主要目标是为读者提供基准数据集和感兴趣任务最新技术水平的快速概览,作为进一步研究的起点。为此,如果已有公开发布并定期维护某项任务结果的地方,如公共排行榜,将为读者指明方向。
如果您想在未来再次找到此文档,只需在浏览器中访问nlpprogress.com或nlpsota.com。
贡献
指南
结果 优先选择已发表论文中报告的结果;对有影响力的预印本可以例外。
数据集 数据集应至少在一篇已发表的论文中用于评估,而不仅仅是介绍该数据集的论文。
代码 我们建议添加实现链接(如果有)。如果表格中没有"代码"列,您可以添加一个(见下文)。 在"代码"列中,用官方表示官方实现。 如果有非官方实现,使用链接(见下文)。 如果没有可用的实现,可以将单元格留空。
添加新结果
如果您想添加新结果,只需点击相应任务文件右上角的小编辑按钮(见下图)。

这允许您以Markdown格式编辑文件。只需按相同格式向相应表格添加一行。确保表格保持排序(最佳结果在顶部)。 做出更改后,请点击页面顶部的"预览更改"标签,确保表格仍然看起来正常。如果一切看起来都不错,请转到页面底部,您会看到下面的表单。
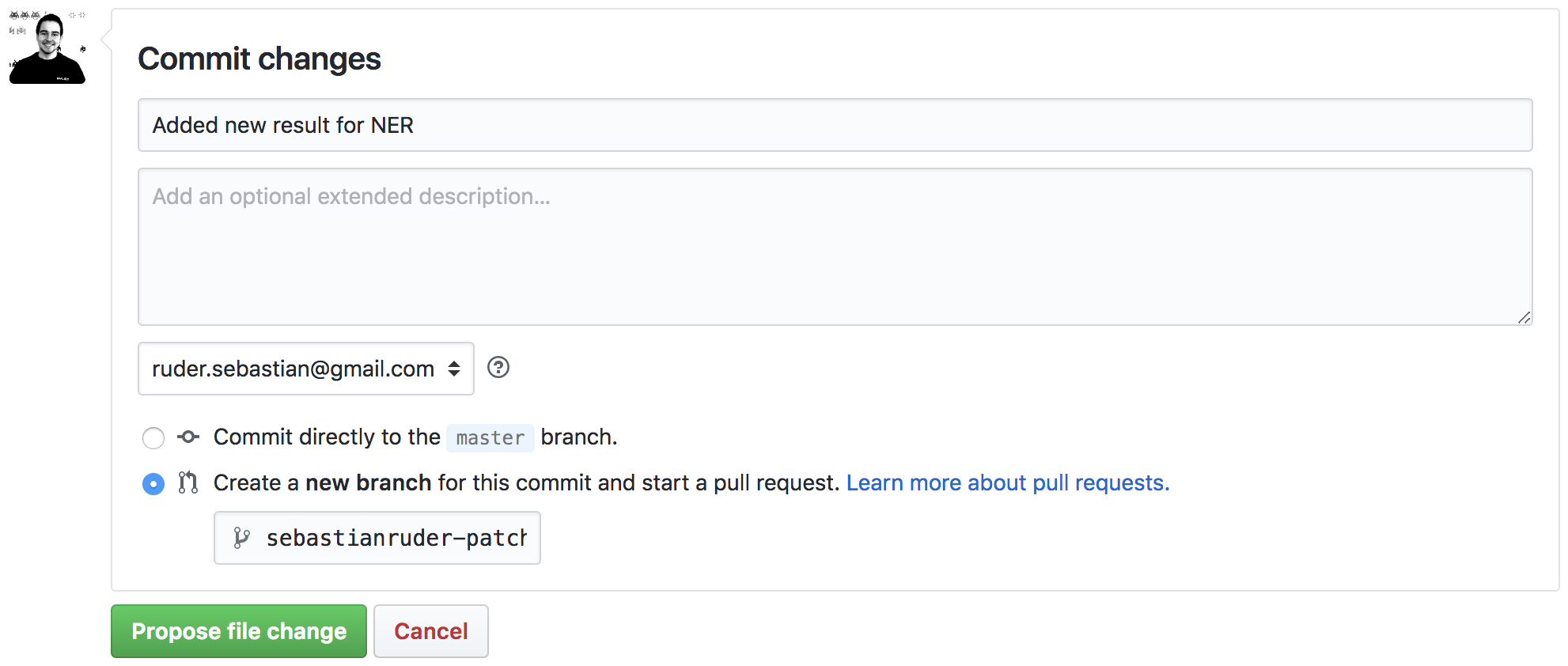
为您提议的更改添加一个名称,一个可选的描述,表明您希望"为此提交创建一个新分支并开始拉取请求",然后点击"提议文件更改"。
添加新数据集或任务
要添加新数据集或任务,您也可以按照上述步骤操作。或者,您可以fork仓库。 无论哪种情况,都请遵循以下步骤:
- 如果您的任务是全新的,创建一个新文件并在上面的目录中链接到它。
- 如果不是,将您的任务或数据集添加到相应文件的各个部分(按字母顺序)。
- 简要描述数据集/任务并包括相关参考文献。
- 描述评估设置和评估指标。
- 展示数据集/任务的注释示例。
- 如果可用,添加下载链接。
- 复制下面的表格,并至少填写两个结果(包括最新技术水平) 用于您的数据集/任务(将得分更改为您数据集的指标)。如果您的数据集/任务 有多个指标,请将它们添加到"得分"的右侧。
- 将您的更改作为拉取请求提交。
| 模型 | 得分 | 论文 / 来源 | 代码 |
|---|---|---|---|
愿望清单
这些是仍然缺失的任务和数据集:
- 双语词典归纳
- 话语分析
- 关键短语抽取
- 知识库填充(KBP)
- 更多对话任务
- 半监督学习
- 框架语义分析(FrameNet全句分析)
导出为结构化格式
您可以将所有数据提取到结构化的、机器可读的JSON格式,其中包含解析后的任务、描述和SOTA表格。
说明在structured/README.md中。
本地构建网站的说明
使用Jekyll在本地构建网站的说明可以在这里找到。











