
深度强化学习算法的Keras实现
Deep-RL-Keras是一个基于Keras框架实现的深度强化学习算法库,包含了多种流行的深度强化学习算法。该项目旨在为研究人员和开发者提供一个模块化、易于使用的工具,以便快速实现和测试各种深度强化学习算法。
主要特点
- 基于Keras框架,易于上手和扩展
- 实现了多种经典的深度强化学习算法
- 模块化设计,便于复用和修改
- 支持OpenAI Gym环境
- 提供了详细的使用说明和示例
已实现的算法
Deep-RL-Keras目前已经实现了以下几种深度强化学习算法:
- 同步N步优势演员-评论家算法(A2C)
- 异步N步优势演员-评论家算法(A3C)
- 深度确定性策略梯度算法(DDPG)
- 双深度Q网络(DDQN)
- 带优先经验回放的双深度Q网络(DDQN+PER)
- 对偶网络双深度Q网络(Dueling DDQN)
这些算法涵盖了目前深度强化学习领域的主流方法,包括基于策略的方法和基于值的方法。研究人员可以方便地比较这些算法在不同任务上的表现。
环境要求
要运行Deep-RL-Keras,你需要安装以下依赖:
- Python 3
- Keras 2.1.6
- OpenAI Gym
可以通过以下命令安装必要的包:
pip install gym keras==2.1.6
算法详解
A2C(Advantage Actor-Critic)
A2C是一种同步的演员-评论家算法。评论家网络作为值函数近似器,演员网络作为策略函数近似器。在训练过程中,评论家预测TD误差并指导自身和演员的学习。实际应用中,我们使用优势函数来近似TD误差。为了提高稳定性,两个网络共享计算主干,并使用N步折扣奖励的公式。此外,还加入了熵正则化项来鼓励探索。
A2C算法简单高效,但在Atari游戏等复杂环境中由于计算时间过长而难以应用。
A3C(Asynchronous Advantage Actor-Critic)
A3C是A2C的异步版本,通过异步权重更新大大提高了计算效率。它使用多个agent在多个线程上异步执行梯度上升。A3C算法在Atari Breakout等环境中表现出色。
DDPG(Deep Deterministic Policy Gradient)
