
引言
深度学习技术在近年来取得了巨大的进展,但将深度学习模型部署到生产环境中仍然面临诸多挑战。本文旨在为构建生产级深度学习系统提供一个全面的指南,涵盖从数据管理到模型部署的整个流程。
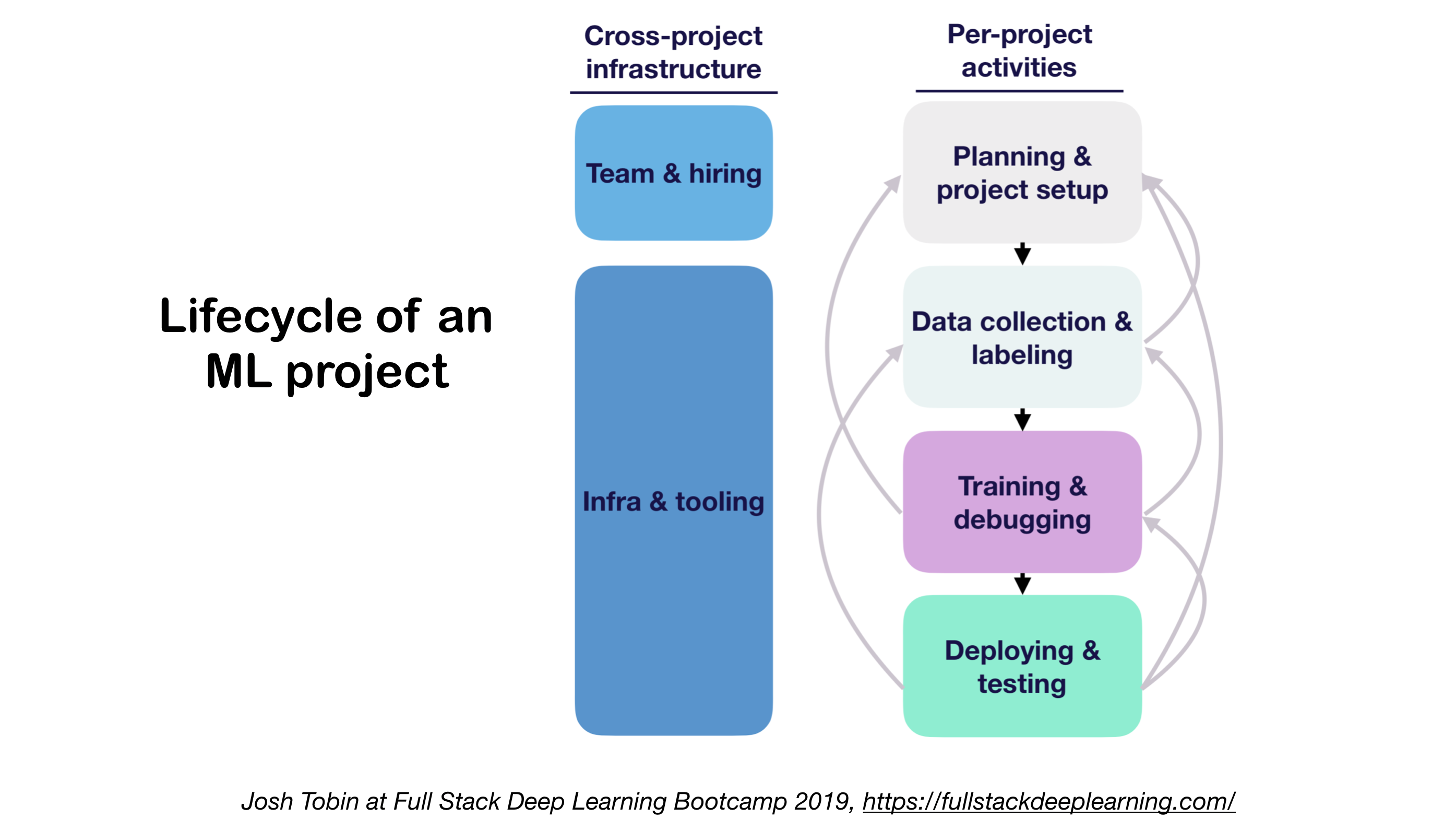
机器学习项目生命周期
构建生产级深度学习系统需要遵循一定的生命周期:
- 项目定义与规划
- 数据收集与标注
- 特征工程
- 模型开发与训练
- 评估与优化
- 部署与监控
- 持续改进
了解这个生命周期对于成功实施机器学习项目至关重要。
数据管理
数据源
高质量的标注数据对于监督学习模型至关重要。可以考虑以下数据来源:
- 开源数据集(适合起步,但不具竞争优势)
- 数据增强(计算机视觉领域必备,NLP领域可选)
- 合成数据(几乎总是值得尝试,尤其是NLP领域)
数据标注
数据标注需要专门的软件栈、临时劳动力和质量控制。主要的标注方式包括:
