
深度学习生产级系统的实践指南
在当今的人工智能时代,深度学习技术正在各行各业得到广泛应用。然而,将深度学习模型从实验室环境部署到实际生产环境中,往往是一个充满挑战的过程。本文旨在为读者提供一份全面的指南,介绍如何构建和部署生产级深度学习系统。
机器学习项目生命周期
在开始一个机器学习项目时,了解整个项目的生命周期非常重要。一个典型的机器学习项目生命周期包括以下几个阶段:
- 问题定义和范围确定
- 数据收集和准备
- 特征工程
- 模型选择和训练
- 模型评估和优化
- 部署和监控
- 持续改进
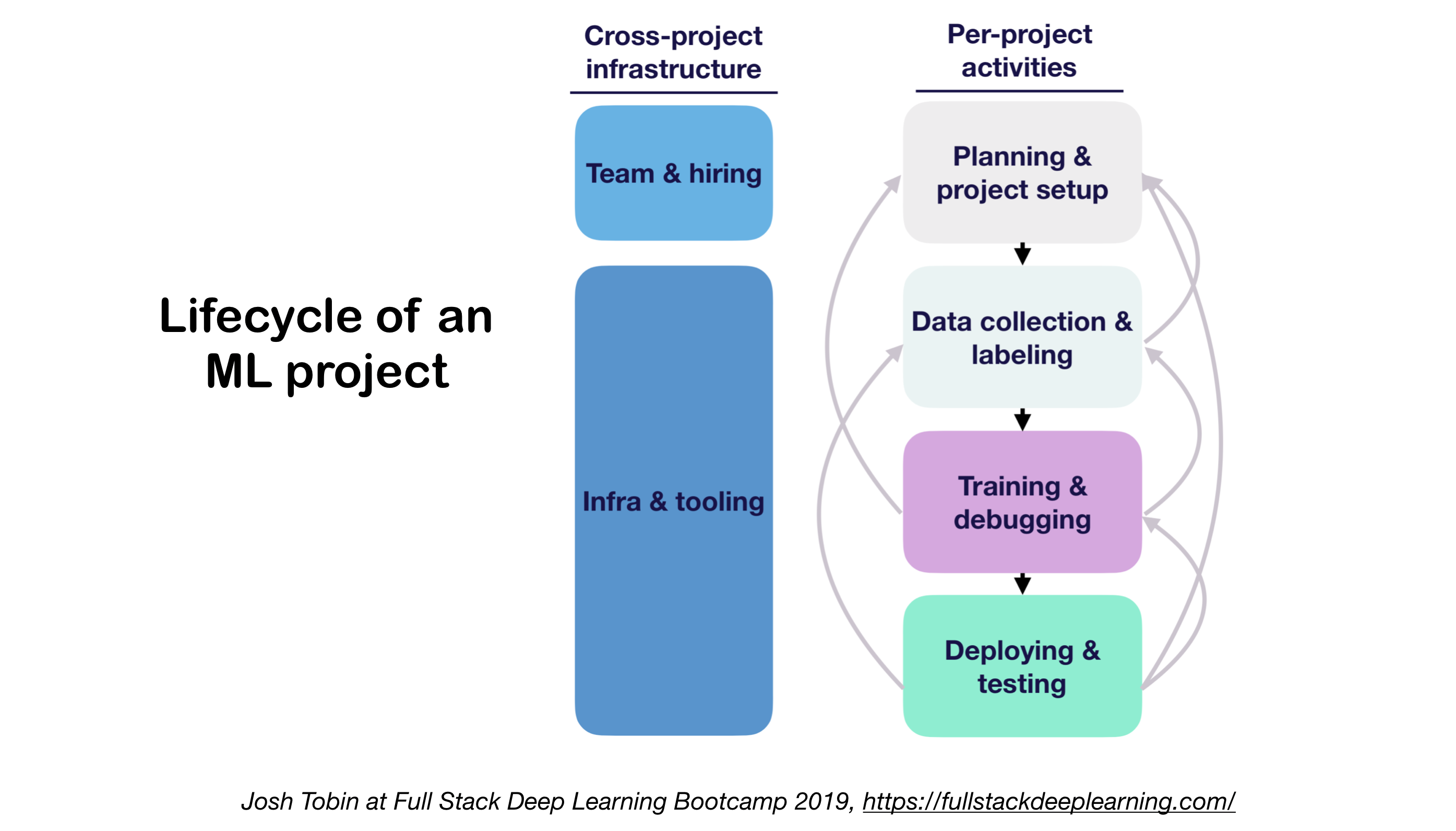
在项目的每个阶段,都需要考虑不同的因素和使用相应的工具。接下来,我们将详细介绍生产级深度学习系统的各个组成部分。
数据管理
数据是机器学习项目的基础。高质量、大规模的数据对于训练出高性能的深度学习模型至关重要。在生产环境中,有效的数据管理涉及以下几个方面:
数据源
- 监督学习需要大量标注数据
- 自行标注数据成本高昂
- 可以考虑使用开源数据集、数据增强技术和合成数据
数据标注
- 需要专门的软件栈、临时劳动力和质量控制
- 可以使用众包平台(如Mechanical Turk)或专业的数据标注服务公司
- 推荐的标注平台:Diffgram、Prodigy、HIVE等
数据存储
- 对象存储:用于存储二进制数据(如图像、音频文件等)
