
 Github
Github Huggingface
Huggingface 论文
论文黑盒提示优化(BPO)
无需模型训练的大型语言模型对齐方法(ACL 2024)
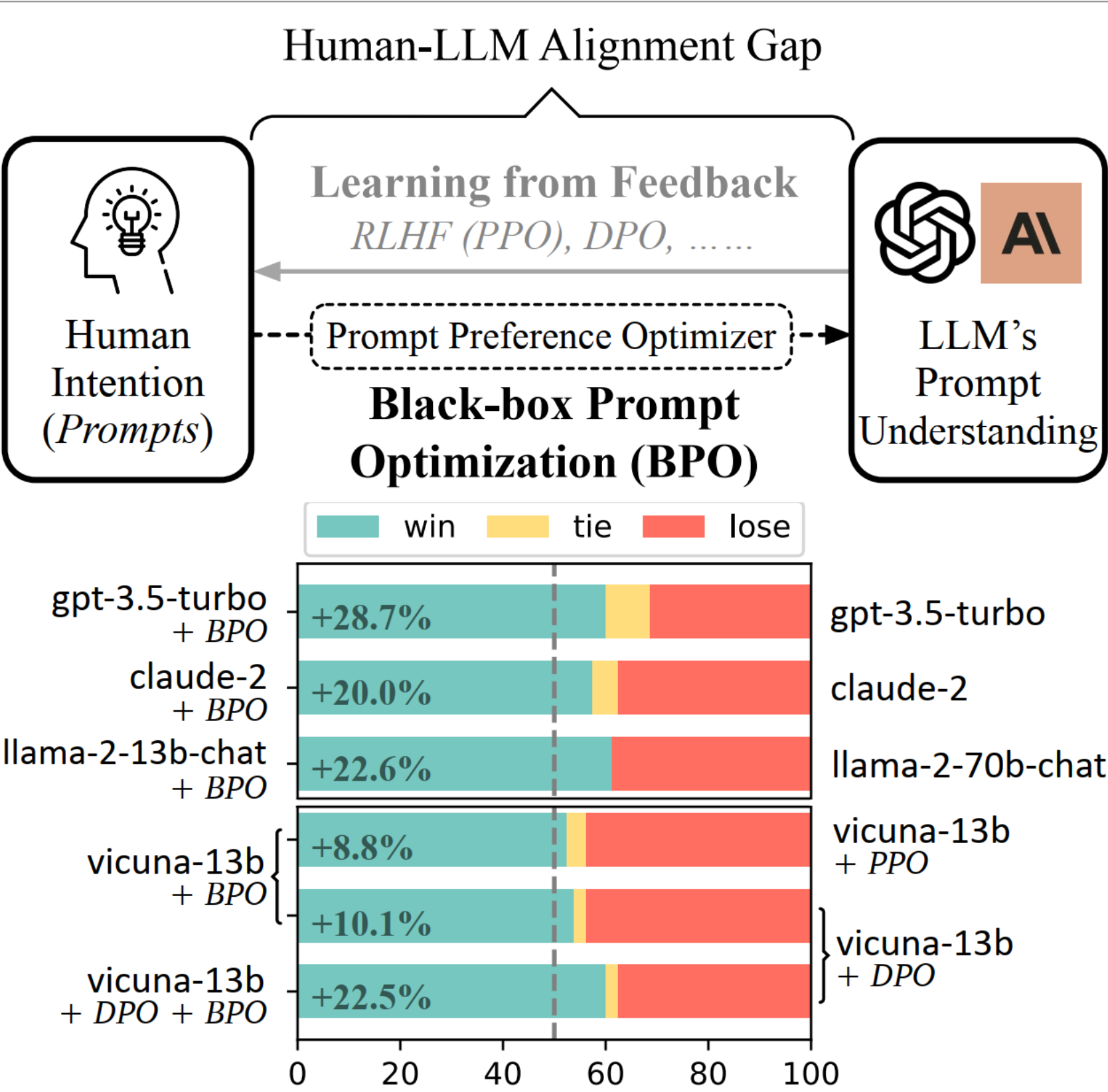
(上图)黑盒提示优化(BPO)提供了一个全新的概念视角来弥合人类和大型语言模型之间的差距。(下图)在Vicuna Eval的成对评估中,我们展示了BPO在不进行训练的情况下进一步对齐了gpt-3.5-turbo和claude-2。它还优于PPO和DPO,并呈现出正交的改进。
更新
我们在Hugging Face上为BPO构建了一个演示。
目录
模型
提示偏好优化模型可从Hugging Face下载
推理代码(请参考src/infer_example.py获取有关如何优化提示的更多说明):
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = 'THUDM/BPO'
prompt_template = "[INST] 你是一位专业的提示工程师。请帮我改进这个提示,以获得更有帮助且无害的回答:\n{} [/INST]"
device = 'cuda:0'
model = AutoModelForCausalLM.from_pretrained(model_path).half().eval().to(device)
# 对于8位量化
# model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device, load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained(model_path)
text = '告诉我关于哈利·波特的信息'
prompt = prompt_template.format(text)
model_inputs = tokenizer(prompt, return_tensors="pt").to(device)
output = model.generate(**model_inputs, max_new_tokens=1024, do_sample=True, top_p=0.9, temperature=0.6, num_beams=1)
resp = tokenizer.decode(output[0], skip_special_tokens=True).split('[/INST]')[1].strip()
print(resp)
数据
BPO数据集
BPO数据集可在Hugging Face上找到。
BPO用于SFT数据构建
alpaca_reproduce目录包含BPO重新生成的Alpaca数据集。数据格式为:
{
"instruction": {instruction},
"input": {input},
"output": {output},
"optimized_prompt": {optimized_prompt},
"res": {res}
}
- {instruction}、{input}和{output}是原始数据集中的元素。