- 众包(如Mechanical Turk):成本低廉,可扩展性强,但可靠性较低,需要严格的质量控制
- 雇佣专职标注员:质量控制需求较少,但成本高昂,扩展性差
- 数据标注服务公司:平衡了成本和质量
推荐的标注平台包括:Diffgram(计算机视觉)、Prodigy(文本和图像)、Labelbox(计算机视觉)等。
数据存储
数据存储方案需要根据数据类型和使用场景选择:
- 对象存储:存储二进制数据(如图像、音频文件等)
- 推荐:Amazon S3、Ceph对象存储
- 数据库:存储元数据(如文件路径、标签等)
- 推荐:PostgreSQL,支持结构化SQL和非结构化JSON
- 数据湖:聚合无法从数据库获取的特征(如日志)
- 推荐:Amazon Redshift
- 特征存储:存储、访问和共享机器学习特征
- 推荐:FEAST(Google Cloud开源)、Michelangelo Palette(Uber)
数据版本控制
数据版本控制对于已部署的ML模型至关重要,因为部署的ML模型同时依赖于代码和数据。推荐的数据版本控制平台包括:
- DVC:ML项目的开源版本控制系统
- Pachyderm:数据版本控制
- Dolt:SQL数据库的版本控制
数据处理
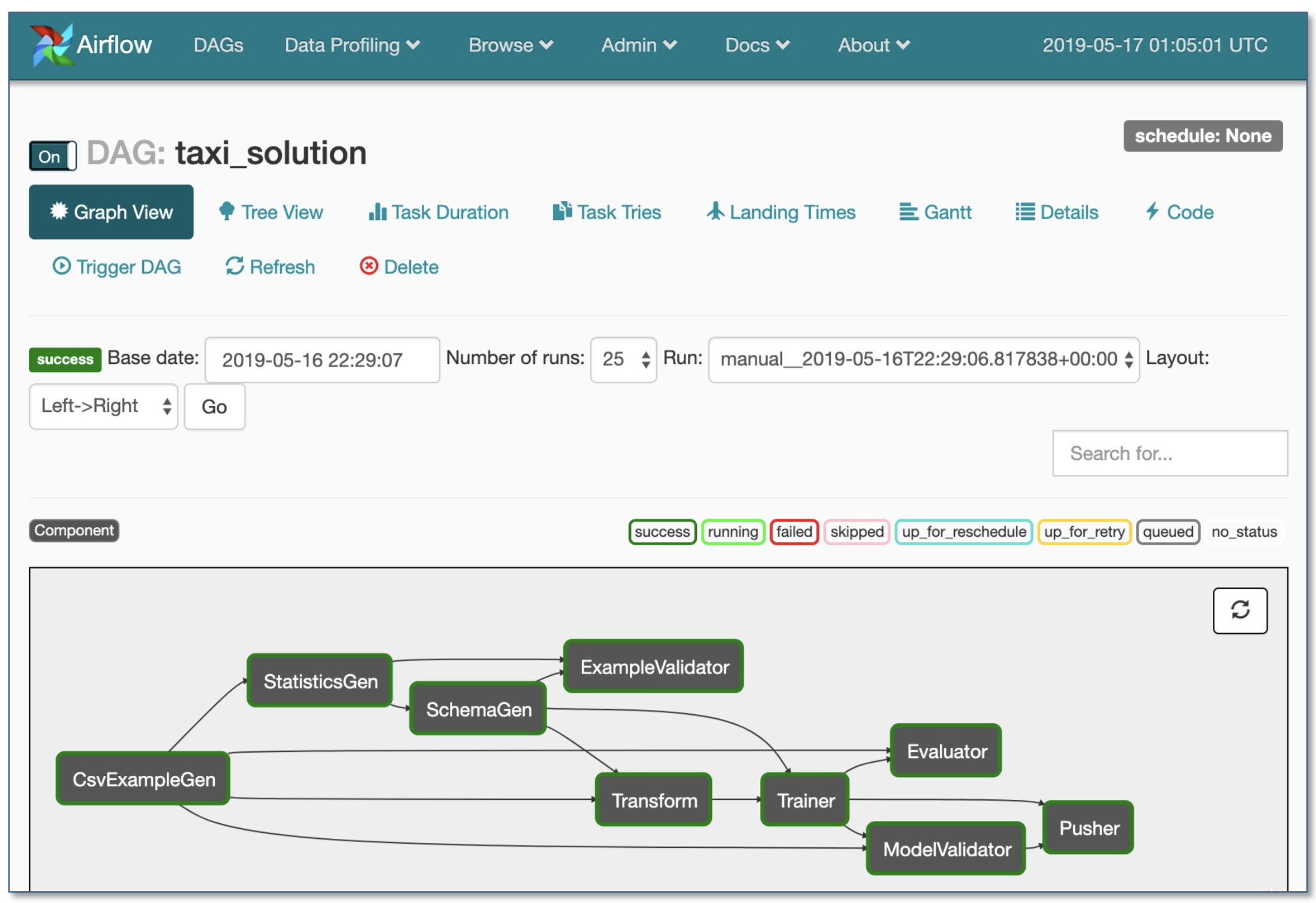
生产模型的训练数据可能来自多个来源,包括存储的数据、日志处理和其他分类器的输出。任务之间存在依赖关系,每个任务需要在其依赖项完成后启动。推荐使用工作流管理器来处理这些复杂的依赖关系:
- Airflow(Airbnb):动态、可扩展、优雅且可扩展(使用最广泛)
- DAG工作流
- 强大的条件执行:失败时重试
- Pusher支持带有tensorflow serving的docker镜像
- 整个工作流在单个.py文件中
开发、训练和评估
软件工程
- 首选语言:Python
- 推荐的编辑器:VS Code(内置git暂存和差异、代码lint、通过ssh远程打开项目)
