
引言
随着人工智能技术的快速发展,大语言模型(LLM)已经成为了自然语言处理领域的重要工具。然而,运行这些庞大的模型通常需要强大的GPU支持,这对于许多个人用户和小型团队来说可能是一个巨大的障碍。本文将探讨如何在普通CPU上运行Llama 2和其他开源LLM,以实现高效的本地文档问答功能。
背景与挑战
近年来,像OpenAI的GPT-4这样的第三方商业LLM提供商通过简单的API调用使LLM的使用变得更加普及。然而,出于数据隐私和合规性等原因,许多团队需要自主管理或私有部署模型。开源LLM的兴起为我们提供了更多选择,减少了对这些第三方提供商的依赖。
当我们在本地或云端部署开源LLM时,计算资源成为一个关键问题。虽然GPU实例看似是显而易见的选择,但成本可能会迅速超出预算。因此,我们需要探索如何在CPU上运行量化版的开源LLM,以实现高效的本地文档问答功能。
技术方案概述
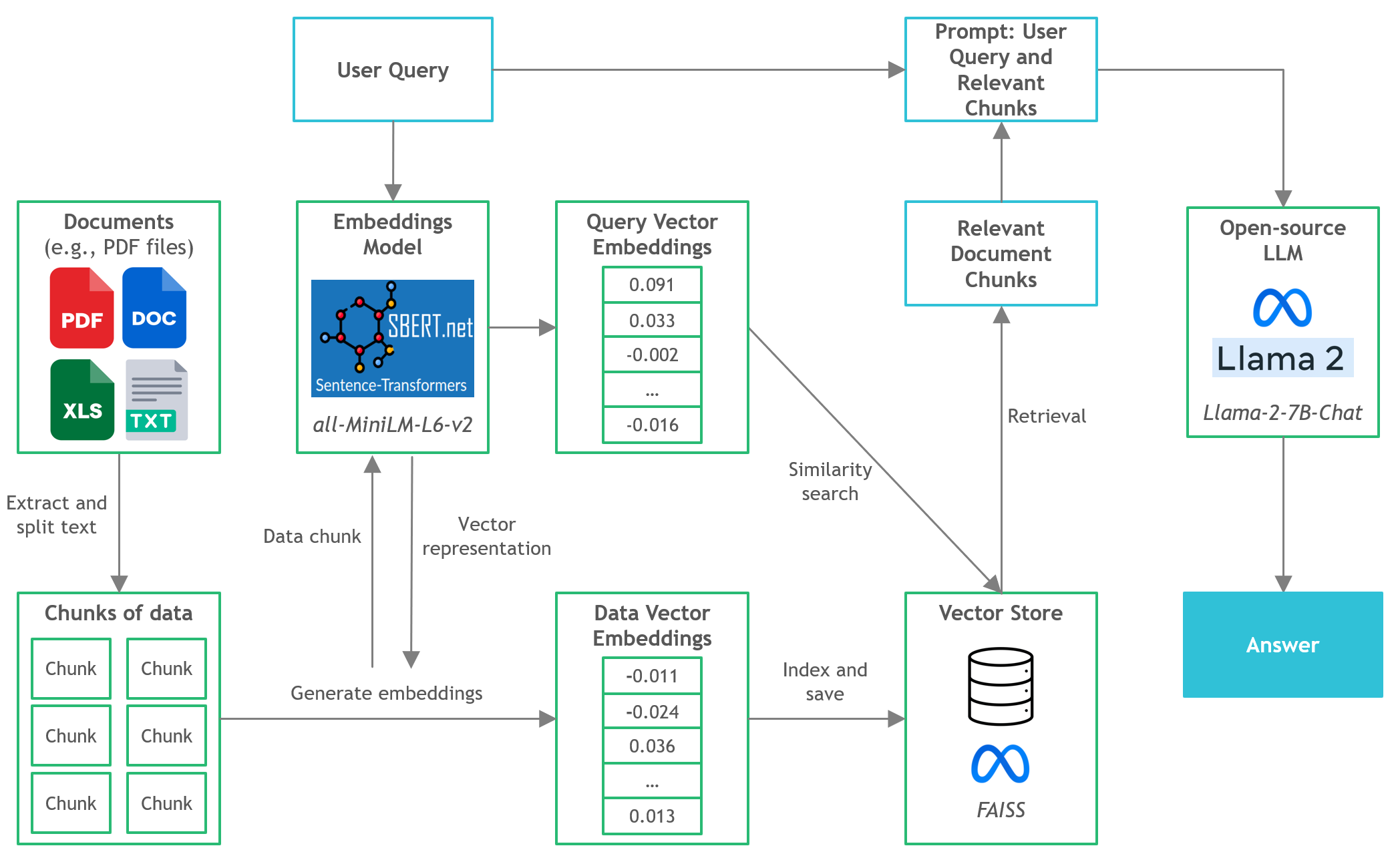
本项目采用了以下核心技术和工具:
-
Llama-2-7B-Chat: 这是一个开源的微调Llama 2模型,专为聊天对话设计。它利用了公开可用的指令数据集和超过100万人工标注。
-
LangChain: 这是一个用于开发由语言模型驱动的应用程序的框架。
-
C Transformers: 这是使用GGML库在C/C++中实现的Transformer模型的Python绑定。
-
FAISS: 这是一个开源库,用于高效的相似性搜索和密集向量聚类。
-
Sentence-Transformers (all-MiniLM-L6-v2): 这是一个开源的预训练transformer模型,用于将文本嵌入到384维密集向量空间中,适用于聚类或语义搜索等任务。
-
Poetry: 这是一个用于依赖管理和Python打包的工具。
实现步骤
-
环境准备: 首先,确保您已经从Hugging Face下载了GGML二进制文件,并将其放置在
models/文件夹中。 -
