
Llama-2-Open-Source-LLM-CPU-Inference项目简介
Llama-2-Open-Source-LLM-CPU-Inference是一个开源项目,旨在演示如何在CPU上运行Llama 2等开源大语言模型(LLM)进行文档问答。该项目由Kenneth Leung开发,提供了一个清晰的指南,介绍如何使用量化版本的开源LLM在本地CPU上进行推理。
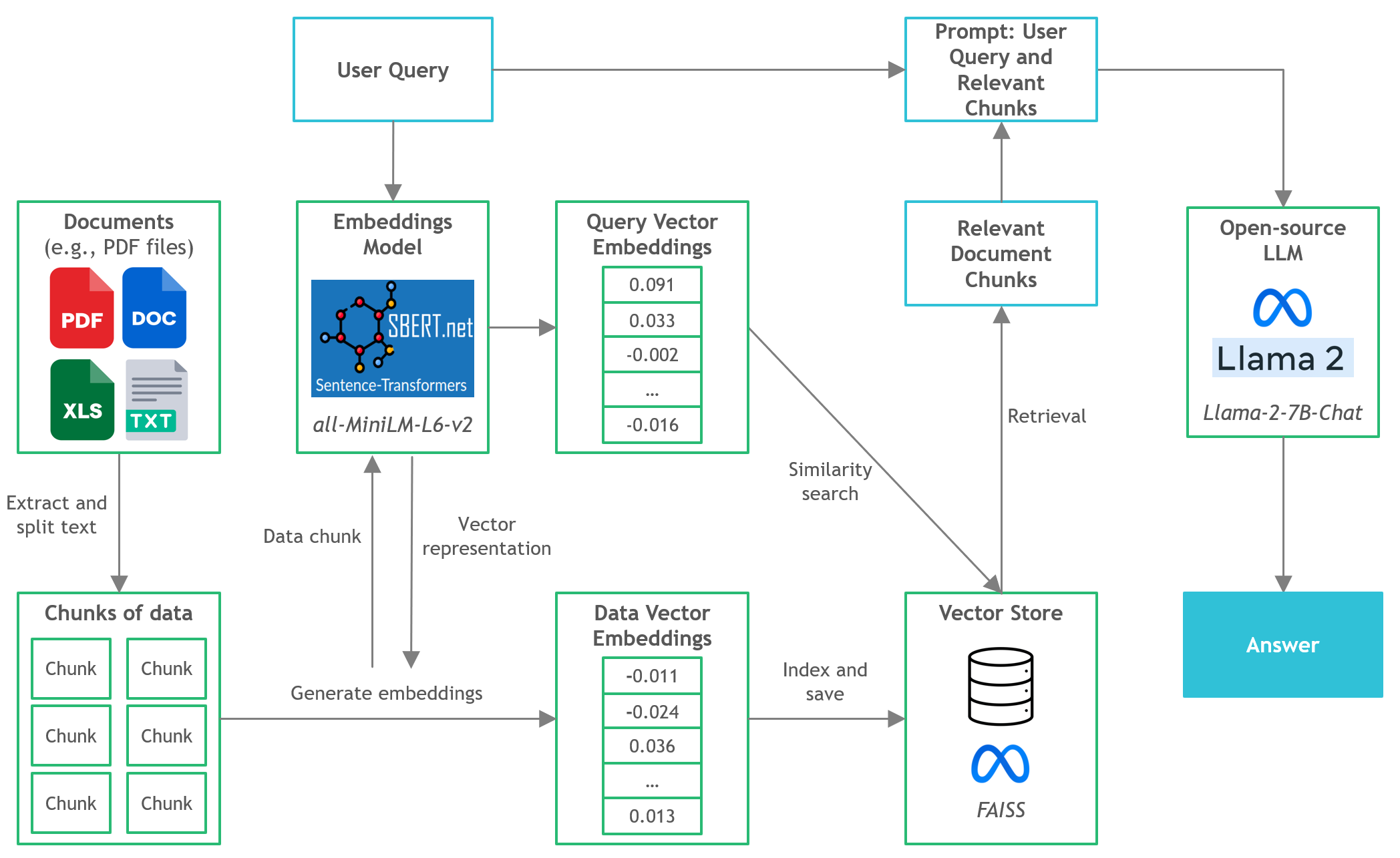
核心技术栈
- LangChain: 用于开发基于语言模型的应用程序的框架
- C Transformers: 使用GGML库在C/C++中实现Transformer模型的Python绑定
- FAISS: 用于高效相似性搜索和聚类的开源库
- Sentence-Transformers (all-MiniLM-L6-v2): 用于文本嵌入的预训练transformer模型
- Llama-2-7B-Chat: 针对对话进行微调的开源Llama 2模型
- Poetry: 用于依赖管理和Python打包的工具
快速开始指南
-
从Hugging Face下载GGML二进制文件并放入
models/文件夹 -