- 计算资源建议:
- 个人或初创公司:
- 开发:4x图灵架构PC
- 训练/评估:使用相同的4x GPU PC。运行多个实验时,购买共享服务器或使用云实例。
- 大公司:
- 开发:为每个ML科学家购买4x图灵架构PC或让他们使用V100实例
- 训练/评估:使用云实例,适当配置并处理故障
- 个人或初创公司:
资源管理
- 旧式集群作业调度程序(如Slurm工作负载管理器)
- Docker + Kubernetes
- Kubeflow
- Polyaxon(付费功能)
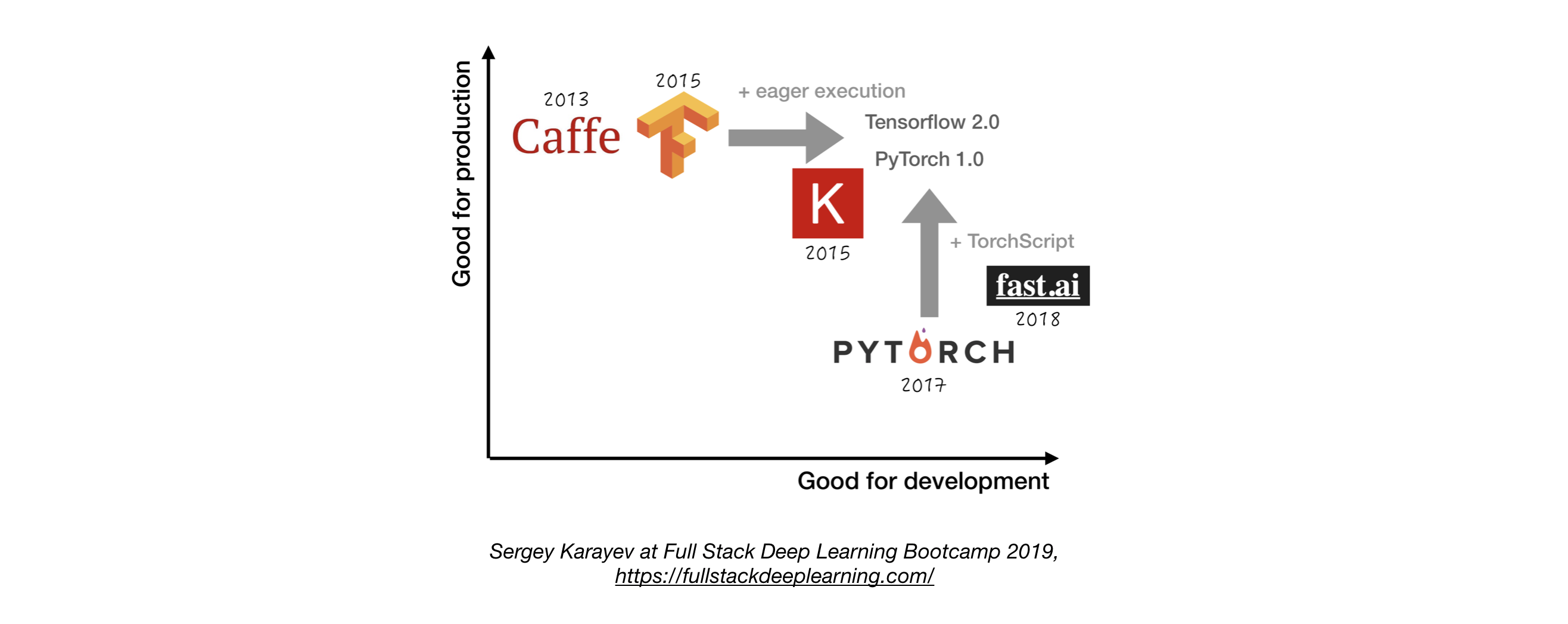
深度学习框架
除非有充分理由,否则使用TensorFlow/Keras或PyTorch。下图比较了不同框架在"开发"和"生产"方面的表现:
实验管理
开发、训练和评估策略:
-
始终从简单开始
- 在小批量数据上训练一个小模型。只有在成功后,才扩展到更大的数据和模型,并进行超参数调优!
