
深度强化学习助力机器人自主导航
在人工智能和机器人技术飞速发展的今天,如何让机器人在复杂环境中实现自主、智能的导航一直是研究的热点。近年来,深度强化学习(Deep Reinforcement Learning, DRL)因其强大的学习能力和决策能力,在机器人导航领域展现出巨大的潜力。本文将围绕GitHub上备受关注的DRL-robot-navigation项目,深入探讨深度强化学习在移动机器人导航中的应用。
DRL-robot-navigation项目简介
DRL-robot-navigation是一个开源项目,旨在利用深度强化学习技术实现移动机器人在ROS Gazebo模拟器中的自主导航。该项目由Reinis Cimurs开发,目前在GitHub上已获得545颗星和118次fork,显示出其在学术界和工业界的广泛关注度。
项目的核心是使用双延迟深度确定性策略梯度(Twin Delayed Deep Deterministic Policy Gradient, TD3)神经网络,让机器人学会在模拟环境中导航到随机目标点,同时避开障碍物。这种方法结合了深度学习的强大表征能力和强化学习的决策优化能力,为机器人自主导航提供了一种新的解决方案。
技术原理与实现
TD3算法简介
TD3算法是深度确定性策略梯度(DDPG)算法的改进版本,它通过以下几个关键改进来提高学习的稳定性和效率:
- 双Q学习:使用两个Q网络来减少过估计偏差。
- 延迟策略更新:减缓策略网络的更新频率,以降低Q值估计的误差。
- 目标策略平滑:在目标动作中添加噪声,以减少Q值估计的方差。
这些改进使TD3在连续动作空间的任务中表现出色,特别适合机器人导航这类需要精确控制的场景。
系统架构
DRL-robot-navigation项目的系统架构主要包括以下几个部分:
- ROS Gazebo模拟器:提供仿真环境,模拟机器人和障碍物。
- 传感器模块:使用3D Velodyne激光雷达获取环境信息。
- TD3神经网络:包括Actor网络和Critic网络,负责策略学习和决策。
- 奖励函数设计:根据机器人与目标的距离、是否碰撞等因素计算奖励。
- 训练和测试模块:实现神经网络的训练和评估。

上图展示了机器人在训练过程中的行为。我们可以看到,随着训练的进行,机器人逐渐学会了避开障碍物并向目标点移动。
项目安装与使用
DRL-robot-navigation项目的安装和使用相对简单,主要依赖包括:
- ROS Noetic
- PyTorch 1.10
- Tensorboard
详细的安装步骤如下:
- 克隆仓库:
git clone https://github.com/reiniscimurs/DRL-robot-navigation
- 编译工作空间:
cd ~/DRL-robot-navigation/catkin_ws
catkin_make_isolated
- 设置环境变量:
export ROS_HOSTNAME=localhost
export ROS_MASTER_URI=http://localhost:11311