- 数据库:存储元数据(如文件路径、标签等)
- 数据湖:聚合无法从数据库获得的特征
- 特征存储:存储、访问和共享机器学习特征
数据版本控制
- 对于已部署的ML模型来说是必需的
- 推荐工具:DVC、Pachyderm、Dolt等
数据处理
- 生产模型的训练数据可能来自不同来源
- 需要工作流管理工具来协调任务依赖关系
- 推荐使用Airflow等工作流编排工具
开发、训练和评估
在这个阶段,我们需要选择合适的开发环境、框架和工具来构建和训练模型。
软件工程
- 主流语言:Python
- 推荐编辑器:VS Code(内置Git集成、代码检查等功能)
- 计算资源:根据规模选择本地GPU或云实例
资源管理
- 用于分配空闲资源给程序
- 选项:传统集群作业调度器(如Slurm)、Docker + Kubernetes、Kubeflow等
深度学习框架
- 推荐使用TensorFlow/Keras或PyTorch
- 不同框架在开发和生产方面各有优势
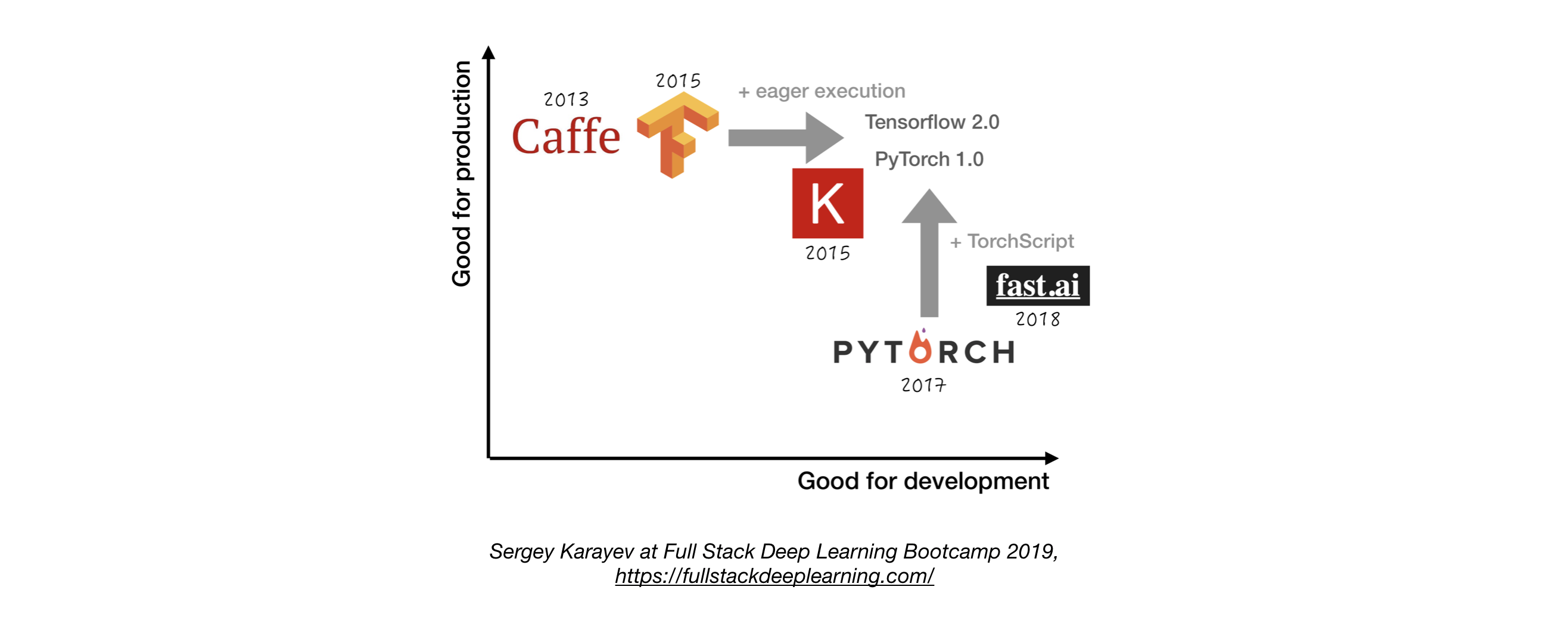
实验管理
- 始终从简单模型开始,逐步扩展到更大的数据和模型
- 使用实验管理工具:Tensorboard、MLflow Tracking等
- 这些工具可以帮助跟踪代码、实验和结果
超参数调优
- 常用方法:网格搜索、随机搜索、贝叶斯优化等
- 推荐工具:Ray Tune、Katib、Keras Tuner等