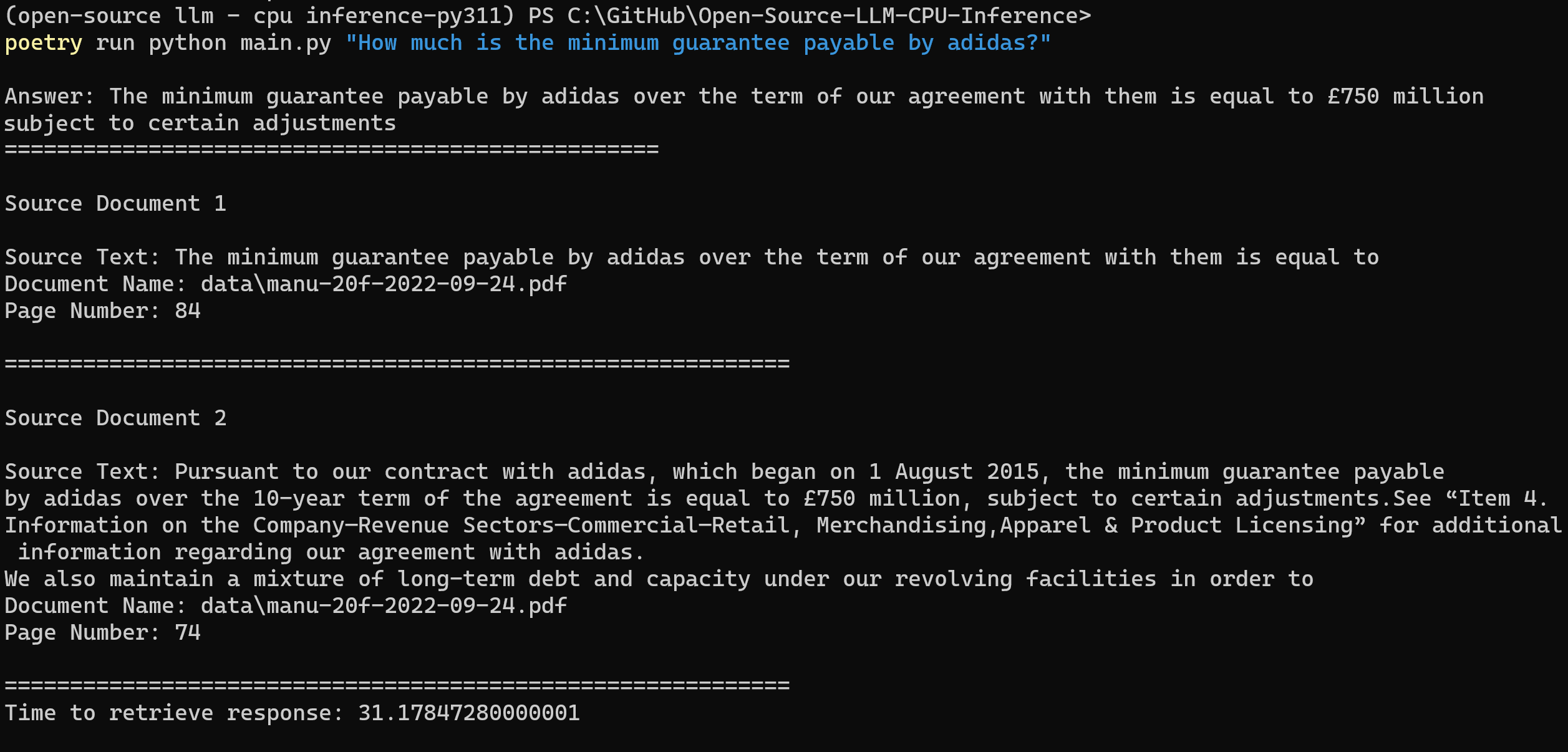
在项目目录下运行以下命令来解析用户查询:
poetry run python main.py "<用户查询>"例如:
poetry run python main.py "What is the minimum guarantee payable by Adidas?" -
如果不使用Poetry,可以省略
poetry run前缀
项目结构
/assets: 项目相关图片/config: LLM应用配置文件/data: 项目使用的数据集(曼联2022年年报PDF文档)/models: GGML量化LLM模型二进制文件/src: LLM应用核心组件Python代码/vectorstore: 文档FAISS向量存储db_build.py: 用于摄取数据集并生成FAISS向量存储的Python脚本main.py: 用于启动应用程序并通过命令行传递用户查询的主Python脚本
学习资源
通过本项目,读者可以学习如何在CPU上运行开源大语言模型,实现本地文档问答系统,这对于需要自主管理模型部署或遵守数据隐私规定的团队来说尤其有价值。项目不仅提供了实用的代码实现,还详细解释了相关概念和技术,是学习大语言模型应用开发的优秀资源。