- {optimized_prompt}是BPO优化后的指令。
- {res}是使用{optimized_prompt}从text-davinci-003获得的响应。
测试集
testset目录包含我们使用的所有测试数据集,包括:
- 从BPO数据集中抽样的200个提示
- 来自Dolly数据集的200个示例
- 来自Self-Instruct的252个人工评估指令
- 来自Vicuna Eval数据集的80个面向用户的提示。
快速入门
对于所有代码,我们已添加了#TODO注释以指示运行前需要修改的代码部分。请在执行每个文件之前更新相关部分。
设置
pip install -r requirements.txt
数据构建
要自行构建数据,请运行以下命令
cd src/data_construction
# 使用成对反馈数据生成优化的提示
python chatgpt_infer.py
# 处理生成的优化提示
python process_optimized_prompts.py
模型训练
如果你想训练自己的提示偏好优化器, 请运行以下命令:
cd src/training
# 预处理微调数据
python ../data_construction/process_en.py
python data_utils.py
# 微调
python train.py
# 推理
python infer_finetuning.py
推理
我们展示了一个示例代码,用于使用llama2-chat在BPO优化的提示上进行生成。
评估
如果你想比较BPO对齐模型与原始模型,请参考以下代码:
cd src/evaluation
# 以dolly_eval上的gpt4评估为例
python gpt4_score.py --input_file_a "BPO对齐模型的生成结果路径" \
--input_file_b "原始模型的生成结果路径" \
--task_name "dolly_eval" \ # 对于其他测试集,可更改为"self_instruct"、"test_set"或"vicuna_eval"
--output_file "输出路径"
# 计算胜率
python cal_gpt4_score.py --input_file "输出路径"
致谢
- 微调代码:llm_finetuning
- PPO代码:DeepSpeed-Chat
- DPO代码:LLaMA-Factory
- 评估提示:llm_judge和alpaca_eval
引用
@article{cheng2023black,
title={Black-Box Prompt Optimization: Aligning Large Language Models without Model Training},
author={Cheng, Jiale and Liu, Xiao and Zheng, Kehan and Ke, Pei and Wang, Hongning and Dong, Yuxiao and Tang, Jie and Huang, Minlie},
journal={arXiv preprint arXiv:2311.04155},
year={2023}
}











