
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文视而不见?探索多模态大语言模型的视觉缺陷
Shengbang Tong、Zhuang Liu、Yuexiang Zhai、Yi Ma、Yann LeCun、Saining Xie
论文 | 项目主页 | MMVP 基准测试

目录:
入门
安装
conda create -n mmvp python=3.10 -y
conda activate mmvp
cd LLaVA
pip install -e .
pip install flash-attn --no-build-isolation
预训练模型
交错式MoF模型(基于LLaVA-1.5 13b)可以在这里找到。
基准测试
MMVP 基准测试
我们的MMVP基准测试可在这里获取。它专门设计用于通过视觉问答来衡量多模态大语言模型的视觉能力。 该基准测试分为一个包含所有300张测试图像的文件夹和一个带有问题和正确答案的注释csv文件。数据格式如下:
├── MMVP Images
│ ├── 1.jpg
│ ├── 2.jpg
│ ├── 3.jpg
│ ├── ...
│ └── 300.jpg
└── Questions.csv
MMVP VLM 基准测试
我们的MMVP-VLM基准测试可在这里获取。它从上面的MMVP基准测试中提炼而来,并简化了每张图像的语言描述。它旨在评估像CLIP这样的视觉语言模型的视觉能力。该基准测试分为9种不同的视觉模式。在每种视觉模式中,有15对零样本问题。一个注释csv文件包含问题、相应的视觉模式和图像。 数据格式如下:
├── MMVP_VLM_Images
│ ├── Orientation
│ │ ├── 1.jpg
│ │ ├── 2.jpg
│ │ ├── ...
│ │ └── 30.jpg
│ ├── Presence
│ │ ├── 31.jpg
│ │ ├── 32.jpg
│ │ ├── ...
│ │ └── 60.jpg
│ ├── ...
│ └── Camera_Perspective
│ ├── 241.jpg
│ ├── 242.jpg
│ ├── ...
│ └── 270.jpg
└── Questions.csv
评估
要在MMVP上进行评估,请运行
python scripts/evaluate_mllm.py --directory MMVP基准测试文件夹路径 --model-path 待评估模型路径
该脚本为基于LLaVA的模型提供评估,生成一个包含问题、正确答案和模型回答的jsonl文件。请随意修改脚本并应用于其他模型。
生成模型的响应后,可以手动检查准确性或使用大语言模型(如GPT-4)生成分数。
python scripts/gpt_grader.py --openai_api_key 你的OPENAI_API密钥 --answer_file 待评估的模型响应路径
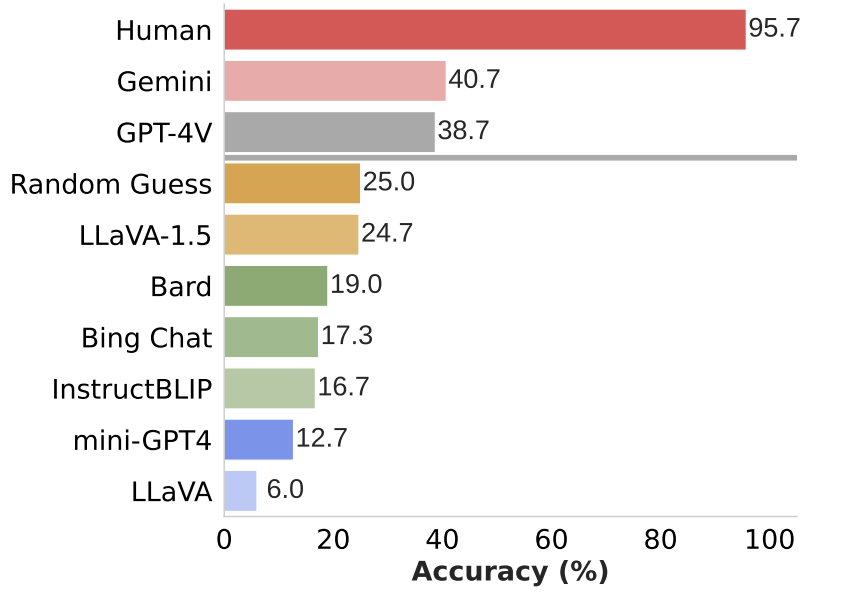
以下是最先进模型在MMVP基准测试上的结果。它表明这些领先模型在处理这些关于视觉定位的简单问题时仍然存在一致的困难,
要在MMVP-VLM上进行评估,请运行
python scripts/evaluate_vlm.py --directory MMVPVLM基准测试文件夹路径
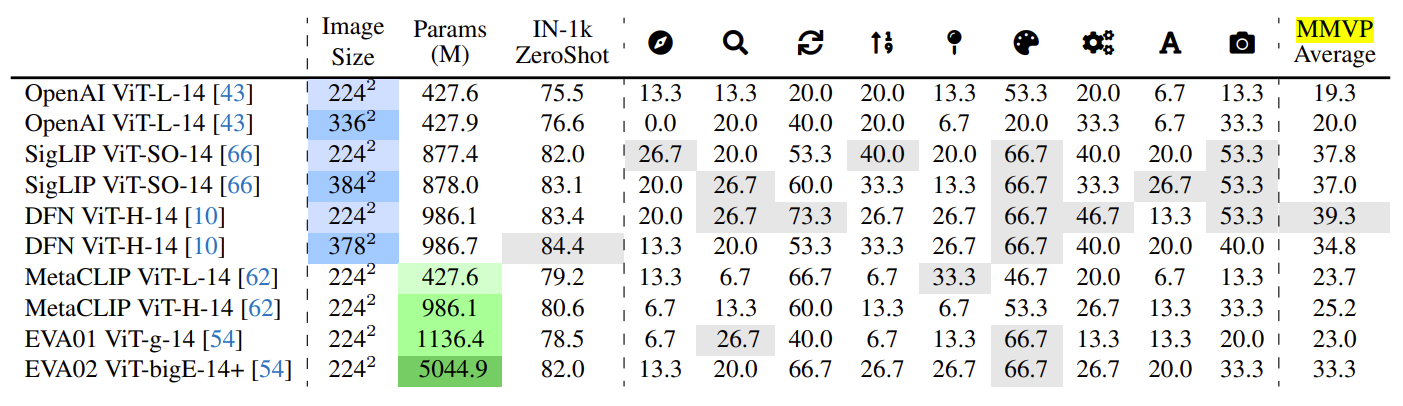
以下是最先进的CLIP模型在MMVP-VLM基准测试上的结果。它表明,在CLIP模型中增加参数和图像分辨率对于辨别这些视觉模式几乎没有改进。
训练
交错式MoF MLLM模型的训练遵循LLaVA的训练程序。请按照LLaVA中的数据准备过程进行。请将训练数据中的目录替换为您的本地目录。
对于预训练阶段,进入LLaVA文件夹并运行
sh pretrain.sh
对于指令微调阶段,进入LLaVA文件夹并运行
sh finetune.sh
您也可以在"LLaVA/llava/model/llava_arch.py/#L155"中找到交错式MoF所需的即插即用更改。函数prepare_inputs_labels_for_multimodal_withdino包含了在输入大语言模型之前在空间上交错DINOv2和CLIP特征的方法。
许可证
本项目采用MIT许可证。详情请见LICENSE。
引用
如果您发现本项目对您的研究有帮助,请考虑引用我们的论文:
@misc{tong2024eyes,
title={Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs},
author={Shengbang Tong and Zhuang Liu and Yuexiang Zhai and Yi Ma and Yann LeCun and Saining Xie},
year={2024},
eprint={2401.06209},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
致谢
- 本工作基于LLaVA构建。











