
 访问官网
访问官网 Github
Github 文档
文档 论文
论文使用前瞻解码打破大语言模型推理的顺序依赖
新闻 🔥
- [2024/2] 前瞻解码论文现已在arXiv上发布。现已支持采样和FlashAttention。更新了用于更好的令牌预测的高级功能。
介绍
我们介绍前瞻解码:
- 一种用于加速大语言模型推理的并行解码算法。
- 无需草稿模型或数据存储。
- 相对于每个解码步骤使用的计算量对数,线性减少解码步骤数。
以下是前瞻解码加速LLaMa-2-Chat 7B生成的演示:

背景:使用雅可比迭代的并行大语言模型解码
前瞻解码受到雅可比解码的启发,该方法将自回归解码视为求解非线性系统,并使用固定点迭代方法同时解码所有未来令牌。以下是雅可比解码的示例。
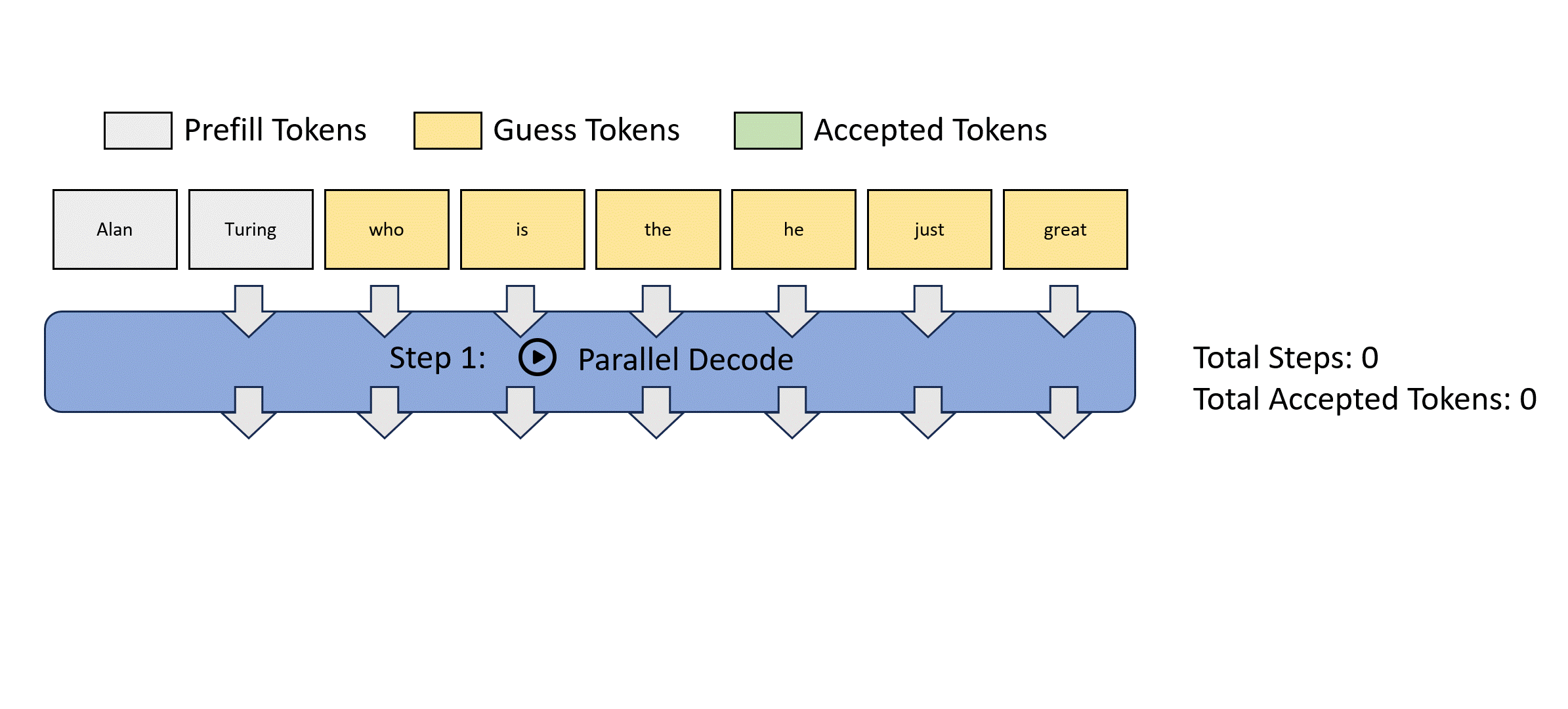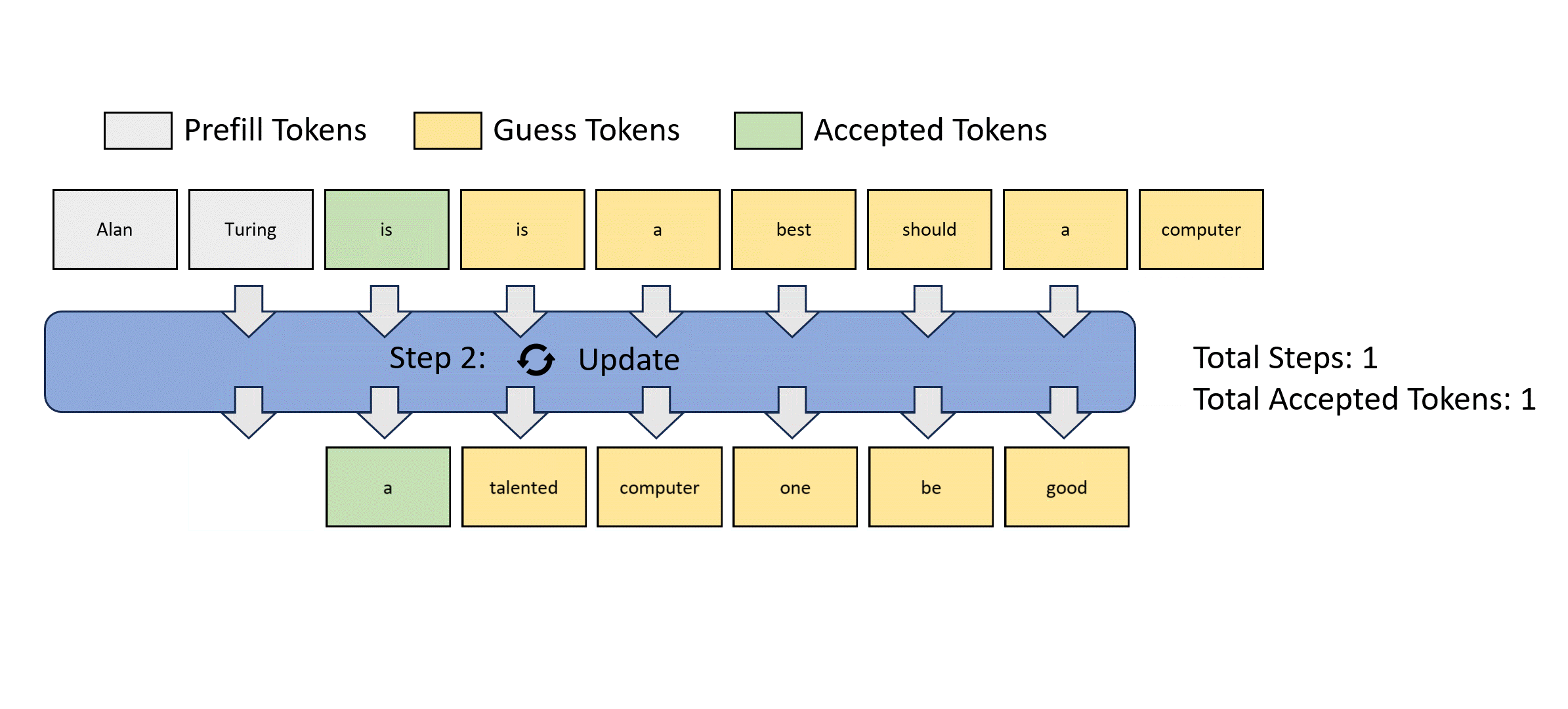