
Distill-SD:压缩版Stable Diffusion模型
Stable Diffusion作为一种强大的文本到图像生成模型,已在AI艺术创作领域掀起了一场革命。然而,它庞大的模型规模也带来了一些挑战,如高计算资源需求和较慢的推理速度。为了解决这些问题,Segmind团队开发了Distill-SD项目,旨在通过知识蒸馏技术创建更小更快的Stable Diffusion模型。
知识蒸馏:教师引导学生
知识蒸馏是一种模型压缩技术,可以将大型"教师"模型的知识转移到更小的"学生"模型中。在Distill-SD中,研究人员使用了SG161222/Realistic_Vision_V4.0的U-Net作为教师模型,并在LAION-art数据集的子集上训练了更小的学生模型。
训练过程中,最终的损失函数由三部分组成:
- 教师U-Net和学生U-Net预测噪声之间的均方误差损失
- 实际添加的噪声和预测噪声之间的均方误差损失
- 教师和学生U-Net每个模块输出之间的均方误差损失之和
通过这种方式,学生模型不仅学习到了最终输出,还学习了中间特征表示,从而更好地模仿教师模型的行为。
模型架构:瘦身不失功力
Distill-SD项目提供了两种压缩模型:
- SD-Small: 参数量为579,384,964,相比原始Stable Diffusion减少了约33%
- SD-Tiny: 参数量为323,384,964,相比原始模型减少了约62%

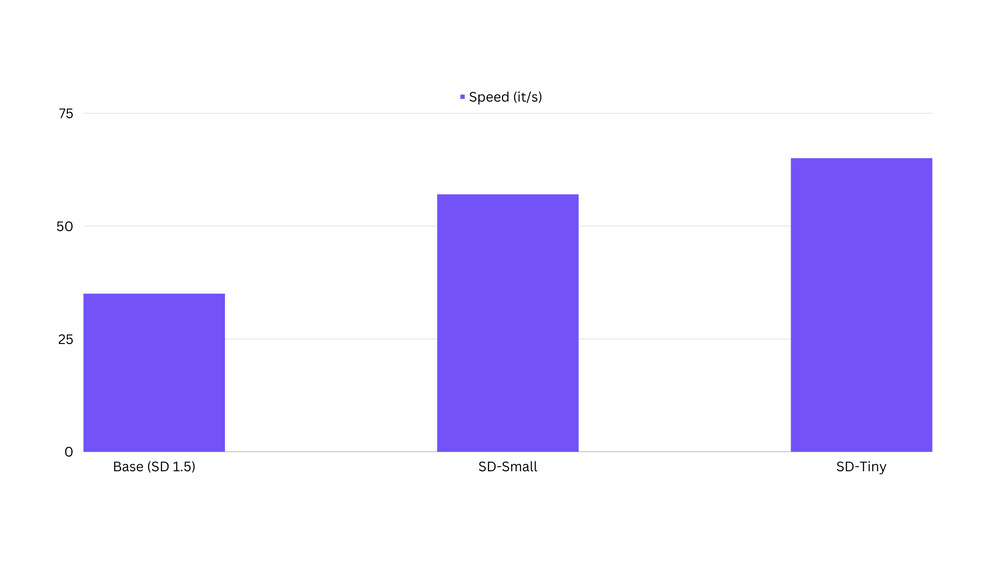
这种大幅减少的参数量带来了显著的性能提升。在NVIDIA A100 80GB GPU上进行推理测试,结果令人印象深刻:
- SD-Small: 比原始模型快约50%
- SD-Tiny: 比原始模型快约100%
使用Distill-SD:简单快速
使用Distill-SD非常简单,只需几行Python代码即可生成图像:
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from torch import Generator
path = 'segmind/small-sd' # 选择合适的模型类型
prompt = "一个美丽的夏日风景"
negative_prompt = "低质量,模糊,扭曲"
with torch.inference_mode():
pipe = DiffusionPipeline.from_pretrained(path, torch_dtype=torch.float16)
pipe.to('cuda')
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
img = pipe(prompt=prompt, negative_prompt=negative_prompt,
width=512, height=512, num_inference_steps=25).images[0]
img.save("summer_landscape.png")
预训练模型:即取即用
Distill-SD项目提供了多个预训练模型,可以直接使用或进行进一步微调:
这些模型在各种场景下都表现出色。例如,使用人像微调的SD-Tiny模型生成的图像质量令人惊叹:

优势与局限性
Distill-SD的主要优势包括:
- 推理速度提升高达100%
- VRAM占用减少30%
- 更快的Dreambooth和LoRA训练
然而,该项目仍处于早期阶段,存在一些局限性:
- 输出质量可能尚未达到生产级别
- 不适合作为通用模型,最好用于特定概念/风格的微调或LoRA训练
- 在可组合性和多概念处理方面有待改进
未来研究方向
Distill-SD团队规划了一系列激动人心的研究方向:
- SDXL压缩模型及代码
- 进一步微调SD-1.5基础模型,提高可组合性和泛化能力
- 应用Flash Attention-2加速训练/微调
- 使用TensorRT和/或AITemplate进行进一步加速
- 在蒸馏过程中探索量化感知训练(QAT)
结语
Distill-SD项目为Stable Diffusion模型的轻量化和加速提供了一种创新方案。通过知识蒸馏技术,研究人员成功地将庞大的Stable Diffusion压缩成更小更快的版本,同时保持了令人印象深刻的图像生成能力。这不仅降低了使用门槛,还为在资源受限的设备上部署高质量图像生成模型开辟了新的可能性。
随着研究的深入和技术的不断优化,我们可以期待看到更多令人兴奋的进展。Distill-SD无疑为AI艺术创作和图像生成领域注入了新的活力,让我们拭目以待它在未来会带来怎样的惊喜。
如果你对Distill-SD项目感兴趣,可以访问其GitHub仓库了解更多详情,或加入他们的Discord社区参与讨论。让我们一起见证AI图像生成技术的又一次飞跃!


