DDPG是一种用于连续动作空间的无模型、离策略算法。与A2C类似,它也是一种演员-评论家算法,其中演员在确定性目标策略上进行训练,评论家预测Q值。为了减少方差并提高稳定性,DDPG使用了经验回放和目标网络。此外,根据OpenAI的建议,通过参数空间噪声(而非传统的动作空间噪声)来鼓励探索。
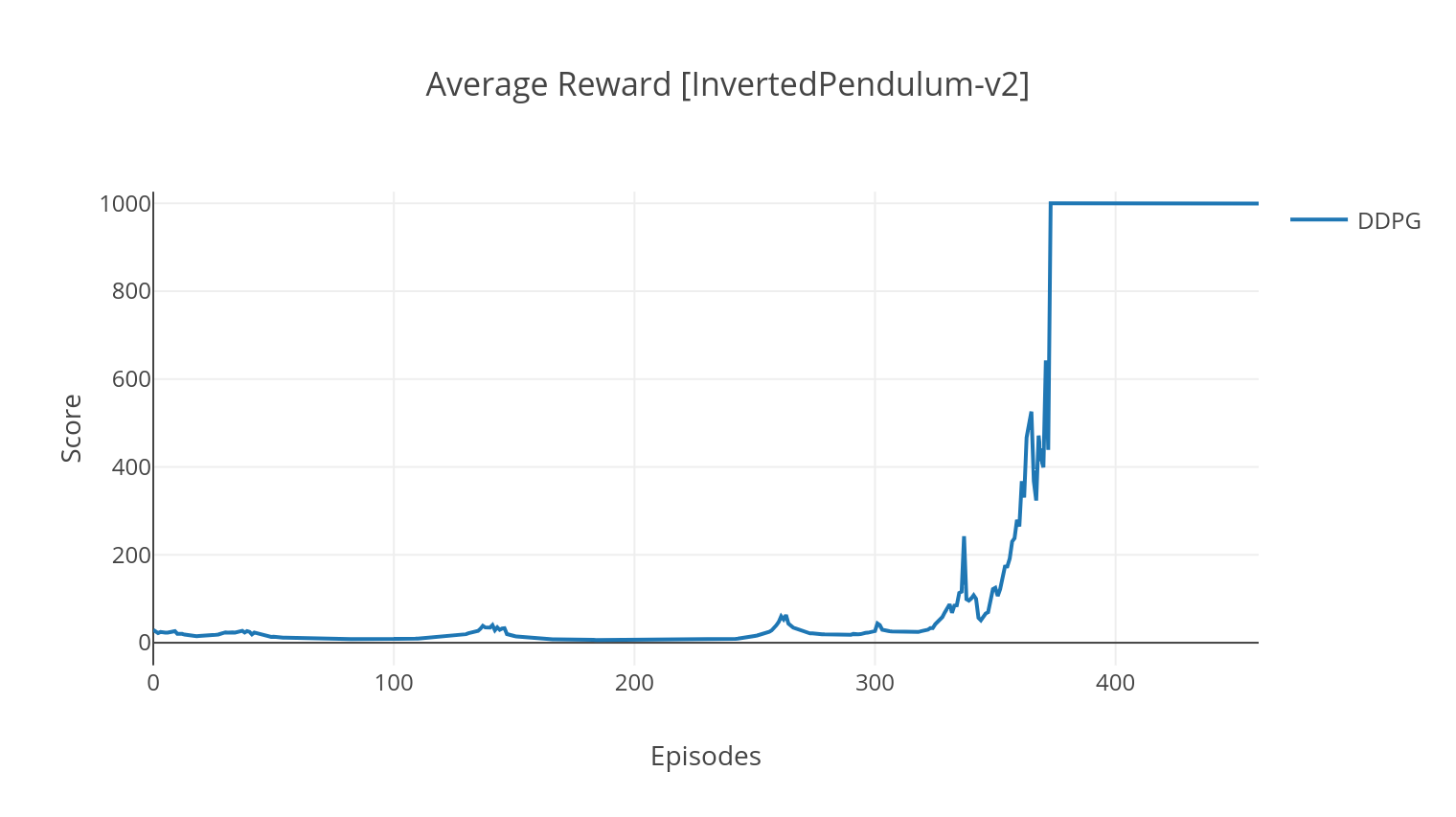
DDQN(Double Deep Q-Network)
DQN算法是一种Q学习算法,使用深度神经网络作为Q值函数的近似器。它通过贝尔曼方程估计目标Q值,并通过ε-贪婪策略收集经验。为了提高稳定性,DQN随机采样过去的经验(经验回放)。
DDQN是DQN的一个变体。为了更准确地估计Q值,DDQN使用第二个网络来缓解原始网络对Q值的过高估计。这个目标网络以较慢的速率τ在每个训练步骤中更新。
DDQN+PER(Prioritized Experience Replay)
通过加入优先经验回放(PER),我们可以进一步改进DDQN算法。PER旨在对收集的经验进行重要性采样。经验按其TD误差排序,并存储在SumTree结构中,这允许高效检索具有最高误差的(s, a, r, s')转换。
Dueling DDQN
在DQN的对偶变体中,我们在Q网络中加入一个中间层来同时估计状态值和状态依赖的优势函数。经过重新表述,我们可以将估计的Q值表示为状态值加上优势估计减去其平均值。这种状态独立值和状态依赖值的分解有助于解开跨动作的学习,并产生更好的结果。
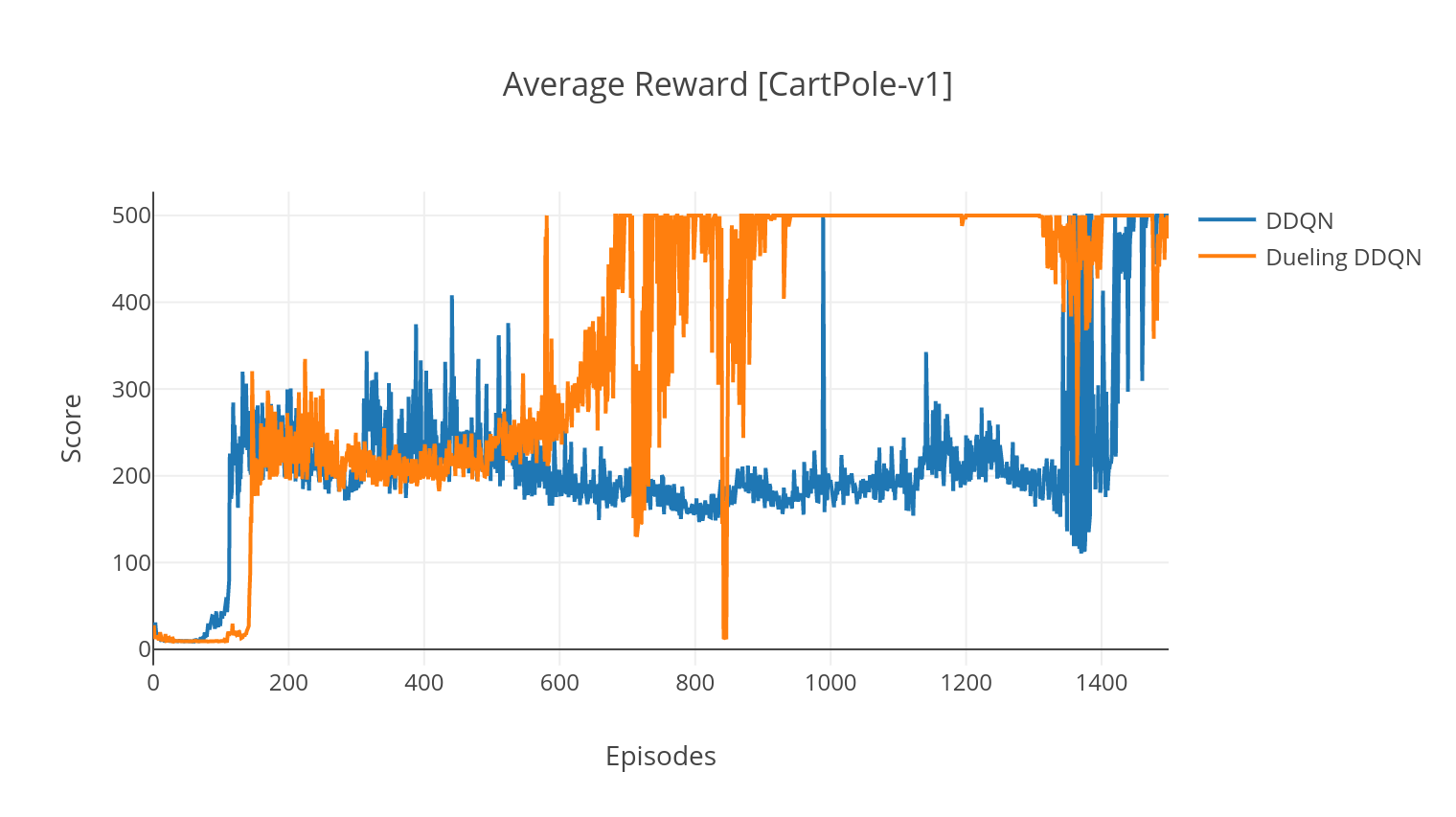
使用方法
Deep-RL-Keras提供了简单的命令行接口来运行各种算法。以下是一些示例命令:
# 运行A2C算法
python3 main.py --type A2C --env CartPole-v1
# 运行A3C算法
python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
# 运行DDPG算法
python3 main.py --type DDPG --env LunarLanderContinuous-v2
# 运行DDQN算法
python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
# 运行带PER的DDQN算法
python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