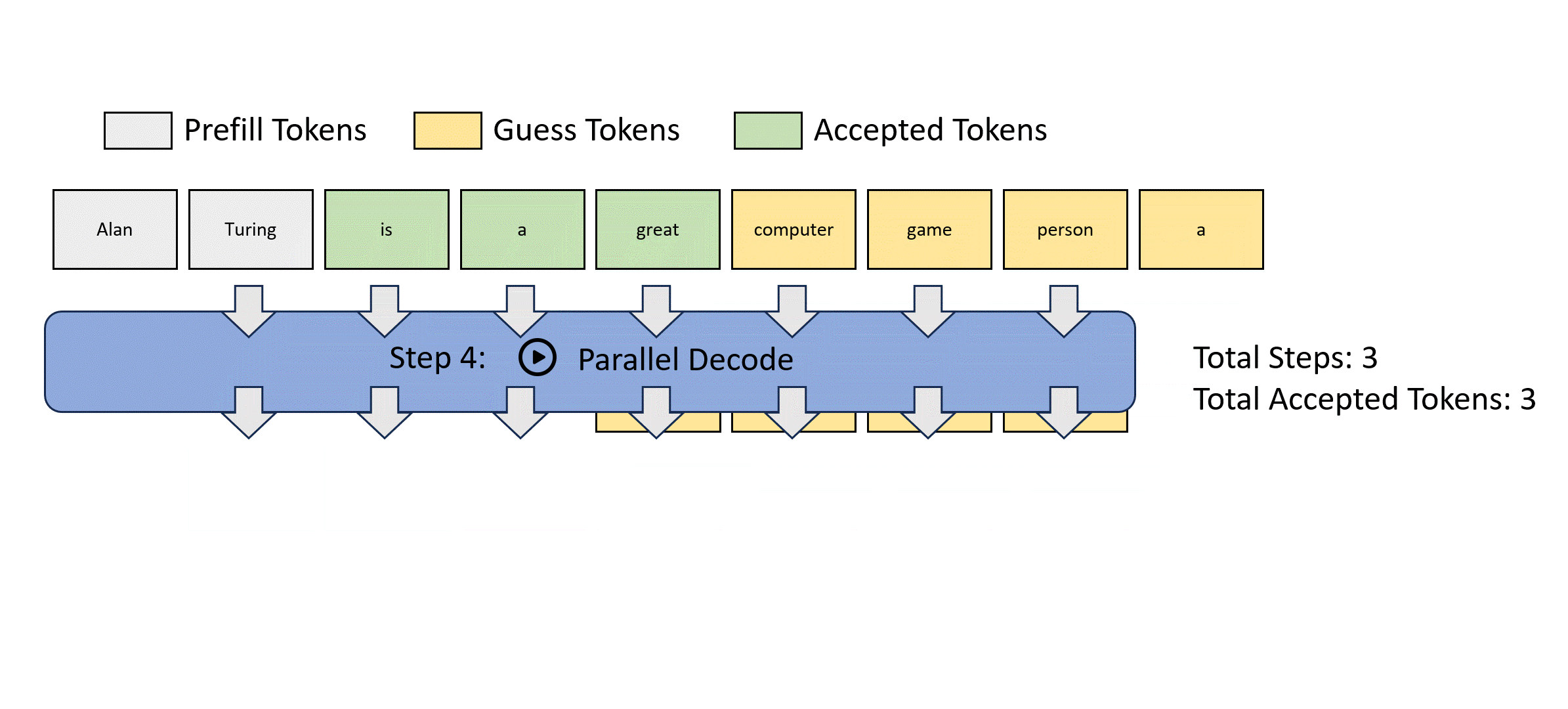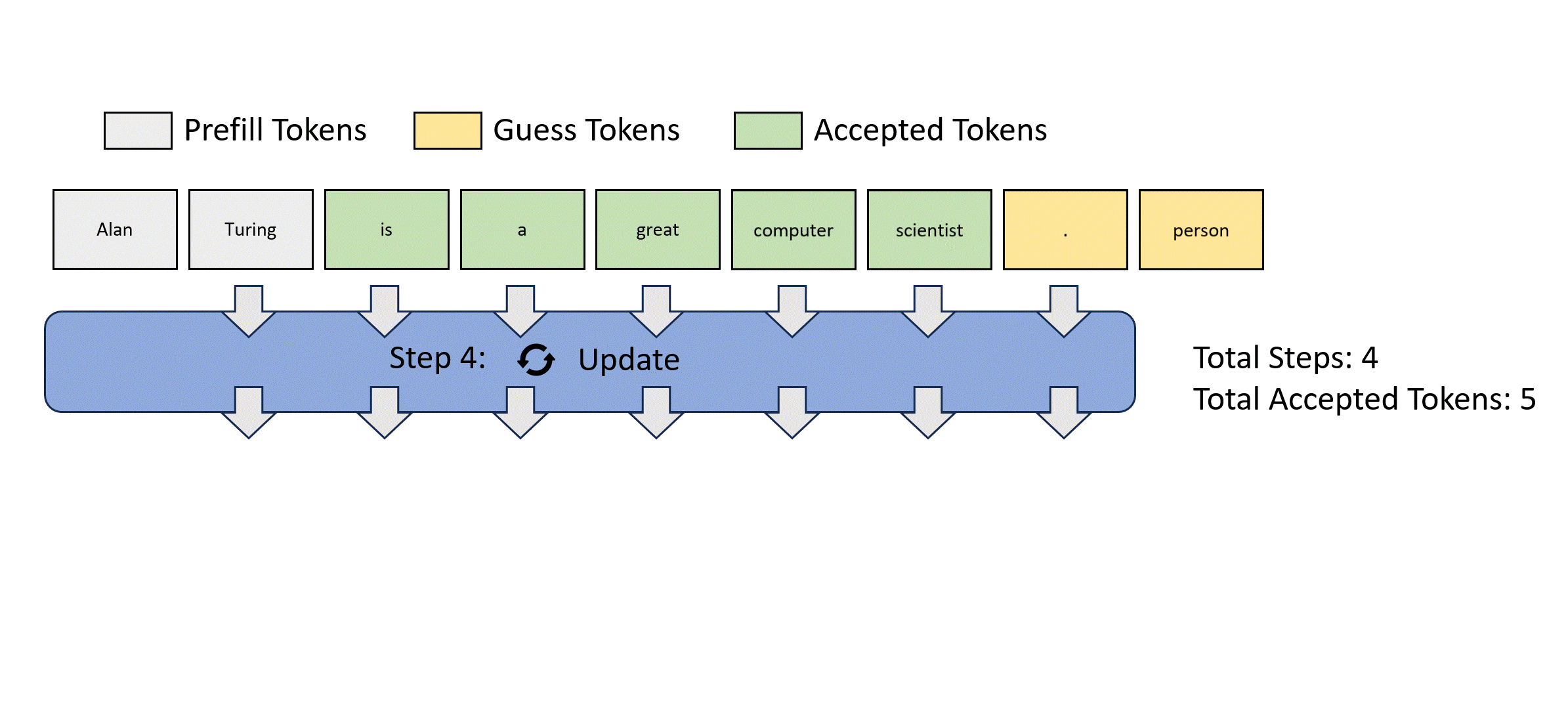
然而,雅可比解码在实际的大语言模型应用中几乎看不到实际的加速效果。
前瞻解码:使雅可比解码可行
前瞻解码利用雅可比解码的能力,通过收集和缓存从雅可比迭代轨迹生成的n-gram。
以下动图展示了通过雅可比解码收集2-gram并验证它们以加速解码的过程。
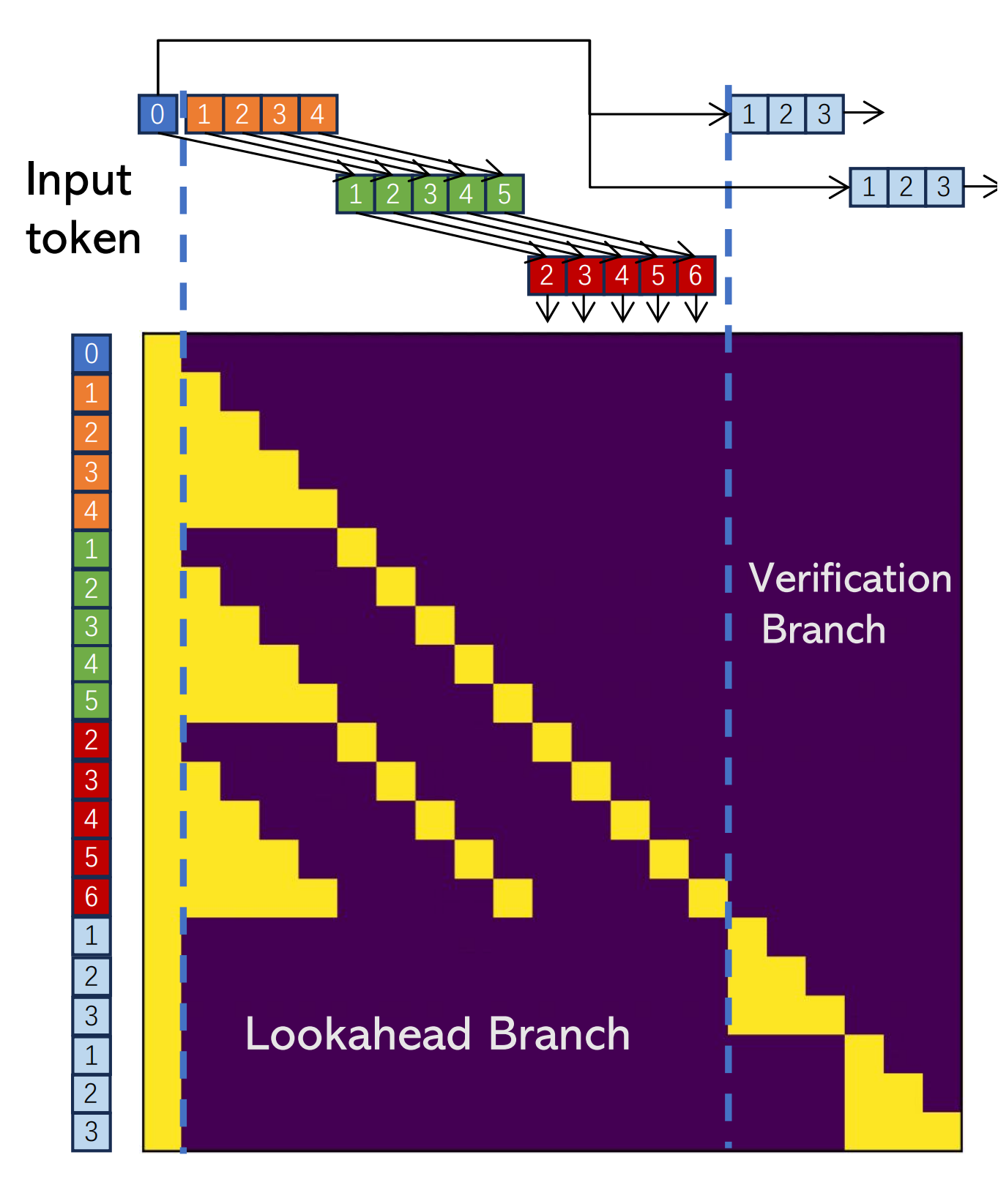
