
Lookahead Decoding: 打破大语言模型推理的顺序依赖
大语言模型(LLM)正在迅速改变当今的应用程序,但其基于自回归解码的推理过程非常缓慢且难以优化。每个自回归解码步骤一次只能生成一个token,因此LLM请求的延迟主要取决于响应长度或等效的解码步骤数。更糟糕的是,每个解码步骤都未能充分利用现代GPU的并行处理能力,往往导致GPU利用率低下。这给许多注重快速响应时间的现实世界LLM应用带来了挑战,如聊天机器人和个人助手,它们经常需要以低延迟生成长序列。
为了解决这一问题,研究人员提出了一种名为Lookahead Decoding的新型并行解码算法。这种算法旨在加速LLM推理,同时保持生成结果的准确性。
Lookahead Decoding的工作原理
Lookahead Decoding的核心思想是打破自回归解码的顺序依赖。它通过并行提取和验证n-gram(n个连续token的序列)来实现这一目标,利用了Jacobi迭代方法。与其他加速方法不同,Lookahead Decoding无需使用草稿模型或数据存储,这简化了部署过程。

图1:Lookahead Decoding加速LLaMA-2-Chat 7B生成的演示。蓝色字体是在一个解码步骤中并行生成的token。
该算法的工作流程如下:
- 在每个解码步骤中,算法维护一个固定大小的二维窗口,用于从Jacobi迭代轨迹中生成n-gram。
- 同时,验证分支选择并验证有前景的n-gram候选。
- 通过简单的字符串匹配,识别第一个token与最后输入token匹配的n-gram。
- 一旦识别出匹配的n-gram,将其附加到当前输入并通过LLM前向传递进行验证。
这种方法允许算法在每个步骤中生成多个token,而不是仅生成一个token,从而减少了总的解码步骤数。实际上,Lookahead Decoding可以在少于N步的时间内生成N个token。
Lookahead Decoding的优势
-
无需草稿模型:与一些现有的加速方法(如推测解码)不同,Lookahead Decoding不需要额外的草稿模型,简化了部署和维护。
-
线性减少解码步骤:随着每个解码步骤使用的log(FLOPs)增加,解码步骤数线性减少。这意味着可以通过增加计算资源来换取更低的延迟。
-
灵活性:可以根据具体需求调整窗口大小(W)和n-gram大小(N)等参数,以在不同硬件和模型上获得最佳性能。
-
显著的性能提升:实验表明,Lookahead Decoding可以在不同数据集上实现1.5倍到2.3倍的延迟减少,而计算开销可以忽略不计。
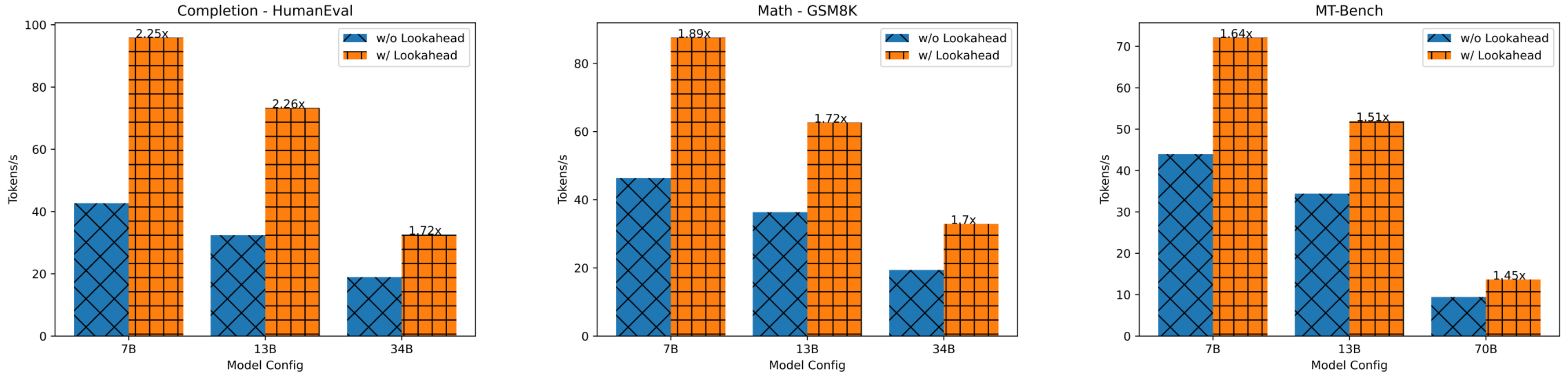
图2:Lookahead Decoding在不同模型和数据集上的加速效果。
实现细节
Lookahead Decoding的核心实现在decoding.py文件中。该算法需要针对每个特定模型进行适配,例如在models/llama.py中可以找到针对LLaMA模型的实现示例。
为了进一步提高性能,研究人员还实现了一个特殊的注意力掩码,将lookahead分支和验证分支合并到同一步骤中,充分利用GPU的并行处理能力。
import lade
lade.augment_all()
lade.config_lade(LEVEL=5, WINDOW_SIZE=7, GUESS_SET_SIZE=7, DEBUG=0)
上述代码展示了如何在自己的项目中使用Lookahead Decoding。通过设置USE_LADE=1环境变量或在Python脚本中设置os.environ["USE_LADE"]="1",即可启用该功能。
局限性与未来展望
尽管Lookahead Decoding在许多情况下表现出色,但它也存在一些局限性:
-
计算资源需求:虽然可以通过增加FLOPs来换取更低的延迟,但这可能会导致较小的GPU上性能下降。
-
采样解码的挑战:目前,Lookahead Decoding主要支持贪婪搜索和波束搜索,对于采样解码的支持还在开发中。
-
模型特异性:当前实现主要针对LLaMA模型,需要进一步适配其他模型架构。
未来的研究方向包括:
- 改进对采样解码的支持
- 优化小型GPU上的性能
- 扩展到更多模型架构
- 探索与其他加速技术(如FlashAttention)的结合
结论
Lookahead Decoding为加速大语言模型推理提供了一种创新的方法。通过打破自回归解码的顺序依赖,它实现了显著的性能提升,同时保持了生成结果的准确性。虽然仍有改进的空间,但这项技术无疑为未来的LLM应用开辟了新的可能性,特别是在需要快速响应的场景中。
随着研究的深入和技术的完善,我们可以期待看到Lookahead Decoding在更广泛的应用中发挥作用,推动大语言模型在实际应用中的进一步普及和优化。🚀🤖