# 运行Dueling DDQN算法
python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling
可视化与监控
Deep-RL-Keras提供了多种可视化和监控工具,帮助研究人员更好地理解和分析算法的性能。
模型可视化
所有模型在训练完成后都保存在<algorithm_folder>/models/目录下。你可以通过运行load_and_run.py脚本在相同的环境中可视化它们的运行情况。
Tensorboard监控
使用Tensorboard,你可以监控agent在训练过程中的得分。训练时,会创建一个与所选环境名称匹配的日志文件夹。例如,要跟踪A2C在CartPole-v1环境上的进展,只需运行:
tensorboard --logdir=A2C/tensorboard_CartPole-v1/
结果绘图
当使用--gather_stats参数进行训练时,会生成一个包含每个episode平均得分的日志文件logs.csv。使用plotly,你可以可视化每个episode的平均奖励。
总结
Deep-RL-Keras为深度强化学习研究提供了一个强大而灵活的工具。通过实现多种经典算法并提供易用的接口,它使研究人员能够快速实验不同的算法和环境。该项目的模块化设计也使得扩展新算法变得简单。无论你是深度强化学习的新手还是经验丰富的研究者,Deep-RL-Keras都是一个值得尝试的优秀工具。
参考文献
- Advantage Actor Critic (A2C)
- Asynchronous Advantage Actor Critic (A3C)
- Deep Deterministic Policy Gradient (DDPG)
- Deep Q-Learning (DQN)
- Double Q-Learning (DDQN)
- Prioritized Experience Replay (PER)
- Dueling Network Architectures (D3QN)
通过Deep-RL-Keras,研究人员和开发者可以更便捷地实现和比较这些经典算法,推动深度强化学习领域的进一步发展。无论你是想复现已有的研究结果,还是开发新的算法,Deep-RL-Keras都是一个值得尝试的强大工具。



