为了提高这个过程的效率,每个前瞻解码步骤被分为两个并行分支:前瞻分支和验证分支。前瞻分支维护一个固定大小的2D窗口,从雅可比迭代轨迹生成n-gram。同时,验证分支选择并验证有希望的n-gram候选。
前瞻分支和验证分支
前瞻分支旨在生成新的N-gram。该分支使用由两个参数定义的二维窗口运行:
- 窗口大小W:我们在未来令牌位置向前看多远以进行并行解码。
- N-gram大小N:我们回顾过去的雅可比迭代轨迹多少步以检索n-gram。
在验证分支中,我们识别第一个令牌与最后一个输入令牌匹配的n-gram。这是通过简单的字符串匹配确定的。一旦识别出来,这些n-gram被附加到当前输入,并通过对它们进行大语言模型前向传递来验证。
我们在一个注意力掩码中实现这些分支,以进一步利用GPU的并行计算能力。
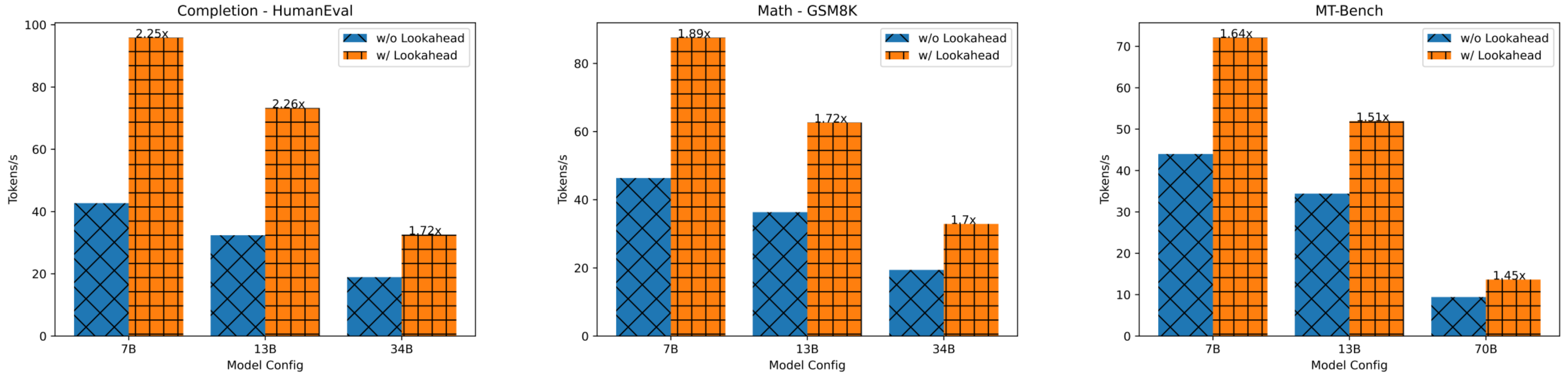
实验结果
我们的研究表明,前瞻解码显著降低了延迟,在单个GPU上不同数据集上的加速范围从1.5倍到2.3倍。请参见下图。
目录
安装
使用Pip安装
pip install lade
从源代码安装
git clone https://github.com/hao-ai-lab/LookaheadDecoding.git
cd LookaheadDecoding
pip install -r requirements.txt
pip install -e .