-
实验管理工具:
- Tensorboard:提供ML实验所需的可视化和工具
- MLFlow Tracking:用于记录参数、代码版本、指标和输出文件以及结果可视化
- 一行Python代码即可自动跟踪实验
- 实验的并排比较
- 超参数调优
- 支持基于Kubernetes的作业
超参数调优
方法:
- 网格搜索
- 随机搜索
- 贝叶斯优化
- HyperBand和异步连续减半算法(ASHA)
- 基于种群的训练
平台:
- RayTune:任何规模的超参数调优Python库
- Katib:Kubernetes原生超参数调优和神经架构搜索系统
- Keras Tuner:专为tf.keras和TensorFlow 2.0设计的超参数调优器
分布式训练
- 数据并行:当迭代时间过长时使用(TensorFlow和PyTorch都支持)
- Ray分布式训练
- 模型并行:当模型不适合单个GPU时使用
- 其他解决方案:
- Horovod
测试和部署
测试和CI/CD
机器学习生产软件需要比传统软件更多样化的测试套件:

-
单元和集成测试:
- 训练系统测试:测试训练管道
- 验证测试:在验证集上测试预测系统
- 功能测试:在几个重要示例上测试预测系统
-
持续集成:在每次新代码更改推送到仓库后运行测试
-
持续集成SaaS:
- Argo:开源Kubernetes原生工作流引擎
- CircleCI:支持多种语言,自定义环境,灵活的资源分配
- Travis CI
- Buildkite:快速稳定的构建,开源代理几乎可以在任何机器和架构上运行
Web部署
包括预测系统和服务系统:
- 预测系统:处理输入数据,进行预测
- 服务系统(Web服务器):
- 考虑规模提供预测
- 使用REST API响应HTTP预测请求
- 调用预测系统进行响应
部署选项:
- 部署到虚拟机,通过添加实例进行扩展
- 部署为容器,通过编排进行扩展
- 容器:Docker
- 容器编排:Kubernetes(目前最流行)
- 将代码部署为"无服务器函数"
- 通过模型服务解决方案部署
模型服务:
- 专门用于ML模型的Web部署
- 批处理GPU推理请求
- 框架:
- TensorFlow Serving
- MXNet Model Server
- Clipper(Berkeley)
- SaaS解决方案:
- Seldon:在Kubernetes上服务和扩展任何框架构建的模型
- Algorithmia
决策:CPU还是GPU?
- CPU推理:
- 如果满足要求,首选CPU推理
- 通过添加更多服务器或使用无服务器架构进行扩展
- GPU推理:
- 使用TF Serving或Clipper
- 自适应批处理很有用
服务网格和流量路由
- 从单体应用向分布式微服务架构过渡可能具有挑战性
- 服务网格(由微服务网络组成)可以降低此类部署的复杂性,减轻开发团队的压力
- Istio:一个服务网格,可以轻松创建具有负载均衡、服务间身份验证、监控等功能的已部署服务网络,几乎无需更改服务代码
监控
监控的目的:
- 停机、错误和分布偏移的警报
- 捕获服务和数据回归
云提供商的解决方案通常足够好
Kiali:Istio的可观察性控制台,具有服务网格配置功能。它回答了这些问题:微服务如何连接?它们的性能如何?
嵌入式和移动设备部署
主要挑战:内存占用和计算约束
解决方案:
- 量化
- 减小模型大小(如MobileNets)
- 知识蒸馏(如NLP的DistillBERT)
嵌入式和移动框架:
- TensorFlow Lite
- PyTorch Mobile
- Core ML
- ML Kit
- FRITZ
- OpenVINO
模型转换:
- ONNX(开放神经网络交换):深度学习模型的开源格式
总结
构建生产级深度学习系统是一个复杂的过程,涉及多个组件和考虑因素。本文提供了一个全面的指南,涵盖了从数据管理到模型部署的各个方面。通过遵循这些最佳实践和利用推荐的工具,开发人员可以更有效地构建和部署深度学习系统,以应对实际应用中的挑战。
随着深度学习技术的不断发展,生产级系统的构建方法也在不断演进。持续学习和实践对于保持竞争力至关重要。希望本指南能为读者提供一个坚实的基础,帮助他们在这个快速发展的领域中取得成功。
参考资源
- Full Stack Deep Learning Bootcamp
- Advanced KubeFlow Workshop by Pipeline.ai
- TFX: Real World Machine Learning in Production
通过本文的指导,读者应该能够更好地理解和应对构建生产级深度学习系统的挑战。记住,实践是最好的学习方式,所以不要犹豫,开始动手构建你的第一个生产级深度学习系统吧!


