启动应用: 在项目目录下打开终端,运行以下命令来解析用户查询:
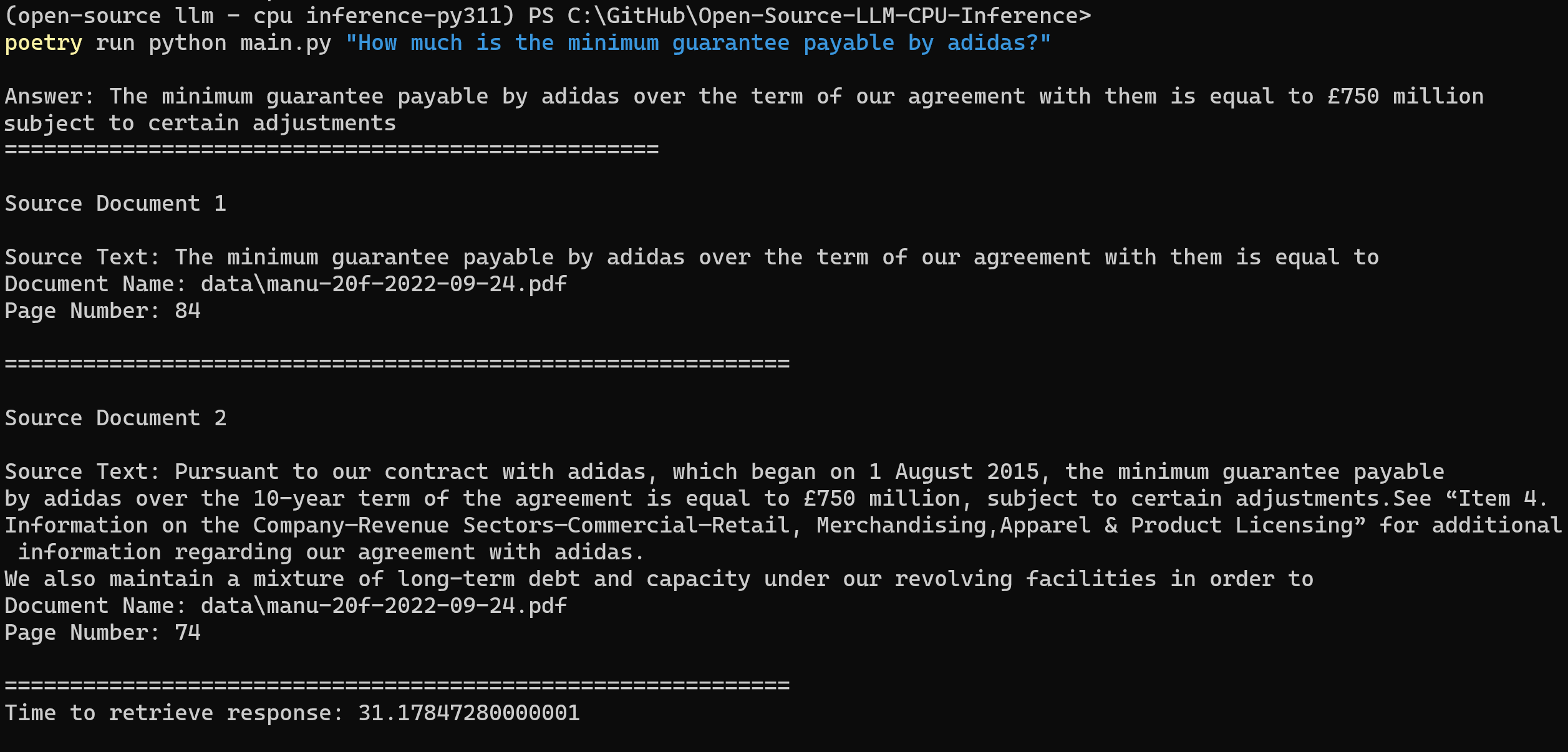
poetry run python main.py "<用户查询>"例如:
poetry run python main.py "What is the minimum guarantee payable by Adidas?"注意:如果您没有使用Poetry,请省略前面的
poetry run。 -
查看输出: 系统将处理您的查询,并返回相关的答案。
项目结构
项目的文件结构如下:
/assets: 项目相关的图片/config: LLM应用的配置文件/data: 项目使用的数据集(例如,曼联2022年年报 - 177页PDF文档)/models: GGML量化LLM模型的二进制文件(即Llama-2-7B-Chat)/src: LLM应用的关键组件的Python代码,包括llm.py,utils.py和prompts.py/vectorstore: 文档的FAISS向量存储db_build.py: 用于摄取数据集并生成FAISS向量存储的Python脚本main.py: 启动应用程序并通过命令行传递用户查询的主Python脚本pyproject.toml: 指定所使用依赖项版本的TOML文件(Poetry)requirements.txt: Python依赖项列表(及版本)
性能与优化
在CPU上运行LLM通常会面临性能挑战。然而,通过使用量化技术和优化的推理库,我们可以显著提高性能。GGML库在这方面发挥了关键作用,它提供了高效的CPU推理能力。
此外,使用FAISS进行向量搜索也大大提高了文档检索的效率。通过将文档预先编码为向量并存储在FAISS索引中,我们可以快速找到与用户查询最相关的文档片段。
应用场景
这种在CPU上运行开源LLM的方法有多种潜在应用场景:
-
个人知识管理: 用户可以对自己的文档库进行问答,无需将敏感信息上传到云端。