使用前瞻解码进行推理
您可以运行最小示例来看到前瞻解码带来的加速。
python minimal.py #不使用前瞻解码
USE_LADE=1 LOAD_LADE=1 python minimal.py #使用前瞻解码,1.6倍加速
您还可以使用前瞻解码与自己的聊天机器人聊天。
USE_LADE=1 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug --chat #聊天,使用前瞻
USE_LADE=0 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug --chat #聊天,不使用前瞻
USE_LADE=1 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug #不聊天,使用前瞻
USE_LADE=0 python applications/chatbot.py --model_path meta-llama/Llama-2-7b-chat-hf --debug #不聊天,不使用前瞻
在自己的代码中使用前瞻解码
您可以在自己的代码中导入并使用前瞻解码,只需三行代码。您还需要在命令行中设置USE_LADE=1或在Python脚本中设置os.environ["USE_LADE"]="1"。请注意,前瞻解码目前仅支持LLaMA。
import lade
lade.augment_all()
lade.config_lade(LEVEL=5, WINDOW_SIZE=7, GUESS_SET_SIZE=7, DEBUG=0)
#LEVEL、WINDOW_SIZE和GUESS_SET_SIZE是前瞻解码中三个重要的配置(N,W,G),请参考我们的博客!
#您可以通过在自己的设备上调整LEVEL/WINDOW_SIZE/GUESS_SET_SIZE来获得更好的性能。
然后您可以加速解码过程。以下是使用贪婪搜索的示例:
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map=torch_device)
model_inputs = tokenizer(input_text, return_tensors='pt').to(torch_device)
greedy_output = model.generate(**model_inputs, max_new_tokens=1024) #获得加速
以下是使用采样的示例:
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map=torch_device)
model_inputs = tokenizer(input_text, return_tensors='pt').to(torch_device)
sample_output = model.generate(**model_inputs, max_new_tokens=1024, temperature=0.7) #获得加速
FlashAttention支持
安装原始FlashAttention
pip install flash-attn==2.3.3 #原始FlashAttention
安装专门用于前瞻解码的FlashAttention有两种方法
- 在https://github.com/Viol2000/flash-attention-lookahead/releases/tag/v2.3.3 下载预构建包并安装(快速,推荐)。 例如,我的cuda==11.8,python==3.9和torch==2.1,我应该执行以下操作:
wget https://github.com/Viol2000/flash-attention-lookahead/releases/download/v2.3.3/flash_attn_lade-2.3.3+cu118torch2.1cxx11abiFALSE-cp39-cp39-linux_x86_64.whl
pip install flash_attn_lade-2.3.3+cu118torch2.1cxx11abiFALSE-cp39-cp39-linux_x86_64.whl
- 从源代码安装(慢,不推荐)
git clone https://github.com/Viol2000/flash-attention-lookahead.git
cd flash-attention-lookahead && python setup.py install
以下是使用FlashAttention运行模型的示例脚本:
python minimal-flash.py #不使用前瞻解码,使用FlashAttention
USE_LADE=1 LOAD_LADE=1 python minimal-flash.py #使用前瞻解码,使用FlashAttention,比不使用FlashAttention快20%
在您自己的代码中,调用config_lade时需要设置USE_FLASH=True,调用AutoModelForCausalLM.from_pretrained时需要设置attn_implementation="flash_attention_2"。
import lade
lade.augment_all()
lade.config_lade(LEVEL=5, WINDOW_SIZE=7, GUESS_SET_SIZE=7, USE_FLASH=True, DEBUG=0)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map=torch_device, attn_implementation="flash_attention_2")
model_inputs = tokenizer(input_text, return_tensors='pt').to(torch_device)
greedy_output = model.generate(**model_inputs, max_new_tokens=1024) #获得加速
我们将直接将FlashAttention集成到这个仓库中,以简化安装和使用。
引用
@misc{fu2024break,
title={Break the Sequential Dependency of LLM Inference Using Lookahead Decoding},
author={Yichao Fu and Peter Bailis and Ion Stoica and Hao Zhang},
year={2024},
eprint={2402.02057},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
指南
核心实现在decoding.py中。前瞻解码需要针对每个特定模型进行适配。models/llama.py中有一个示例。