export ROS_PORT_SIM=11311
export GAZEBO_RESOURCE_PATH=~/DRL-robot-navigation/catkin_ws/src/multi_robot_scenario/launch
source ~/.bashrc
cd ~/DRL-robot-navigation/catkin_ws
source devel_isolated/setup.bash
- 运行训练:
cd ~/DRL-robot-navigation/TD3
python3 train_velodyne_td3.py
- 使用Tensorboard监控训练过程:
tensorboard --logdir runs
- 训练完成后测试模型:
python3 test_velodyne_td3.py
应用场景与前景
DRL-robot-navigation项目展示的技术在多个领域有广阔的应用前景:
- 智能家居:自主导航的清洁机器人可以更高效地完成家庭清洁任务。
- 仓储物流:智能仓储机器人能够自主规划路径,提高物流效率。
- 医疗服务:在医院环境中,自主导航的机器人可以协助物资运输和消毒工作。
- 探索与救援:在危险或难以到达的环境中,自主导航的机器人可以进行探索和救援任务。
- 智慧城市:自动驾驶汽车和无人机的导航系统可以借鉴这一技术。
挑战与未来发展
尽管DRL-robot-navigation项目展现了深度强化学习在机器人导航中的巨大潜力,但仍然存在一些挑战需要解决:
- 泛化能力:如何让训练好的模型适应不同的环境和任务场景。
- 样本效率:深度强化学习通常需要大量的训练数据,如何提高学习效率是一个重要问题。
- 安全性和鲁棒性:在实际应用中,需要确保导航算法的可靠性和安全性。
- 多智能体协作:在复杂环境中,多个机器人如何协调合作是一个值得研究的方向。
未来,研究者们可能会在以下方向继续探索:
- 结合迁移学习,提高模型的泛化能力。
- 引入元学习技术,加快学习速度和适应能力。
- 集成语义理解,实现更高级的导航和交互功能。
- 探索多模态感知和决策,提高环境理解和导航精度。
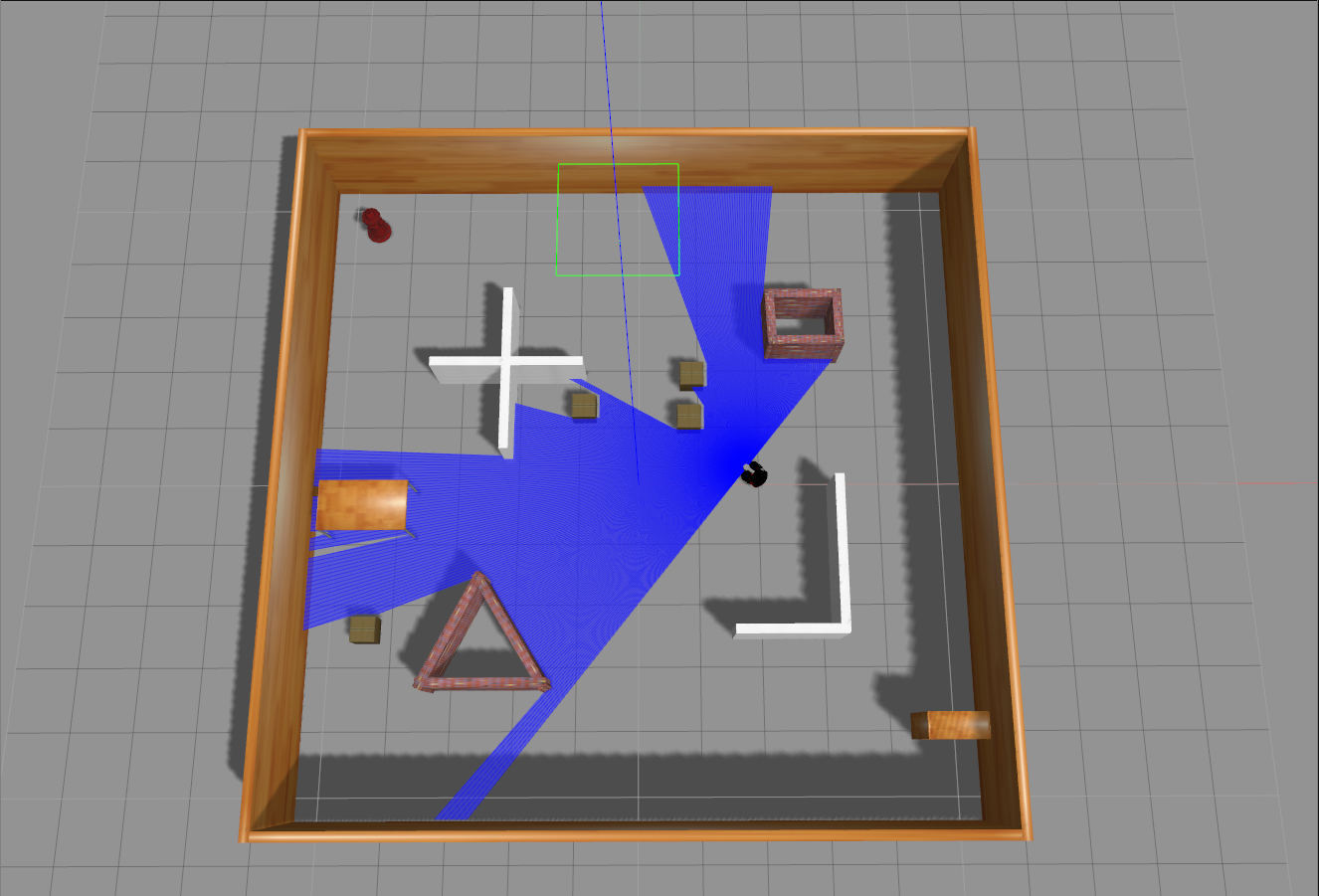
上图展示了项目中使用的Gazebo仿真环境,这种逼真的仿真对于开发和测试导航算法至关重要。
结语
DRL-robot-navigation项目为我们展示了深度强化学习在移动机器人自主导航领域的巨大潜力。通过结合先进的深度学习技术和强化学习策略,该项目实现了机器人在复杂环境中的智能导航。尽管还存在一些挑战,但随着技术的不断进步和研究的深入,我们有理由相信,基于深度强化学习的机器人导航系统将在未来发挥越来越重要的作用,为智能机器人的广泛应用铺平道路。
对于有兴趣深入了解或参与这一领域研究的读者,可以访问DRL-robot-navigation项目GitHub页面获取更多信息。同时,相关的安装教程也为初学者提供了详细的指导。让我们共同期待深度强化学习为机器人导航带来的更多突破和创新! 🤖🚀


