-
企业内部文档查询: 公司可以构建自己的文档问答系统,保护敏感信息的同时提高员工的工作效率。
-
离线环境下的AI应用: 在无法连接互联网或对隐私要求极高的环境中,这种本地运行的方式特别有价值。
-
教育和研究: 学生和研究人员可以使用这种方法来探索和学习LLM的工作原理,而无需昂贵的GPU资源。
未来展望
随着开源LLM技术的不断发展,我们可以期待在CPU上运行这些模型的效率会进一步提高。一些可能的发展方向包括:
-
更高效的量化技术: 开发能在保持模型性能的同时进一步减小模型大小的新量化方法。
-
专门针对CPU优化的模型架构: 设计更适合在CPU上运行的LLM架构。
-
改进的推理库: 进一步优化像GGML这样的库,以提高CPU上的推理速度。
-
混合计算方案: 探索如何有效地结合CPU和其他加速器(如NPU)来运行LLM。
结论
在CPU上运行Llama 2和其他开源LLM为个人用户和小型团队提供了一种经济实惠且灵活的方式来利用大语言模型的力量。通过结合量化技术、优化的推理库和高效的向量搜索,我们可以在普通硬件上实现令人印象深刻的性能。
这种方法不仅使得更多人能够接触到先进的AI技术,还为那些需要保护数据隐私或在资源受限环境中工作的用户提供了宝贵的解决方案。随着技术的不断进步,我们可以期待在未来看到更多创新和优化,使得在CPU上运行LLM变得更加高效和普及。
参考资源
- C Transformers GitHub仓库
- TheBloke的Hugging Face主页
- Llama-2-7B-Chat-GGML模型
- LangChain文档 - C Transformers集成
- GGML官方网站
- GGML GitHub文档
通过本文的详细介绍,读者应该能够理解如何在CPU上运行开源LLM,并将其应用于文档问答任务。这不仅为个人用户和小型团队提供了一种经济实惠的AI解决方案,也为进一步探索和创新LLM应用开辟了道路。