分布式训练
- 数据并行:当迭代时间过长时使用
- 模型并行:当模型无法装入单个GPU时使用
测试和部署
将模型部署到生产环境是机器学习项目中最具挑战性的部分之一。这个阶段需要考虑以下几个方面:
测试和CI/CD
- 机器学习生产软件需要更多样化的测试套件
- 包括单元测试、集成测试、验证测试和功能测试
- 使用持续集成工具:Argo、CircleCI等
Web部署
-
包括预测系统和服务系统
-
部署选项:
- 部署到虚拟机,通过添加实例来扩展
- 部署为容器,通过编排来扩展(如Kubernetes)
- 部署为无服务器函数
- 通过模型服务解决方案部署
-
模型服务框架:TensorFlow Serving、Seldon等
服务网格和流量路由
- 使用服务网格(如Istio)简化微服务架构的部署和管理
监控
- 目的:监控停机、错误和分布偏移
- 捕捉服务和数据回归
- 推荐工具:Kiali(用于Istio的可观察性控制台)
嵌入式和移动设备部署
- 主要挑战:内存占用和计算约束
- 解决方案:量化、模型压缩、知识蒸馏等
- 框架:TensorFlow Lite、PyTorch Mobile等
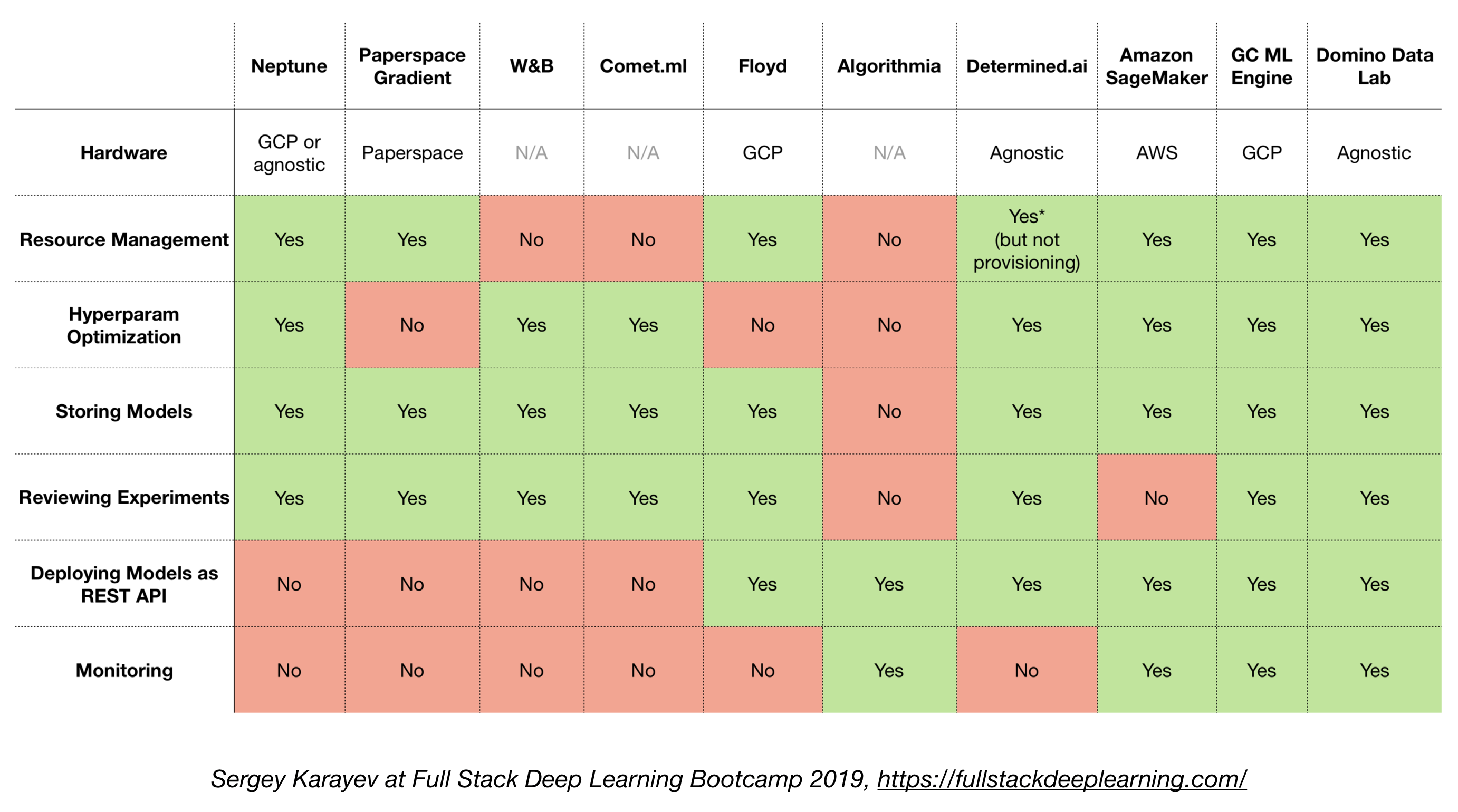
全栈机器学习平台
对于大型组织,可以考虑使用全栈机器学习平台来简化整个机器学习生命周期的管理。一些流行的选项包括:
- TensorFlow Extended (TFX)
- Uber的Michelangelo
- Google Cloud AI Platform
- Amazon SageMaker
- Neptune
- Determined AI等
结语
构建生产级深度学习系统是一个复杂的过程,需要考虑多个方面并整合各种工具和技术。本文提供了一个全面的指南,涵盖了从数据管理到模型部署的整个机器学习生命周期。通过遵循这些最佳实践和使用推荐的工具,开发者可以更有效地构建和部署可靠、可扩展的深度学习系统。
随着人工智能技术的不断发展,生产级深度学习系统的构建方法也在不断演进。保持对新工具和技术的关注,并持续学习和实践,是在这个快速发展的领域保持竞争力的关键。希望本文能为读者提供有价值的指导,帮助他们在实际项目中构建出高质量的深度学习系统。
参考资源
- Full Stack Deep Learning Bootcamp
- TensorFlow Extended (TFX) 文档
- Kubeflow 官方文档
- MLOps: 持续交付和自动化流水线在机器学习中的应用
通过本文的学习,读者应该对构建生产级深度学习系统有了全面的认识。从数据管理到模型部署,每个环节都需要仔细考虑和精心设计。随着技术的不断发展,保持学习和实践的态度将帮助我们在这个充满机遇和挑战的领域中不断进步。


















